






部署前该考虑的事项:
1、是否需要将监控和业务服务分开,可以给node打标签,让Prometheus,alertmanager,grafana都部署到同一台机器上
2、监控数据的持久化(PV)是静态还是动态?一般建议动态StorageClass。阿里云环境下可以使用阿里云nas或者云盘来存储。提前创建好持久化存储
一、prometheus-operator相关介绍
Operator是由CoreOS公司开发的用来扩展Kubernetes API的特定应用程序控制器,用来创建、配置和管理复杂的有状态应用,例如Mysql、缓存和监控系统。目前CoreOS官方提供了几种Operator的代码实现,其中就包括Prometheus Operator
架构图如下:
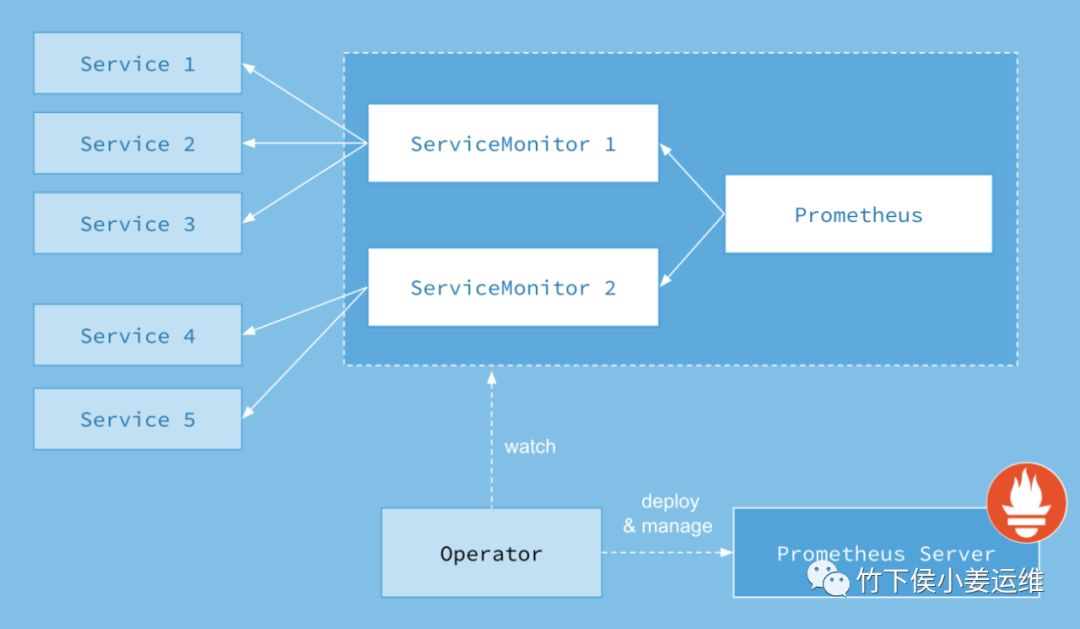
Operator作为一个核心的控制器,它会创建Prometheus、ServiceMonitor、alertmanager以及我们的prometheus-rule这四个资源对象,operator会一直监控并维持这四个资源对象的状态,其中创建Prometheus资源对象就是作为Prometheus Server进行监控,而ServiceMonitor就是我们用的exporter的各种抽象(exporter就是提供我们各种服务的metrics的工具)Prometheus就是通过ServiceMonitor提供的metrics数据接口把我们数据pull过来的。现在我们监控prometheus不需要每个服务单独创建修改规则。通过直接管理Operator来进行集群的监控。这里还要说一下,一个ServiceMonitor可以通过我们的label标签去匹配集群内部的service,而我们的prometheus也可以通过label匹配多个ServiceMonitor
其中,Operator是核心部分,作为一个控制器而存在,Operator会创建Prometheus、ServiceMonitor、AlertManager及PrometheusRule这4个CRD资源对象,然后一直监控并维持这4个CRD资源对象的状态
Prometheus 资源对象是作为Prometheus Service存在的
ServiceMonitor 资源对象是专门提供metrics数据接口的exporter的抽象,Prometheus就是通过ServiceMonitor提供的metrics数据接口去 pull 数据的
AlerManager 资源对象是对应alertmanager组件
PrometheusRule 资源对象是被Prometheus实例使用的告警规则文件
CRD简介
全称CustomResourceDefinition,在Kubernetes中一切都可视为资源,在Kubernetes1.7之后增加对CRD自定义资源二次开发能力开扩展Kubernetes API,当我们创建一个新的CRD时,Kubernetes API服务器将为你制定的每个版本创建一个新的RESTful资源路径,我们可以根据该API路径来创建一些我们自己定义的类型资源。CRD可以是命名空间,也可以是集群范围。由CRD的作用域scpoe字段中所制定的,与现有的内置对象一样,删除名称空间将删除该名称中的所有自定义对象
简单的来说CRD是对Kubernetes API的扩展,Kubernetes中的每个资源都是一个API对象的集合,例如yaml文件中定义spec那样,都是对Kubernetes中资源对象的定义,所有的自定义资源可以跟Kubernetes中内建的资源一样使用Kubectl
这样,在集群中监控数据,就变成Kubernetes直接去监控资源对象,Service和ServiceMonitor都是Kubernetes的资源对象,一个ServiceMonitor可以通过labelSelector匹配一类Service,Prometheus也可以通过labelSelector匹配多个ServiceMonitor,并且Prometheus和AlertManager都是自动感知监控告警配置的变化,不需要认为进行reload操作
二、prometheus-operator安装
由于国内网络问题,有一些镜像无法直接下载。我这里提供了所有的镜像,只要导入进去即可
如果后期这个镜像包丢失,可以grep过滤出yaml中用到的镜像,用一台非大陆机器安装docker去拉镜像在保存下来
