




今天接下来分享剩下的两个case:
新系统割接的library cache问题
执行计划结合业务逻辑的一个等价改写的例子
新系统割接的library cache问题
这是我们在做系统割接的时候的一个案例,可能并不是很常见,这个案例是将Oracle 11g升级到oracle 12c的时候遇到的问题,出现了大量的library cache、library cache:mutex X等待,具体情况是:
新系统割接后,数据库不定时出现大量library cache lock、library cache:mutex X,几分钟后系统自动恢复,等待事件自动消失。
遇到这类诡异的现象,确实头疼,那么如何去解决它了
systemdump和hanganalyze是否可行:
在短暂的时间里,来不及做systemdump或者hanganalyze,而且出现的频率和时间也是不固定的,很难抓取到当时系统的信息,并且systemdump这类对系统也有一定的压力,需要和客户沟通
AWR报告是否有蛛丝马迹:
先获取故障时段的AWR报告
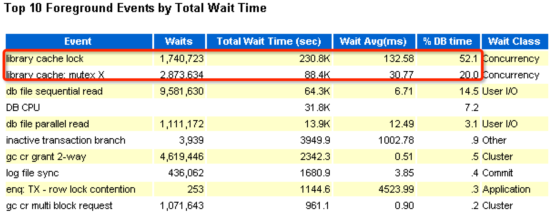
我们看到这两个等待事件已经占了整体DB time的72%,大家看到这个问题,可能一般都会想到是否解析问题,比如硬解析过多。
优化器、共享池参数:
oracle 11g升级到12c并没有调整优化器解析相关的参数、仅仅只是因为内存增大了增加了sga的部分组件的大小
Top SQL的解析、执行频率是否合理:
故障点的library lock相关的SQL来看,基本占据db time、parse阈值高的Top SQL解析、执行频率并没有数量级的增加。
Oracle bug是否存在:
系统版本Oracle 12.1.0.2,经过原厂排查并不存在相关bug引起该等待
SQL解析是否出现了问题,绑定变量使用分析:
查看awr报告硬解析次数很高,但是挖掘shared pool发现系统中并未发现大幅度未使用绑定变量的SQL。
这里补充一个知识点:
在oracle 10g的时候,V$SQLAREA视图有一个FORCE_MATCHING_SIGNATURE 参数,可以将SQL经过绑定变量替换后生成一个hash value值,通过这个值找到未使用绑定变量的SQL,而我们在挖掘未使用绑定变量的SQL时发现开发商的SQL的质量比较高,并未发现核心业务SQL未使用绑定变量的情况。
select FORCE_MATCHING_SIGNATURE||’’, count(1) cnt
from gv$sqlarea
where FORCE_MATCHING_SIGNATURE > 0
and FORCE_MATCHING_SIGNATURE != EXACT_MATCHING_SIGNATURE
group by FORCE_MATCHING_SIGNATURE
having count(1) > 100
order by 2 desc;
这样看来又麻烦了,硬解析次数很高,但我们找不到对应的SQL在哪里?
我们接着分析,来看AWR报告里面的time model statistic,这个我个人认为是awr报告中很重要的内容,应该是仅次于top event部分:
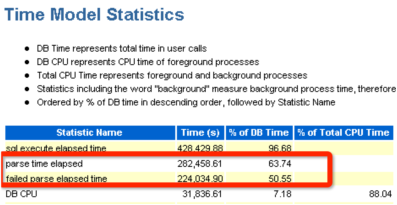
我们看到红色标记的部分,解析时间parse time elapsed消耗了63.74%、解析失败failed parse elapsed time消耗了50.55%,解析失败failed parse elapsed time是什么?
Oracle failed parse解释是这样的:
failed parse:语法、权限等无法执行的SQL解析,也是硬解析,并且解析失败是不能被重用的,当然它也不会存储在V$SQLAREA视图中,所以也挖掘不到这类SQL。
我们如何去发现在系统中解析失败的SQL呢?
