




我们当前将监控细分为如下4块:
1、指标监控
2、调用链监控
3、日志监控
4、健康检查
因此,监控选型主要依据此分类方式进行解释。
1、指标监控
我们主要讲prometheus和zabbix之间区别。
综合对比如下:
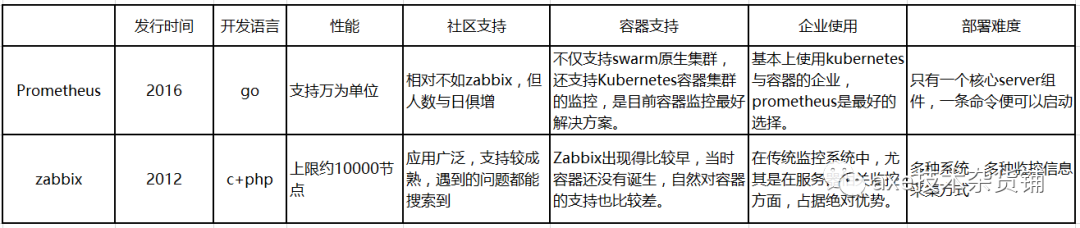
架构方面:
Prometheus的基本原理是通过HTTP周期性抓取被监控组件的状态,任意组件只要提供对应的HTTP接口并且符合Prometheus定义的数据格式,就可以接入Prometheus监控。
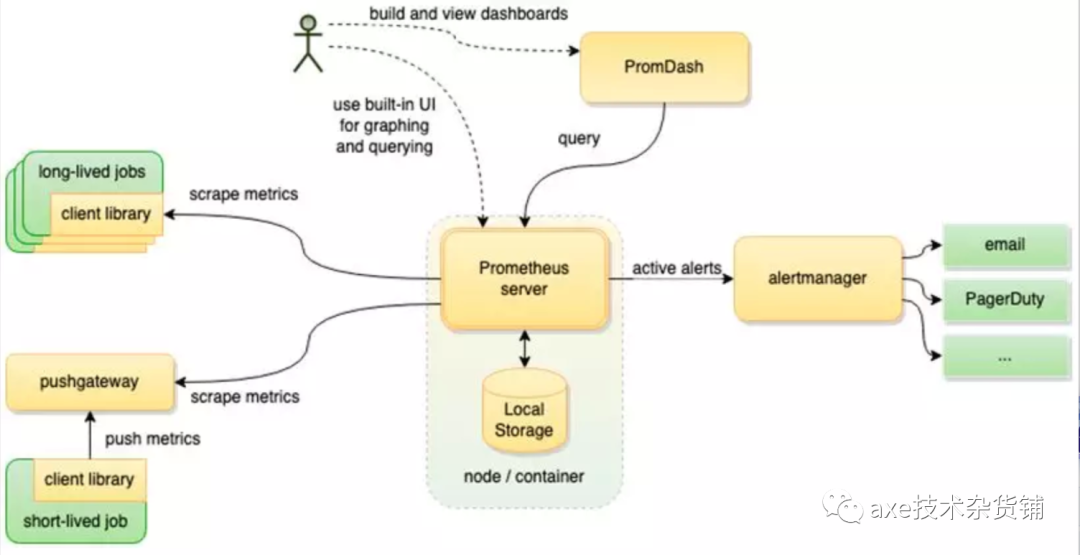
Zabbix由2部分构成,zabbix server与可选组件zabbix agent。zabbix server可以通过SNMP,zabbix agent,ping,端口监视等方法提供对远程服务器/网络状态的监视,数据收集等功能,它可以运行在Linux,Solaris,HP-UX,AIX,Free BSD,Open BSD,OS X等平台上。
如果监控的是物理机,用 Zabbix 没毛病,Zabbix在传统监控系统中,尤其是在服务器相关监控方面,占据绝对优势。甚至环境变动不会很频繁的情况下,Zabbix 也会比 Prometheus 好使;但如果是云环境的话,除非是 Zabbix 玩的非常溜,可以做各种定制,否则还是 Prometheus 吧,毕竟人家就是干这个的。Prometheus开始成为主导及容器监控方面的标配,并且在未来可见的时间内被广泛应用。如果是刚刚要上监控系统的话,不用犹豫了,Prometheus 准没错。
2、调用链监控
主要是为了解决当前复杂的分布式服务场景下定位问题、性能瓶颈查询、异常日志跟踪等各类问题
调用链监控主要使用第三方的监控软件,常用的有 skywalking、zikpin、pinpoint、Cat等,主要对比如下:
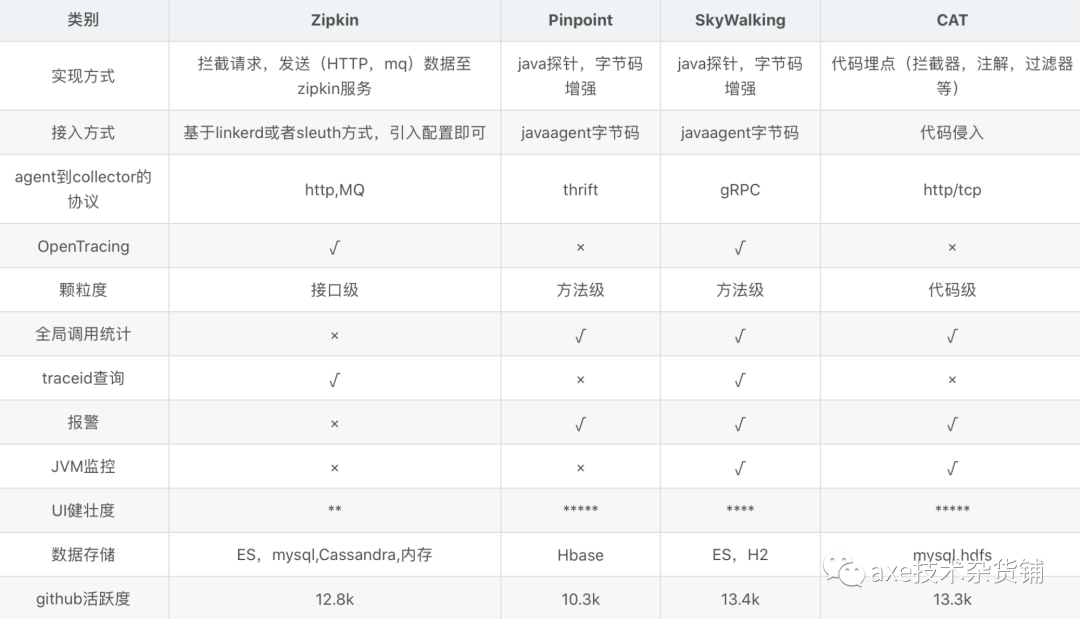
CAT