#我这里k8s所有节点都已经做了免密,直接拷贝镜像地址在所有的服务器上load一下即可# 执行以下脚本将镜像文件传输到K8s集群每个节点并load镜像,可能稍微有点慢# 由于我这个镜像文件里面包含了当前yaml里面所有需要的镜像,所以导入即可使用。# 当然我自己也保存了一份yaml在本地电脑上for i in k8s-master k8s-node1 k8s-node2;doecho "----- $i -----"scp allenjol-prometheus-operator-images.tar root@$i:/usr/local/src/ssh root@$i "docker load -i /usr/local/src/allenjol-prometheus-operator-images.tar"done
由于prometheus-operator分支已经被独立出来,所以我们下载源文件:
git clone https://github.com/coreos/kube-prometheus.git
其中kube-prometheus/manifests/setup下是CRD对象,需要先被创建:
cd kube-prometheus/manifestskubectl apply -f setup/
然后回到上层目录创建清单文件:
cd kube-prometheus/manifests/kubectl apply -f .
其实上面的配置文件是有先后顺序的,需要先创建monitoring这个namespace。可以看到setup下有一个namespaces的yaml文件并且以0开头,所以创建的时候我看到他是第一个创建了ns。这样其他资源才能在这个ns中被创建
清单文件里,其中prometheus-serviceMonitorKubelet.yaml 这个文件是用来收集我们service的metrics数据的。这里不对这个文件做任何修改,但是说明一下这个文件中几个地方:
...namespaceSelector: # 匹配命名空间,这个代表的意思就是会去匹配kube-system命名空间下,具有k8s-app=kubelet的标签,会将匹配的标签纳入我们prometheus监控中matchNames:- kube-systemselector: # 这三行是用来匹配我们的servicematchLabels:k8s-app: kubelet
查看创建完的CRD资源对象。yaml文件会自动帮我们创建crd文件。只有我们创建了crd文件,我们的serviceMonitor才会有用
[root@k8s-master manifests]# kubectl get crd | grep coreosalertmanagers.monitoring.coreos.com 2020-03-04T07:54:13Zpodmonitors.monitoring.coreos.com 2020-03-04T07:54:14Zprometheuses.monitoring.coreos.com 2020-03-04T07:54:14Zprometheusrules.monitoring.coreos.com 2020-03-04T07:54:14Zservicemonitors.monitoring.coreos.com 2020-03-04T07:54:14Zthanosrulers.monitoring.coreos.com 2020-03-04T07:54:15Z
查看创建的Pod
[root@k8s-master manifests]# kubectl get pod -n monitoringNAME READY STATUS RESTARTS AGEalertmanager-main-0 2/2 Running 0 26salertmanager-main-1 2/2 Running 0 26salertmanager-main-2 2/2 Running 0 26sgrafana-697c9fc764-bxlh2 1/1 Running 0 29skube-state-metrics-5b667f584-k8fm6 1/1 Running 0 29snode-exporter-4hwqq 2/2 Running 0 28snode-exporter-frwvl 2/2 Running 0 28snode-exporter-vnf2f 2/2 Running 0 28sprometheus-adapter-68698bc948-mftfx 1/1 Running 0 28sprometheus-k8s-0 3/3 Running 1 15sprometheus-k8s-1 3/3 Running 1 15sprometheus-operator-7457c79db5-q4jx6 1/1 Running 0 37s
查看创建的svc