Oracle提供了一种比较便捷的方法就是event 10035,该事件会将解析失败的SQL记录到警告日志中
两个节点分别开启event 10035
Alter system set events ‘10035 trace name context forever,level 1’;
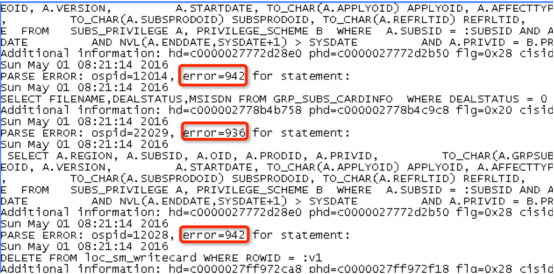
从上面的日志可以看到各种解析错误的代码,其中error=942,表示:表不存在。
判断是系统割接期间有些表被删除了,但是老系统的代码跟该SQL相关的语句依然在执行,由于这些代码即使没有执行成功也不会影响前台业务,所以业务系统是感知不到的,但是却对数据库造成了严重的性能问题。
因此大型系统变更做表删除等操作时,这时候一定要严格挖掘应用端的代码,将下线业务的相关代码停掉或者禁用,避免错误解析导致数据库出现严重的性能问题。
最后再和大家分享执行计划结合业务逻辑的一个等价改写的例子

案例中的SQL如上,大致由两部分组成,上下各是一个标量子查询,然后用union all联合在一起做了一个order by,最后结果中使用了rownum限制来做类似分页的查询。
我们通过脚本获得该SQL单次逻辑读将近18000000.返回行数为10行,响应时间达到104036MS
这是个很复杂的SQL,包含标量子查询、表连接、union all、排序、分页,还有一些复杂的decode、nvl等函数,通过awr报告我们得知该SQL单次执行需要1500多万到1900多万的逻辑读,平均都只返回10行数据,单次执行时间也要100秒左右。

我们可以将SQL简化如下:
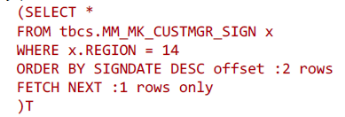
rownum_ from
(SELECT ST.* FROM (Select …TO_CHAR(T.SIGNDATE,
‘YYYYMMDDHH24:MI:SS’) AS SIGNDATE …(标量子查
询1)、(标量子查询2)... From
MM_MK_CUSTMGR_SIGN T WHERE T.REGION = 14
Union all
Select …TO_CHAR(T.SIGNDATE,
'YYYYMMDDHH24:MI:SS') AS SIGNDATE …(标量子查询
1)、(标量子查询2)... From MM_MK_CUSTMGR_SIGN T
WHERE T.REGION = 14
AND T.SIGNOUTOID IS NOT NULL) ST
ORDER BY SIGNDATE DESC) row_ where rownum <= :1)
where rownum_ > :2
对于这种复杂的SQL,我们先看执行计划
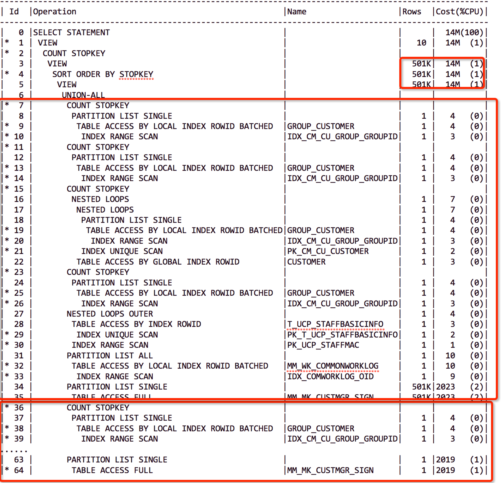
这个执行计划我们做过相应删减。
在优化SQL中,我们优先考虑能否优化cost高的步骤,比如大表全表扫描、大表全索引快速扫描、跳跃索引扫描、大表排序等cost消耗;其次看filter(优化了的nestedloop)、nested loop、hash join、笛卡尔积等表关联步骤cost消耗。
在上面的标量子查询中,Cost消耗最高的在这个view操作,COST消耗达到了14M、rows达到了501K,而这个view是由两部分union all组成的。
在下面的标量子查询中,两部分union all发现上层部分主查询MM_MK_CUSTMGR_SIGN T估
算返回501k Rows,下层主查询则只有1Rows数据。(在Oracle的估算中是不存在0 Rows的情况,如果评估的结果是0,也会算作1.)
对于标量子查询,我们简单做个介绍,就是说优化器在这种情况下永远只做一种操作就是filter,这是一种变相优化nest loop。对于这种标量自从查询,我们知道其实SQL之所以出现问题是因为下面的501k导致需要驱动上面那堆复杂的标量子查询,那么如何优化呢?
