




1. 背景
近期,新型冠状病毒感染的肺炎疫情时时刻刻地牵动着每一个中国人的心。无论身在何地,相信大家对这次的疫情都深有体会——居家隔离、小区门禁、抢不到的口罩、延迟开学等等,这次疫情已经影响到了我们生活的各个方面。这次疫情同样也在学术界掀起了轩然大波。各个领域的学者、研究机构都纷纷投入到新冠肺炎的研究中,一时间,各大期刊上关于COVID-19的论文数不胜数。这些论文数据是非常重要的研究材料,需要重点收集整理,那么,如何才能快速、有效地搭建一个关于COVID-19的论文数据库呢?微软Azure就提供了这样一个平台,基于Azure Cognitive Search可以很快地搭建一个数据库,并且可以直接使用其中提供的翻译、关键词提取等服务,为我们省去了手动翻译、人工提取关键词的时间。
2. 构建流程
主要的数据库搭建流程如下所示。
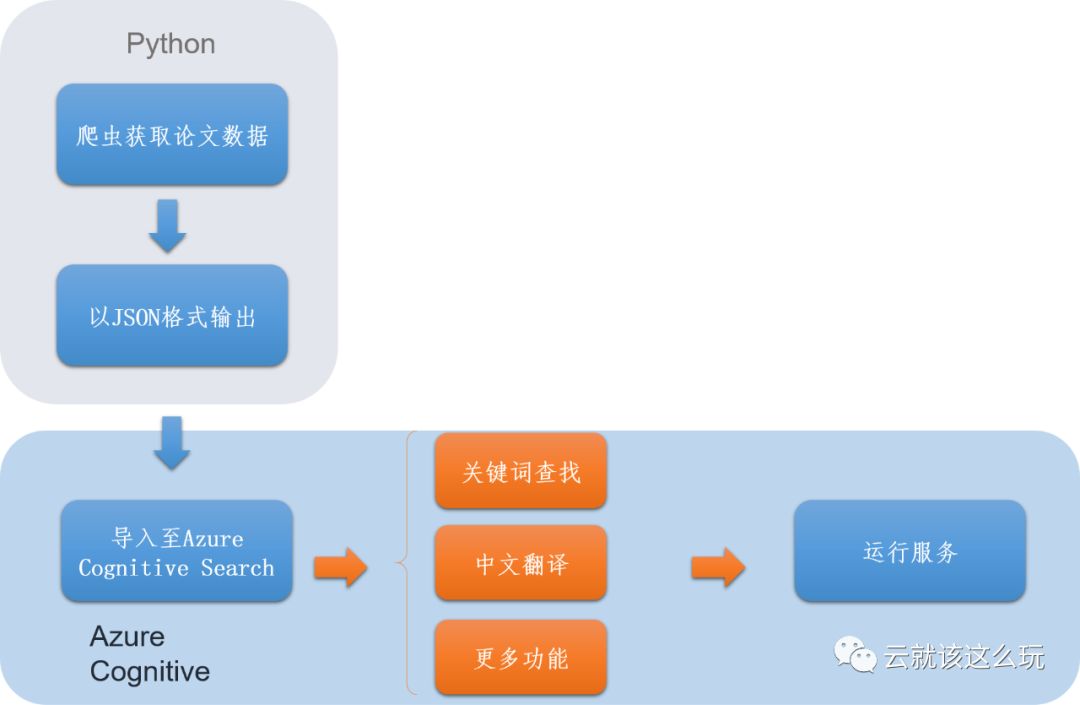
首先,对相关网页进行分析,并且从网站上爬取论文数据,并且以JSON格式输出(当然也可以选择其他格式,本文中重点讨论json格式的存储)。在Azure中,创建Cognitive Search服务,并导入数据,在服务中加入AI选项。在服务建立成功之后,即可运行,进行文档搜索啦。整个流程非常简单明了,下面,我们一起来就此项目从头演示一遍。
3. Python爬取论文数据
3.1 选取论文网址
