





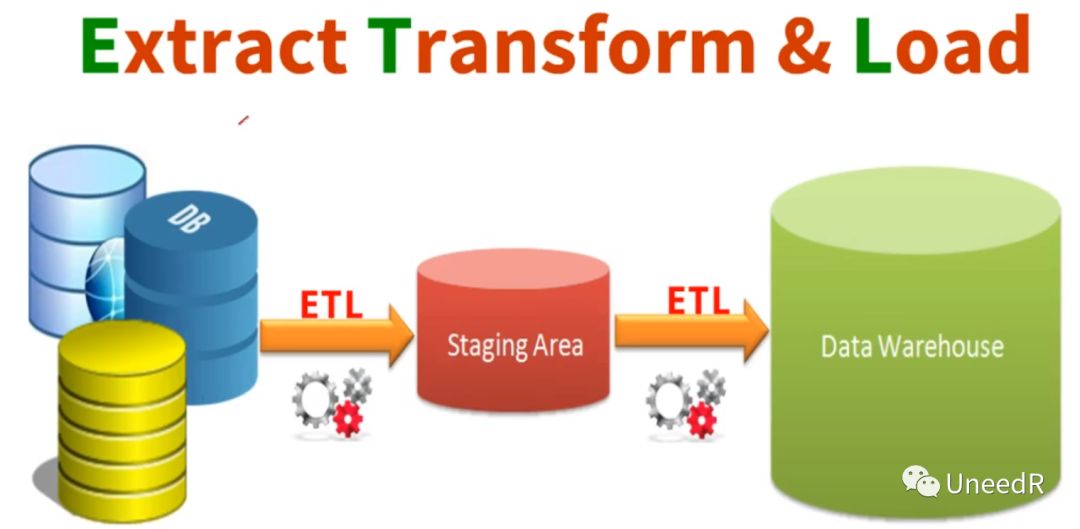
我们在讨论企业数据架构的时候,介绍了ETL及传统的数据仓库架构,ETL是英语提取(Extract)、转换(Transformation)及加载(Load)的简称,从下图可以看到,各类数据经过第一次ETL会存放在一个临时区域Staging Area),数据经过最终转换后才被加载到企业的数据仓库。当然在整个流程中临时区域不是必须的,但是如果你的数据源中有大量文件数据的话,临时区域可以加快整体ETL的传输速度。
在E阶段有三种提取数据的方式:
第一种是完全提取,通常在数仓刚建立时需要对全数据源做初始化加载时使用;
第二种是带更新标识的增量提取,在提取的时候只对上次变更的数据进行更新,比如说哪些数据删除了,哪些数据被修改了,哪些数据是第一次录入等等。增量提取的数据也叫Delta。
最后一种是不带更新标记的增量提取,这类提取是基于某个键值或某种策略,比如说提取最后更新日期是今天的数据,最后更新日期就是数据表中的一个键值。
当然在设计提取方式的时候,一定不能对源系统带来任何影响,比如性能、响应时间或任何形式的数据锁闭。