优化思路:
常规优化: 对于标量子查询,可以使用等价改写为表的外连接方式让其走hash jion的执行计划,但是如果标量子查询中有大表则并不合适,该SQL恰恰包含大表,并不适合用常规的等价外连接的方式来改写。
业务结合执行计划分析: 那么这个ORDER BY SIGNDATE DESC排序后rownum能否推进到主查询MM_MK_CUSTMGR_SIGN T表中,rownum限制后再去驱动标量子查询,减少标量子查询的循环次数。
我们今天主要针对第二种,结合业务进行分析改写。
在上面的SQL中,是先取501k数据做了驱动,然后再做标量子查询和order by的操作,我们能不能把order by的操作推回到标量子查询前面,这样子的话标量子查询要驱动的只是前面排序取rownum限制条件的数据,我们通过画图的方式来分析一下:
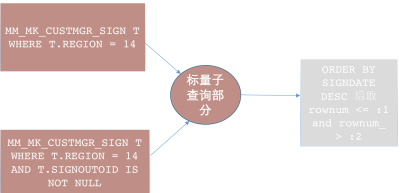
等价的业务逻辑:
首先是两个同样的表,做了标量子查询的操作,这里的数据是501k,然后标量子查询完了之后,做了order by后rownum的限制,这是原SQL的执行业务逻辑。
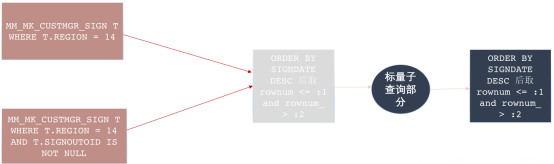
我认为应该写成这样,我们想限制标量子查询的循环次数,那我们就先去对主查询取order by排序rownum限制后的数据,再将主查询取出来的这部分数据去驱动标量子查询,做完后再做一次order by rownum的限制。(这里并不会改变SQL的业务逻辑,虽然我们是先排序取rownum限制了,但是标量子查询时主查询是先排序还是后排序取rownum限制对于主查询返回结果集没有任何影响)
根据这种思路,我把SQL改写如下:
(SELECT row_.*, rownum rownum_ FROM
(SELECT ST.* FROM
(SELECT …TO_CHAR(T.SIGNDATE,
‘YYYYMMDDHH24:MI:SS’) AS SIGNDATE …(标量子查询1)、(标
量子查询2)... FROM
(SELECT *
FROM tbcs.MM_MK_CUSTMGR_SIGN x
WHERE x.REGION = 14
ORDER BY SIGNDATE DESC offset :2 rows
FETCH NEXT :1 rows only
)T
UNION ALL
SELECT …TO_CHAR(T.SIGNDATE,
'YYYYMMDDHH24:MI:SS') AS SIGNDATE …(标量子查询1)、(标
量子查询2)... FROM
(SELECT *
FROM tbcs.MM_MK_CUSTMGR_SIGN x
WHERE x.REGION = 14
ORDER BY SIGNDATE DESC offset :2 rows
FETCH NEXT :1 rows only
)T ) ST ORDER BY SIGNDATE DESC) row_
WHERE rownum <= :1)
WHERE rownum_ > :2
其中
和
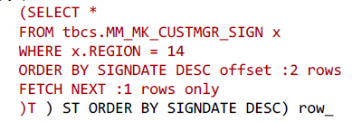
是12C的改写方式。是用一个分析函数的方式去做的。
它的执行计划如下:
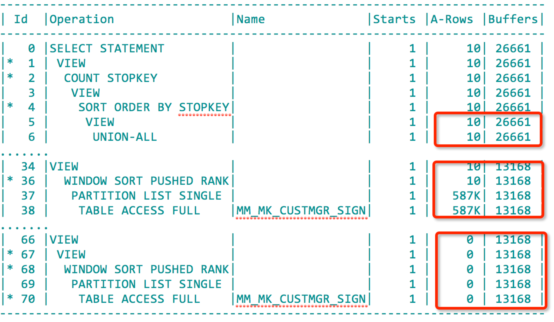
先访问表MM_MK_CUSTMGR_SIGN排序取rownum限制(前10行数据后),再去驱动那堆复杂的标量子查询,最后再次排序取rownum条件数据,逻辑读从千万级降低到了26661。
这个SQL在改写后,资源消耗降低了许多,基本上能够满足业务的需求。
如果我们再去剖析原SQL代码,发现union all部分是同一个MM_MK_CUSTMGR_SIGN表的查询,下面那个UNION ALL部分查询出来的结果是上面UNION ALL部分的子集。

而跟研发沟通发现实际上union all的下层查询可以去掉,去掉后则该SQL无需改写rownum就可以直接推进到主查询中,从这个例子可以看到不严谨的代码容易造成性能隐患,影响优化器评估最合理的执行计划。
我们来回顾一下前面讲过的内容:
1 复合索引的前导列选择要切合应用,选择的复合索引尽可能让更多的业务SQL受用;核心业务SQL创建索引复合索引,复合索引应该选择等值条件的列做为索引的前导列。
2 绑定变量也要结合字段业务类型、直方图、优化器环境来综合考虑,不需要使用绑定变量的代码不要使用。(绑定变量窥视关闭、直方图开启情况下,状态值、枚举值不建议使用绑定变量)
3 线上系统变更、表下线需要严格挖掘应用端代码,避免因为表结构变更导致SQL解析错误。
4 复杂业务逻辑对应的SQL需要核查,对于不需要的结果和表关联等尽可能去掉,简化表关联数量,合理利用优化器。
我的分享完毕,谢谢!