[root@k8s-master manifests]# kubectl get svc -n monitoringNAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGEalertmanager-main ClusterIP 10.68.58.222 <none> 9093/TCP 53salertmanager-operated ClusterIP None <none> 9093/TCP,9094/TCP,9094/UDP 46sgrafana ClusterIP 10.68.41.2 <none> 3000/TCP 50skube-state-metrics ClusterIP None <none> 8080/TCP,8081/TCP 50snode-exporter ClusterIP None <none> 9100/TCP 49sprometheus-adapter ClusterIP 10.68.131.211 <none> 443/TCP 49sprometheus-k8s ClusterIP 10.68.145.61 <none> 9090/TCP 47sprometheus-operated ClusterIP None <none> 9090/TCP 35sprometheus-operator ClusterIP None <none> 8080/TCP 58s
其中prometheus和alertmanager采用的StatefulSet,其他的Pod则采用deployment创建
[root@k8s-master manifests]# kubectl get deploy -n monitoringNAME READY UP-TO-DATE AVAILABLE AGEgrafana 1/1 1 1 7m36skube-state-metrics 1/1 1 1 7m36sprometheus-adapter 1/1 1 1 7m35sprometheus-operator 1/1 1 1 7m44s[root@k8s-master manifests]# kubectl get sts -n monitoringNAME READY AGEalertmanager-main 3/3 8m4sprometheus-k8s 2/2 7m53s
注意:prometheus-operator是我们的核心文件,它是监控我们prometheus和alertmanager的文件
现在创建完这些资源后,还无法直接访问prometheus。因为都是用的ClusterIP
[root@k8s-master manifests]# kubectl get svc -n monitoring |egrep "prometheus|grafana|alertmanage"alertmanager-main ClusterIP 10.68.58.222 <none> 9093/TCP 9m51salertmanager-operated ClusterIP None <none> 9093/TCP,9094/TCP,9094/UDP 9m44sgrafana ClusterIP 10.68.41.2 <none> 3000/TCP 9m48sprometheus-adapter ClusterIP 10.68.131.211 <none> 443/TCP 9m47sprometheus-k8s ClusterIP 10.68.145.61 <none> 9090/TCP 9m45sprometheus-operated ClusterIP None <none> 9090/TCP 9m33sprometheus-operator ClusterIP None <none> 8080/TCP 9m56s
通过查看上面的svc发现,由于默认的yaml文件svc采用的是ClusterIP,要外部访问可以配置为NodePort类型或者用ingress。下面分别介绍两种方法:
配置为NodePort访问方式:
使用edit进行修改,或者修改yaml文件apply下即可
这里我用edit的方式进行修改。因为yaml文件是真的多,我暂时不想一个个去找
prometheus-k8s、grafana和三个svc都是要这样改的
后面监控k8s组件的笔记中会介绍采用ingress进行端口暴露。如果不想用nodeport测试这里不要更改为nodeport。可以直接看prometheus operator监控K8s组件笔记
kubectl edit svc -n monitoring prometheus-k8skubectl edit svc -n monitoring grafanakubectl edit svc -n monitoring alertmanager-main
温馨提示:三个文件都需要修改,不要修改错了。都是修改有clusterIP的
...
type: NodePort #将这行修改为NodePort
更改如截图方式
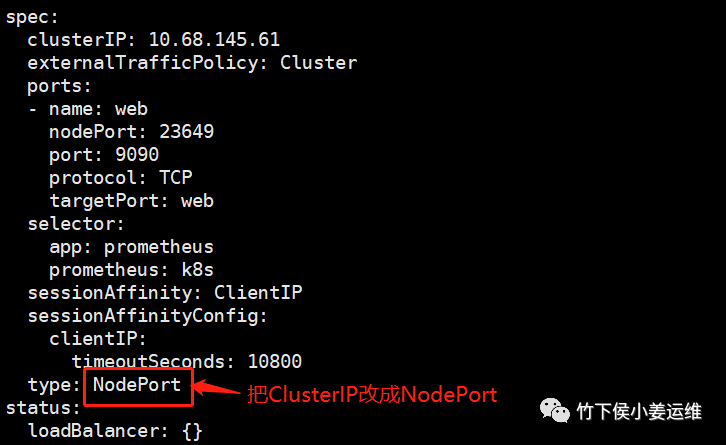