在数据转换阶段,首先会选取需要转换并最终进入数据仓库的数据、匹配对应的筛选规则,并将数据转换成目标格式(因为数据类型众多,需要对字段进行删减、扩充或合并,包括对源数据的编码进行转换-比如日期格式等),最后将数据汇总(包括去重)。

在加载阶段,对应提取阶段,数据加载的方式也有三种:首先是初始加载(Initial Load),指当目标数据源第一次接入时,将所有表结构加载到数据仓库;其次是增量加载(Increnental Load),指定期地加载相较上一次更新了的数据;最后一种是完全刷新(Full Refresh),指将之前某个或多个表的数据清楚,然后重新加载新数据。

ETL的工具有很多,产品化的、开源的都有,可以用来管理整个ETL流程。

早先这样的ETL数据架构可以承载足够多的数据量,但随着数据类型的越来越丰富,尤其是对于日志、IoT等非结构化数据(当然,可以将Hadoop与现有数仓并联,但会大大增加ETL中转换环节的时间和出错率),或者一些对实时性要求比较高的报表,在传统ETL架构上需要添加应用间互联、中间件互联加上一些安全、监控系统接入,长此以往内部的数据架构和应用架构就会变得一团乱。
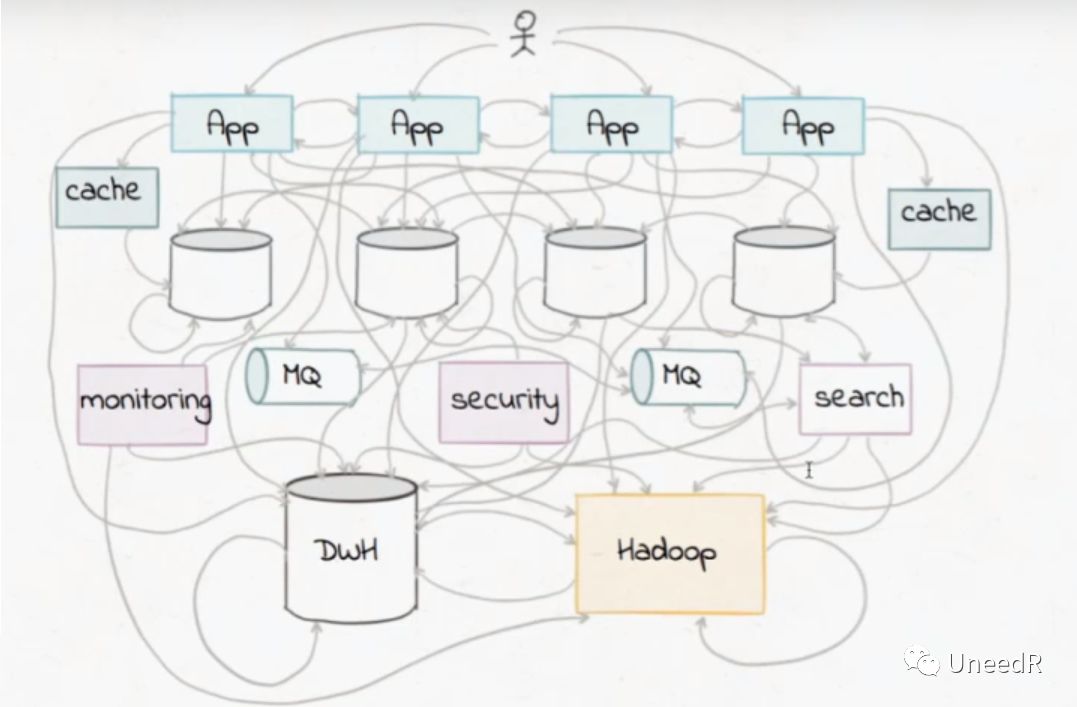
而这并没有真正满足数据实时性的要求,只能通过每天多次“跑批”来应付不同业务的需求。在面对突入起来的“大数据”,ETL的弊端展露无遗。
首先ETL的数据仓库需要一个全局的数据框架(Schema),正如我们上面所讲的在原始数据加载到数仓之前需要做格式转换以将各种数据标准化,满足这个全局数据框架的要求;
其次在转换过程中难免会碰到一些字段清理和修正的工作,因此这个过程往往需要人工介入,因此可以说转换过程是容易出差错的;
除了设计全局数据框架费时费力,并且需要精准调研外,ETL的运维程本也 是非常高的,很多企业往往有24小时的运维团队来应对各种跑批问题;
最后,ETL作为一个面向批处理的数据流,数据吞吐量是十分有限的。
当人们第一次意识到数据实时性的问题时,并没有准备改变ETL的数据架构,而是在应用架构中引入企业应用集成(Enterprise Application Integration,EAI),EAI通过企业服务总线(ESB)和消息队列(MQ)消除了应用间的壁垒,但它的扩展性较差。
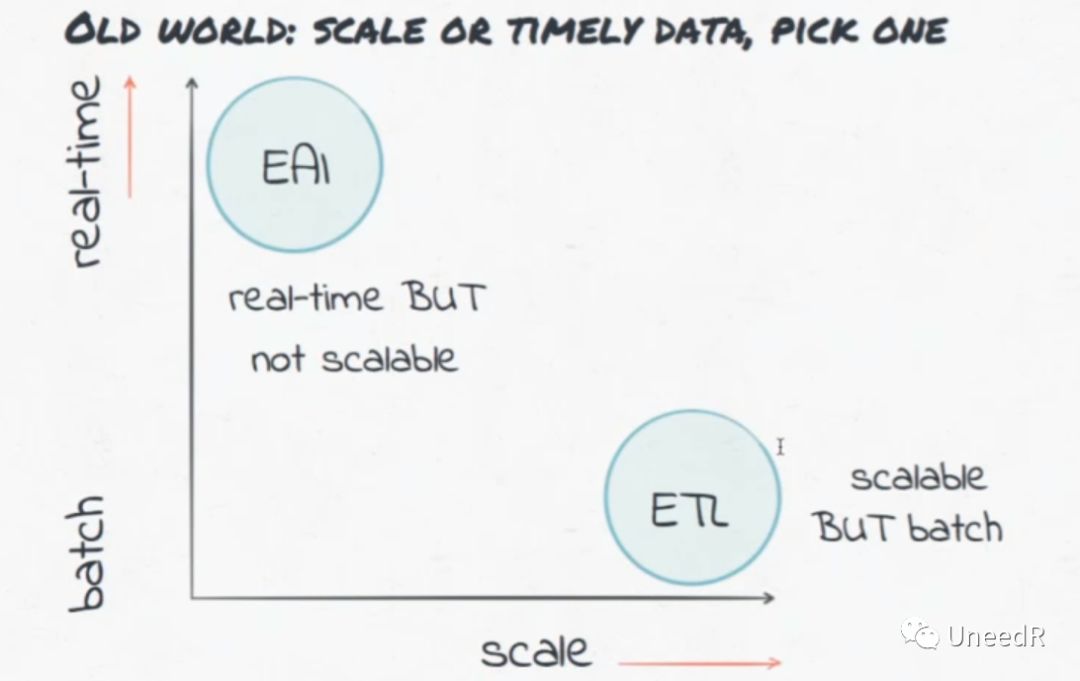