CAT是由大众点评开源的一款调用链监控系统,基于JAVA开发的。有很多互联网企业在使用,热度非常高。它有一个非常强大和丰富的可视化报表界面,这一点其实对于一款调用链监控系统而来非常的重要。在CAT提供的报表界面中有非常多的功能,几乎能看到你想要的任何维度的报表数据。
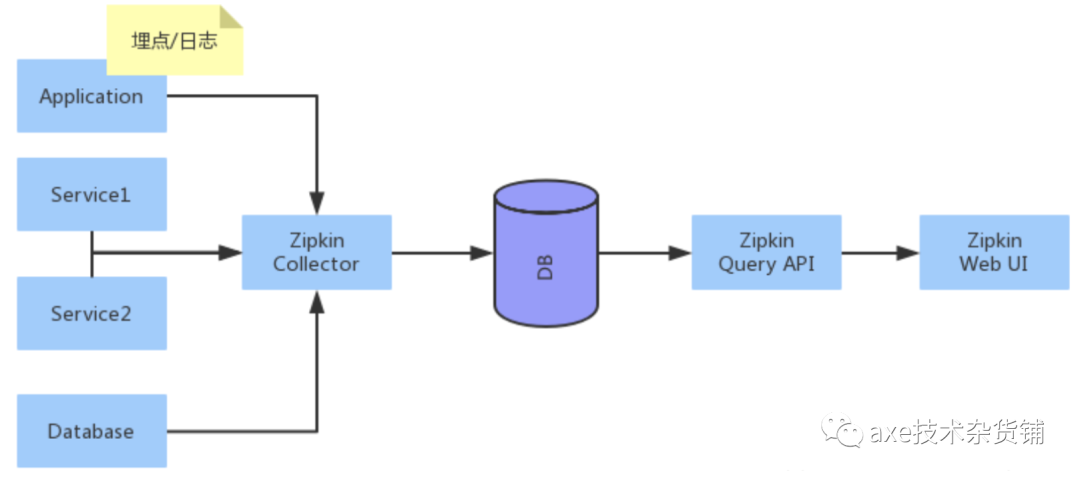
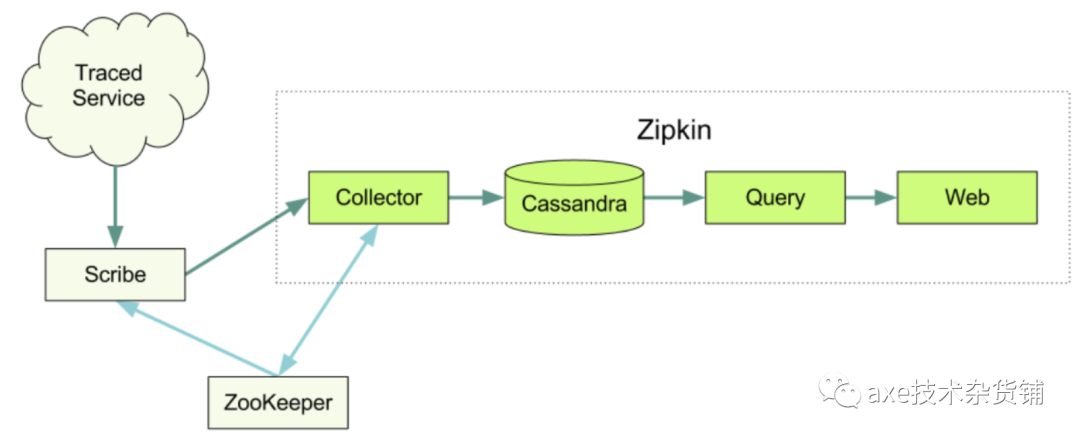
Zipkin
Twitter的zipkin,其中zipkin是严格按照来Dapper论文来设计的,他提供了完整的跟踪记录收集、存储功能,以及查询API与界面。其存储支持多种数据库:MySql、ElasticSearch、Cassandra、Redis等等,收集API支持HTTP和Thrift。
Pinpoint
Pinpoint 是用 Java 编写的 APM(应用性能管理)工具,用于大规模分布式系统。在 Dapper 之后,Pinpoint 提供了一个解决方案,以帮助分析系统的总体结构以及分布式应用程序的组件之间是如何进行数据互联的。
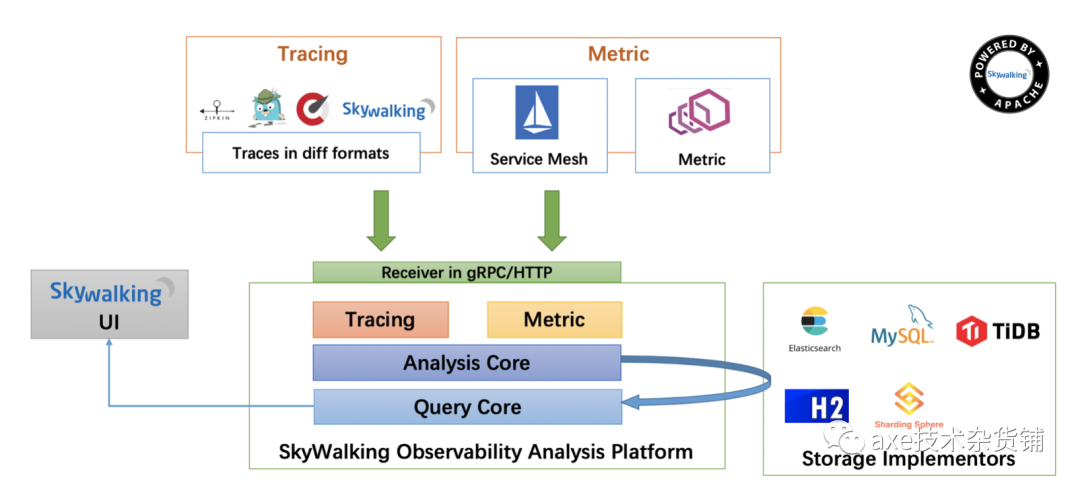
Skywalking
一个开源的可观测平台, 用于从服务和云原生基础设施收集, 分析, 聚合及可视化数据。SkyWalking 提供了一种简便的方式来清晰地观测分布式系统, 甚至横跨多个云平台。SkyWalking 更是一个现代化的应用程序性能监控(Application Performance Monitoring)系统, 尤其专为云原生、基于容器的分布式系统设计。
性能对比
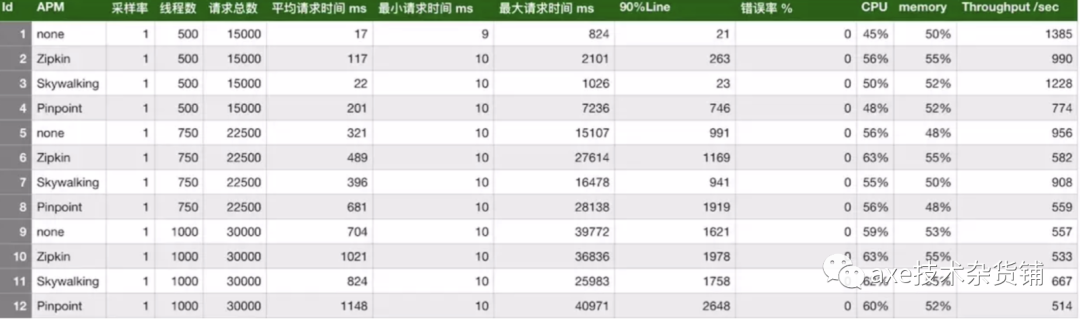
skywalking的探针对吞吐量的影响最小,zipkin的吞吐量居中。pinpoint的探针对吞吐量的影响较为明显。
3、日志监控
当前调研的日志解决方案是ELK,架构如下:

(1)用户通过nginx或haproxy访问ELK日志统计平台,IP地址为keepalived的vip地址。
(2)nginx将请求转发到kibana