本文选取的数据库,是之前在本公众号平台上就已经介绍过的Elsevier设立的研究论文免费浏览(参见 最白富美的论文库Elsevier免费提供论文 )以及下载的网址:
https://www.elsevier.com/connect/coronavirus-information-center
在这个网址中的如图所示部分,可以找到elsevier开源的所有COVID-19相关论文:

COVID-19开源论文(点击文末左侧“阅读原文” Read more)
这里也推荐COVID-19科研动态监测 (http://stm.las.ac.cn/STMonitor/qbwnew/openhome.htm?serverId=172),同样可以查询到很多的论文数据。当然,大家可以去爬取微博上关于COVID-19的讨论动态等等。
上面的网页打开之后如下所示,为了演示的方便起见,我们选择2019与2020年的论文建立数据库。最后我们选择的链接是最终url。
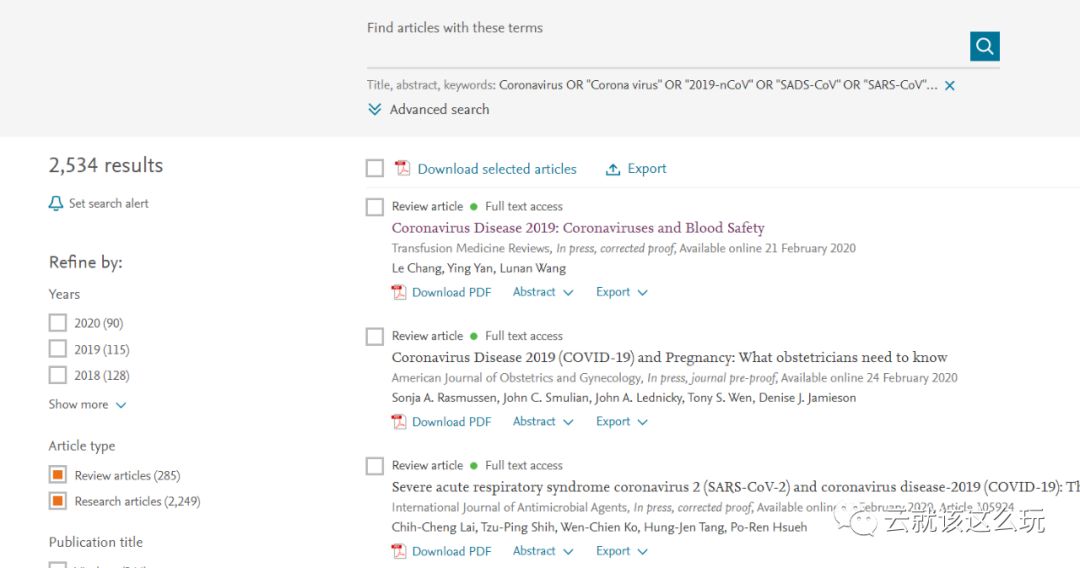
3.2 分析网页结构
这里我们使用的爬虫工具是Python上的lxml库,可以根据网页的html结构进行爬虫,对于搭建小型爬虫非常的方便。
爬虫的主要想法是,首先在主页面上爬取到每个论文的链接,以及论文的标题(论文的标题是为了文本分析使用,对数据库的建立没有太大的影响,在这里可以忽略),然后再进入每个论文的页面,爬取每篇论文的详细信息。