对于数据架构,我们的需求很明确,就是需要一个既满足数据实时性要求又能自由扩展的流式平台(Streaming Platform)。我们希望这个平台可以从各种形式的数据流加载实时数据,提交给各种实时业务平台对数据进行实时处理。
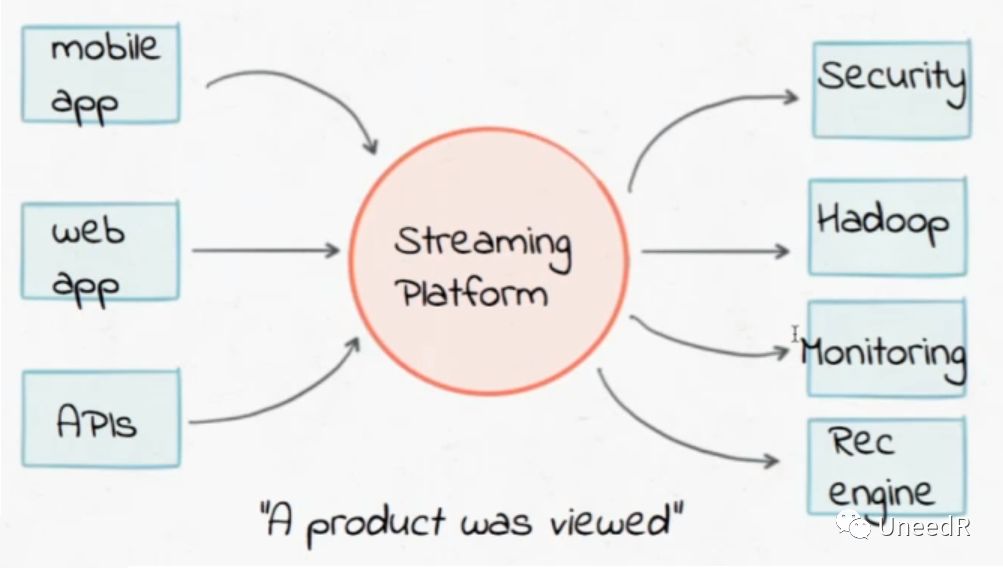
即便有新的数据生产系统接入时,你不再需要与其他数据源做点到点的数据关联,只需接入数据流平台即可。同样新的数据消费系统接入时,也是如此。相较于之前网状的ETL数据流拓扑,流式的消息总线是星型的,对于原始数据也不需要二次转换来区分结构化与非结构化数据。
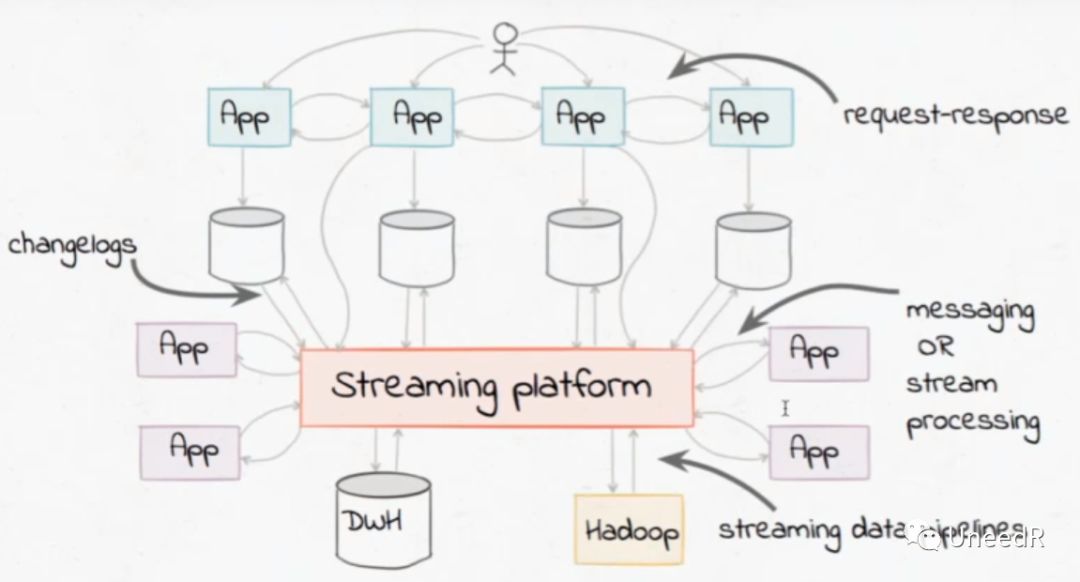
Apache Kafka就是一个流式的消息总线,据有统计的调查显示,Kafka每日的消息处理能力可达近两万亿条,在问世的八年时间里迅速成长为各大型互联网及金融公司的核心总线,在世界五百强中占40%左右,包括大家熟悉的阿里、eBay、Paypal等大公司。
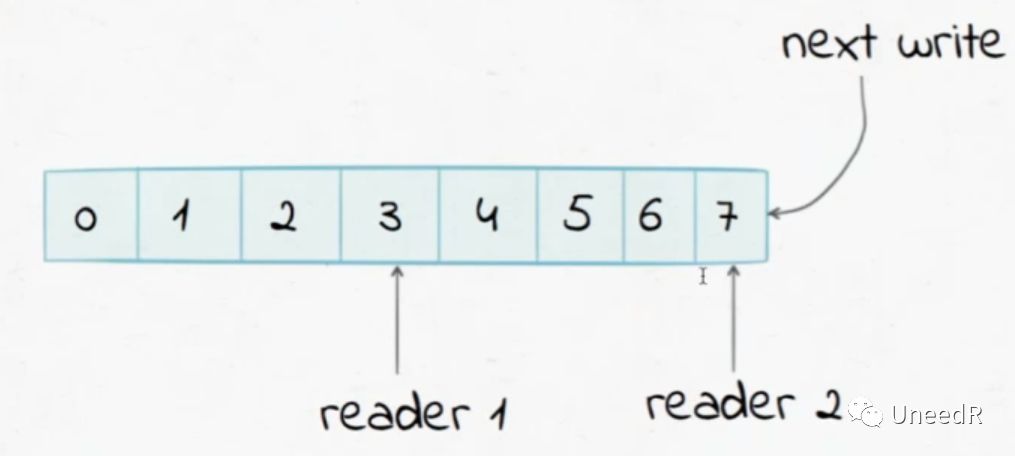