(3)kibana到elasticsearch获取数据,elasticsearch是两台做的集群,数据会随机保存在任意一台elasticsearch服务器。
(4)logstash①从redis中取出数据并发送到elasticsearch中。
(5)redis服务器做数据的临时保存,避免web服务器日志量过大的时候造成的数据收集与保存不一致而导致日志丢失,其中redis可以做集群,然后再由logstash服务器在非高峰时期从redis持续的取出数据。
(6)logstash②过滤从filebeat取出的日志信息,并放入redis中进行保存。
(7)filebeat进行收集web的日志
核心为日志收集部分,下面会对Filebeat进行详细解释:
Filebeat如何工作
Filebeat包含两个主要组件:inputs(输入)和 harvester(收割机)这些组件协同工作以尾部文件并将事件数据发送到指定的输出。
harvester(收割机):harvester负责读取单个文件的内容。harvester逐行读取每个文件,然后将内容发送到输出。每个文件启动一个harvester。harvester负责打开和关闭文件,这意味着在harvester运行时文件描述符保持打开状态。如果在收集文件时将其删除或重命名,Filebeat将继续读取该文件。这样做的副作用是磁盘上的空间将保留到收割机关闭为止。默认情况下,Filebeat保持文件打开直到close_inactive
到达。
注意 关闭收割机有以下后果:
1)关闭文件处理程序,如果在收割机仍在读取文件时删除了文件,则释放了基础资源。
2)只有在scan_frequency
经过之后,才会再次开始文件的收集。
3)如果在收割机关闭时移动或删除文件,则文件的收割将不会继续。
inputs(输入):输入负责管理harvester并查找所有可读取的资源。如果输入类型为log
