




今天有朋友在群里问了一段关于 Prometheus hashmod 配置的问题,如图:
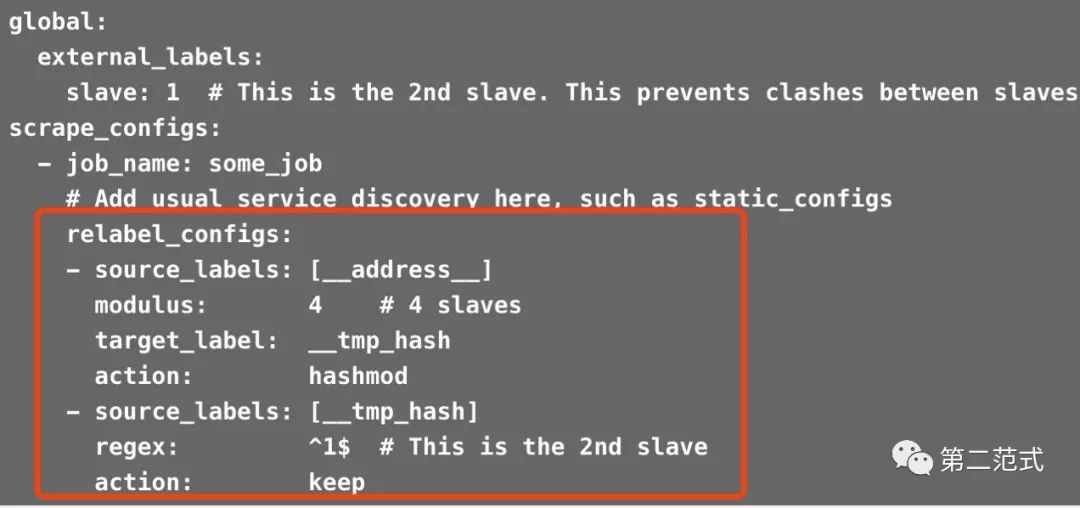
此配置出自 Brian 的博客 scaling-and-federating-prometheus。
这段配置到底是什么意思?因为以前没用过这个配置,所以只好去翻看源码。
核心源码解读
阅读的过程中,发现 relabel.go#L41 开始的代码与配置很相关:
func relabel(lset labels.Labels, cfg *config.RelabelConfig) labels.Labels {
values := make([]string, 0, len(cfg.SourceLabels))
for _, ln := range cfg.SourceLabels {
values = append(values, lset.Get(string(ln)))
}
val := strings.Join(values, cfg.Separator)
lb := labels.NewBuilder(lset)
switch cfg.Action {
// 此处省略代码
// 判断值是否匹配,如果不匹配那么将放弃此 target
case config.RelabelKeep:
if !cfg.Regex.MatchString(val) {
return nil
}
// 对字段 source_labels 的值进行 md5 和取余,并将结果存到自定义目标字段中
case config.RelabelHashMod:
mod := sum64(md5.Sum([]byte(val))) % cfg.Modulus
lb.Set(cfg.TargetLabel, fmt.Sprintf("%d", mod))
// 此处省略代码
default:
panic(fmt.Errorf("relabel: unknown relabel action type %q", cfg.Action))
}
return lb.Labels()
}
有了代码参考,一开始的配置就容易理解了,它的逻辑为:
配置的第一个 souce_labels 是对同一个任务抓取目标的 LabelSet 进行预处理,具体而言就是将抓取目标地址进行 hashmod, 并将 hashmod 的值存到一个自定义字段
__tmp_hash
中。配置的第二个
souce_labels
对预处理后的抓取目标进行筛选,只选取__tmp_hash
值满足正则匹配的,例子中 hashmod != 1 将全部被忽略。
通过以上两步,就非常容易对相同任务的抓取目标进行散列,只抓取命中的部分。
散列均衡性测试
抓取目标的散列是否足够均衡呢?
下面是根据 Prometheus 的 mod 计算方法编写的一段测试代码:
package main
import (
"crypto/md5"
"fmt"
)
func main() {
nodes := []string{
"192.168.1.1:9090", "192.168.1.2:9090", "192.168.1.3:9090", "192.168.1.4:9090", "192.168.1.5:9090",
"192.168.1.6:9090", "192.168.1.7:9090", "192.168.1.8:9090", "192.168.1.9:9090", "192.168.1.10:9090",
}
for _, ip := range nodes {
mod := sum64(md5.Sum([]byte(ip))) % 3
fmt.Printf("%s mode is %d \n", ip, mod)
}
}
func sum64(hash [md5.Size]byte) uint64 {
var s uint64
for i, b := range hash {
shift := uint64((md5.Size - i - 1) * 8)
s |= uint64(b) << shift
}
return s
}
输出结果为:
192.168.1.1:9090 mode is 3
192.168.1.2:9090 mode is 1
192.168.1.3:9090 mode is 0
192.168.1.4:9090 mode is 0
192.168.1.5:9090 mode is 1
192.168.1.6:9090 mode is 2
192.168.1.7:9090 mode is 3
192.168.1.8:9090 mode is 1
192.168.1.9:9090 mode is 1
192.168.1.10:9090 mode is 1
可以看到,当目标地址足够多的时候,还是能够满足均匀散列。
配置的意义
以前在文章 Prometheus 集群方案之 remote read 实战 中已经介绍过按照业务将 Prometheus server 拆分成的思路,即便如此,有些数据(比如一个机房的所有机器信息)还是特别大,超过了单机承载能力。
此时我们可以采用 hashmod
配置,使用同样的配置列表,将抓取目标散列到不同的 Prometheus server 中去, 从而很好实现 Prometheus 数据收集的横向扩展。