3.2.1 主界面爬取论文链接
首先设置主页面链接以及请求头部信息。
设置URL以及headers

查看网页源代码,找到包含了每篇论文信息的部分。
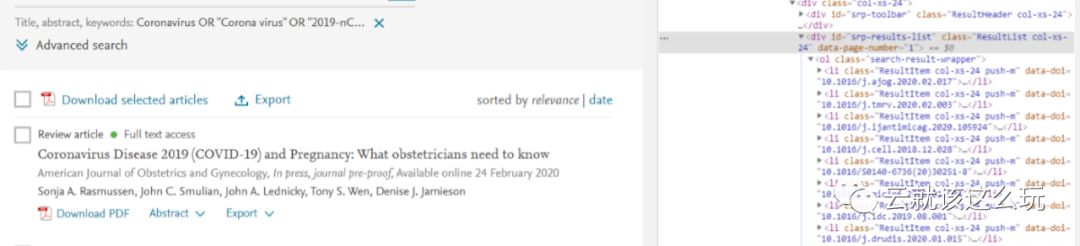
可以看到,论文的搜索结果都包含在在<ol的标签中,每一篇论文的详细信息都包含在<li 标签中。
一篇论文的详细信息如下:

追根溯源,我们找到了包含论文标题以及论文具体地址的标签<a,我们可以通过text()以及@href来爬取获得其具体的链接以及标题。
这里需要强调的是,由于我在进行爬虫的过程中,div以及ol的class不知为何无法对上,所以代码里只能从头开始一个标签一个标签地写。实际上并不需要如此繁杂,可以直接使用//div[@class="..."]这样的书写格式来简化标签的搜索过程,在之后的代码中我们可以看到,这种搜索方法更加简便。
话不多说,本节的代码如下,定义在getelsevier函数中。
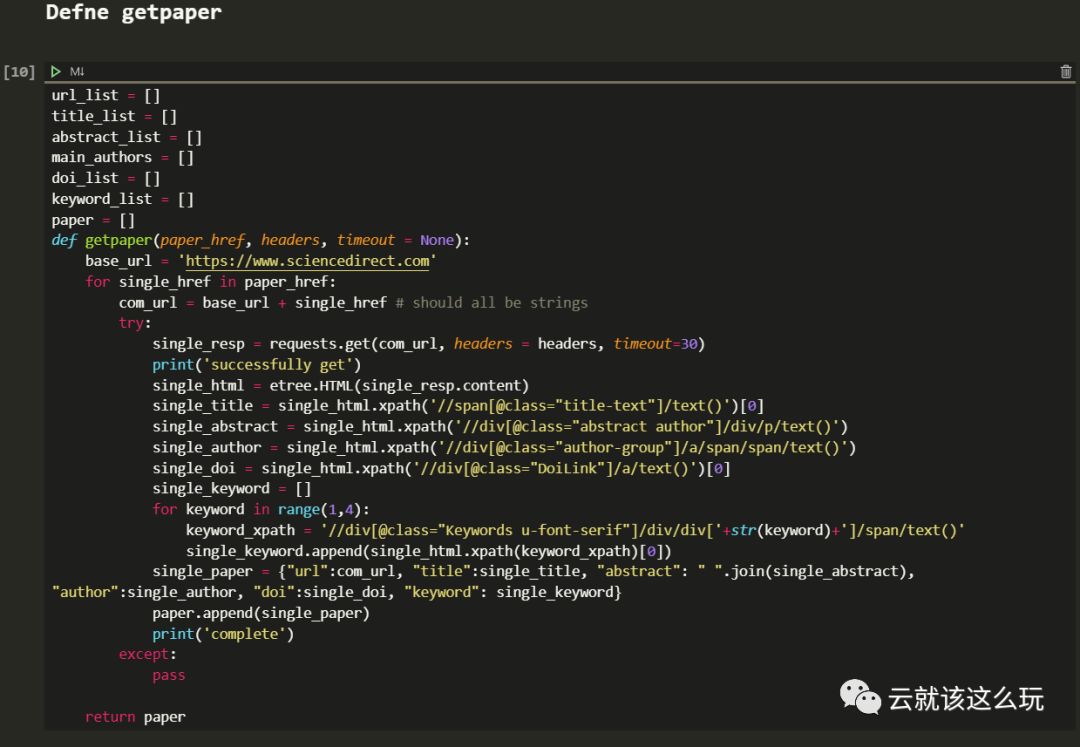
这样我们就获得了所有的论文链接。接下来我们来分析单个的论文链接。
3.2.2 单个论文网页分析
单个论文爬取的任务较重,需要爬取一篇论文的作者、摘要、题目、关键词以及DOI。虽然之前有爬取过论文的标题,但是由于之后爬取能够得到全部信息的论文并不一定与之前爬取得到的论文的标题一致,所以在这里还需要再爬取一次。