,则输入将在驱动器上找到与定义的全局路径匹配的所有文件,并为每个文件启动收集器。每个输入都在其自己的Go例程中运行。Filebeat当前支持类型(Azure Event Hub、Cloud Foundry、Container、Docker、Google Pub/Sub、HTTP Endpoint、HTTP JSON、Kafka、Log、MQTT、NetFlow、Office 365 Management Activity API、Redis、S3、Stdin、Syslog、TCP、UDP)。每个输入类型可以定义多次。该log
输入检查每个文件看收割机是否需要启动,一个人是否已经在运行,或文件是否可以忽略不计(见ignore_older
)。仅当自收割机关闭以来文件的大小已更改时,才会拾取新行。
Filebeat如何保持文件的状态
Filebeat保留每个文件的状态,并经常将状态刷新到注册表文件中的磁盘。该状态用于记住harvester正在读取的最后一个偏移量,并确保发送所有日志行。如果无法到达输出(例如Elasticsearch或Logstash),则Filebeat会跟踪发送的最后几行,并在输出再次可用时继续读取文件。在Filebeat运行时,状态信息也保存在内存中,用于每个输入。重新启动Filebeat时,将使用注册表文件中的数据来重建状态,并且Filebeat会在最后一个已知位置继续每个harvester。
对于每个输入,Filebeat会保持找到的每个文件的状态。由于可以重命名或移动文件,因此文件名和路径不足以标识文件。对于每个文件,Filebeat都存储唯一的标识符以检测文件是否以前被收获过。
4、健康检查
目前没有合适方案,主要依托于云平台,依靠云平台自身健康检查方式,如docker healthcheck ,该机制主要是编写dockerfile时,将检测机制写入到dockerfile中,基于此docerfile生成的镜像,在运行容器时会有健康检测的功能。
HEALTHCHECK 支持下列选项:
--interval=<间隔>:两次健康检查的间隔,默认为 30 秒;
--timeout=<时长>:健康检查命令运行超时时间,如果超过这个时间,本次健康检查就被视为失败,默认 30 秒;
--retries=<次数>:当连续失败指定次数后,则将容器状态视为 unhealthy,默认 3 次。