在Kafka的传输体系中,各类数据被切块划分,每一个数据源被定义为一个topic,这个topic中的每一数据块被标以唯一标识(或叫Offset)并从小到大排列。当数据被消费时,消费系统只要找到对应的topic就能按顺序读出所需要的数据。
它对外提供的Kafka Connector API相当于ETL中的E和L,对接数据源和数据消费者,除此之外Kafka还能面向不同应用直接提供消息API或数据流API。
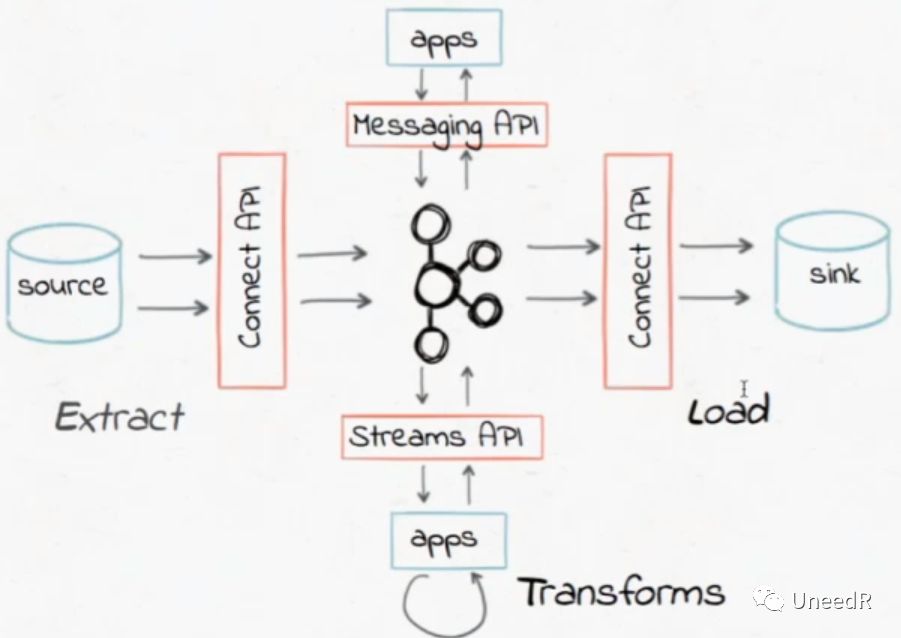
在Kafka的总线中还能加入机器学习的代码以对特定的topic进行高度定制化处理(相当于ETL中的T,不过不需要框定全局Schema)。类似于Kafka的流式数据总线还有Storm,Spark Stream和Flink等,实时数据流在一些重要应用上有着批量数据流无法比拟的优势:比如金融欺诈检测(谁也不希望看到自己的汇款交易需要很长时间才到账,然而安全监管系统又是必须的);防垃圾邮件系统(同样,必要的过滤不能影响邮件的实时性);网络异常检测(网断了用户当然希望尽快修复,但首先运维人员需要及时获悉);IoT中的阈值告警(不尽快处理会导致终端宕机)等等。


长按,识别二维码,加关注