每个论文的尾部链接都储存在之前的paper_href中。对每一个链接进行补全,并且访问,爬取其中的论文信息。
网页的主要布局如下,很多文章中还包含了文章的简要介绍视频,以及一些图表,有条件的同学可以自行爬取。

对应的HTML结构如下:



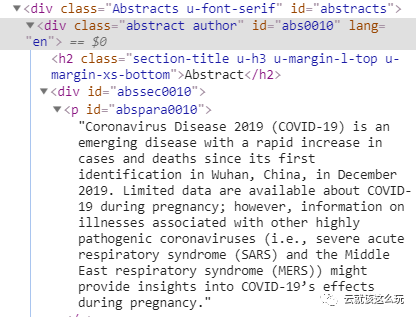
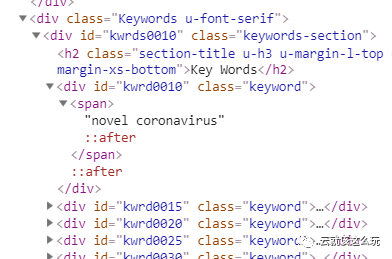
如上图所示,标题存储在<span中。作者常常有多个,这里只爬取前几个作者,每一个作者的信息都存储在<a标签下。文章的摘要存储在<div中,通过text()可以爬取到文章摘要。关键词的爬取与作者的爬取比较相似,关键词全部存储在<div中,通过遍历可以提取出所有的关键词。
分析完网页结构之后就可以写这一部分的代码啦。这里设置了timeout,用来控制时间。
至此,我们的爬取任务就差不多完成啦!最后运行主函数,并以json格式输出,看看有没有错误。
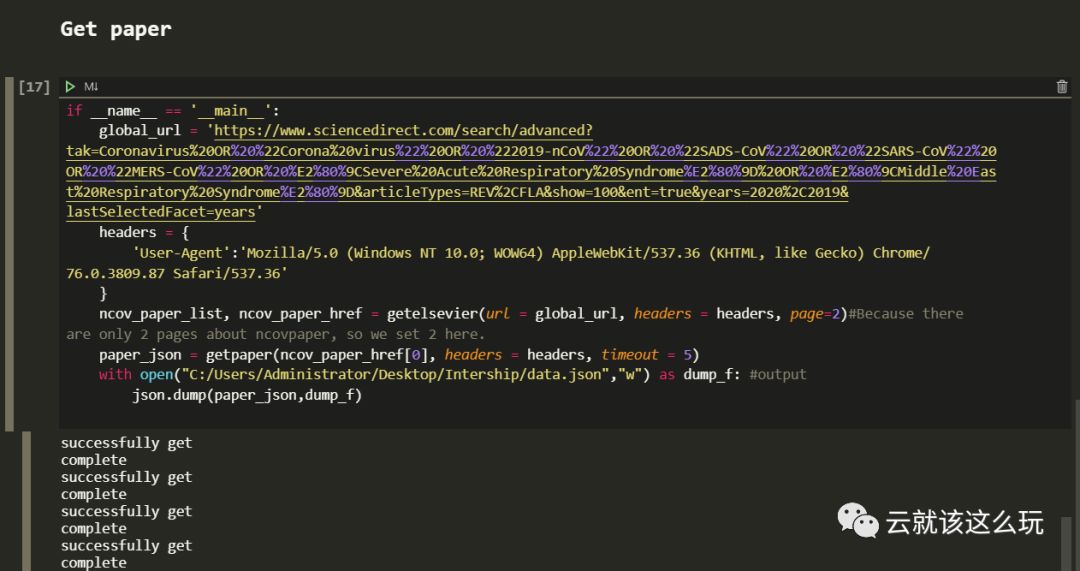
看来运行的还是不错的!就是速度比较慢……这个爬虫的效率并不是非常高的,希望大家能够在这个爬虫的基础上进行改进啦。
(待续)
长按二维码,关注本公众号,或搜寻:云就该这么玩。点击文末右下角"在看"(Wow)分享给关注你关注的人。