更改完成后查看下svc,能看到这三个都变成了NodePort形式了。然后就可以使用NodePort的方式在浏览器直接进行访问了。
operator会自动帮我们刷新配置
[root@k8s-master manifests]# kubectl get svc -n monitoring |egrep "prometheus|grafana|alertmanage"alertmanager-main NodePort 10.68.58.222 <none> 9093:26090/TCP 36malertmanager-operated ClusterIP None <none> 9093/TCP,9094/TCP,9094/UDP 36mgrafana NodePort 10.68.41.2 <none> 3000:37818/TCP 36mprometheus-adapter ClusterIP 10.68.131.211 <none> 443/TCP 36mprometheus-k8s NodePort 10.68.145.61 <none> 9090:23649/TCP 36mprometheus-operated ClusterIP None <none> 9090/TCP 35mprometheus-operator ClusterIP None <none> 8080/TCP 36m
配置为ingress方法:
以下是ingress配置清单文件:
创建prometheus-ingress.yaml
apiVersion: extensions/v1beta1kind: Ingressmetadata:name: prometheus-ingressnamespace: monitoringannotations:kubernetes.io/ingress.class: "traefik"spec:rules:- host: prometheus.allenjol.comhttp:paths:- path:backend:serviceName: prometheus-k8sservicePort: 9090
创建grafana-ingress.yaml
apiVersion: extensions/v1beta1kind: Ingressmetadata:name: grafana-ingressnamespace: monitoringannotations:kubernetes.io/ingress.class: "traefik"spec:rules:- host: grafana.allenjol.comhttp:paths:- path:backend:serviceName: grafanaservicePort: 3000
ingress规则应用以后,域名解析到ingress-control的ip后就可以用域名来访问了。或者本地做hosts解析就可以在本地电脑上进行访问了
查看prometheus的Ui界面:
这里用了nodeport,所以现在我们用node的ip:port来查看。
[root@k8s-master ~]# kubectl get po,svc -n monitoring -o wide | grep prometheus-k8spod/prometheus-k8s-0 3/3 Running 1 90m 172.20.1.29 192.168.2.220 <none> <none>pod/prometheus-k8s-1 3/3 Running 1 90m 172.20.2.33 192.168.2.221 <none> <none>service/prometheus-k8s NodePort 10.68.145.61 <none> 9090:23649/TCP 91m app=prometheus,prometheus=k8s
这里随便用 192.168.2.220 还是192.168.2.221的ip都行,端口23649
点status---targets 看到如下信息
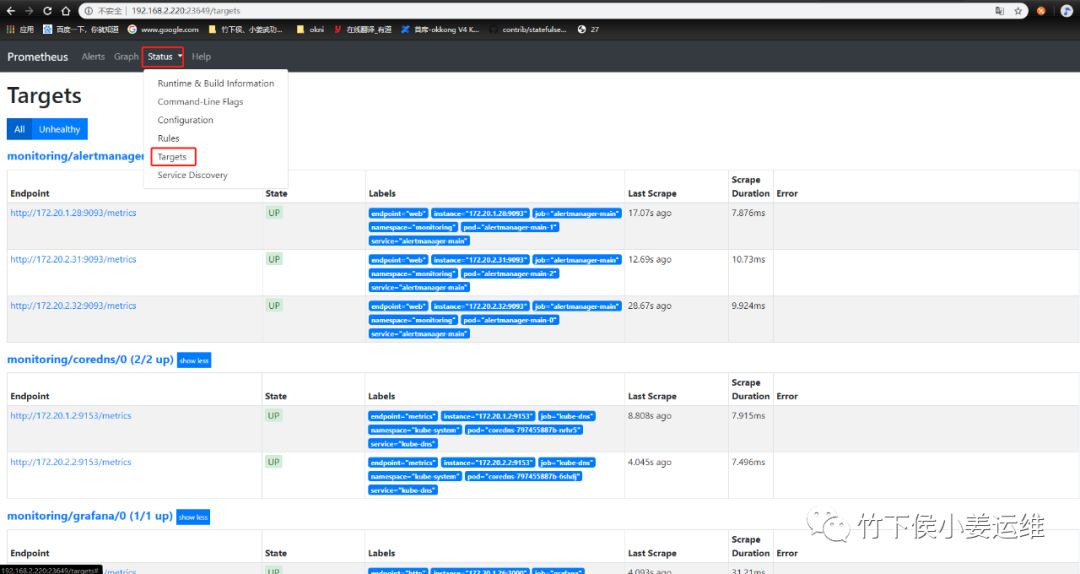
这里kube-controller-manager和kube-scheduler没有监控信息,其他的都有。这和 ServiceMonitor 的定义有关系。由于我这里是二进制安装,所以并没有获取到相关的信息

未完。后续会补充上监控集群组件文章!
完
-----------------------
公众号:竹下侯小姜运维
个人博客:https://www.ayunw.cn
重要的事情认真做,普通的事情规范做!
-----------------------
不定期更新优质内容,技术干货!如果觉得对你有帮助,请扫描下方二维码关注!

温馨提示
如果你喜欢本文,请分享到朋友圈,想要获得更多信息,请关注我。
