




1 synchronous_commit
2 synchronous_standby_name
这两个是必须的要进行设置必选项
synchronous_commit
下面是他的几个选项
on
事务提交总是等待,直到将数据真正刷新到事务日志(也称为WAL或XLOG),以确保事务确实是持久的。在同步流复制模式下,副本也需要这样做。
off
事务flush wal_log 前,就可以向用户提交确认,当然付出的代价就是在服务器crash时会损失那些没有提交单没有flush 到wal_log 的数据
local
这个选择仅仅保证你的事务commited 后不再主节点丢失数据,standby不保证数据不丢失。
remote_write
与on选项相比,这并不会不丢失数据,standby 仅仅等等操作系统返回数据写入的磁盘的确认。
remote_apply
这个是我们需要的选项,提供了复制的强一致选项,主库不会在没有从库提交返回数据已经安全写入standby之前commit,这这个选项的意义在于,主和从在任何一个时间数据都是一直的,或者一起去dead。
列出一个从弱到强的对数据的一致性保护
off (async) > on (async) > remote_write (sync) > on|local (sync) > remote_apply (sync)
而synchronous_standby_name 的与上面的意义不同的在于,他在选择你要哪个从库与你一致,因为可能有很多的从库与你进行数据的同步。
最简单粗暴的就是用 * 来代表,当然你也可以写成mongodb 的方式 'ANY 2 (服务器1 ,服务器2 服务器3) ' 这就是MONGODB 的里面的大多数的概念,POSTGRESQL 这里也是至少2个 standby与我一致我才罢休,否则不可以。
或者也可以写成固定的模式 'FIRST 2 (服务器1 , 服务器2 , 服务器3) ' 至少前边两个服务器必须与你的primary 数据一致(具体看上面那个参数的设置)
才能让primary commit or no .
下面我们做一个例子
两台机器,使用pg_basebackup 做了最基本的复制,相关复制怎么做请参见之前的文字。
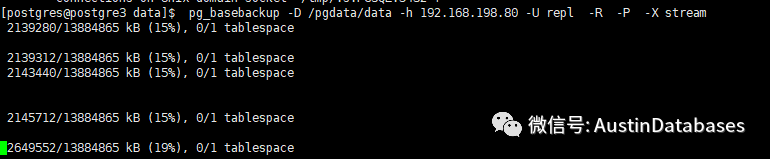
我们下面做一个实验
1 我们在primary 服务器上开启事务
2 我们在commit 前将从库关闭
3 我们看看会怎么样
主库
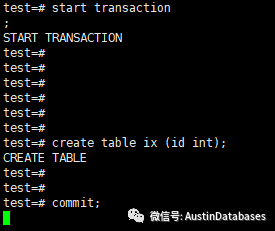
从库

可以很清晰的看到,从库不在线的情况下,主库根本没有办法commit
我们可以看下面,明显开启从库后,主库自动就将事务commit了

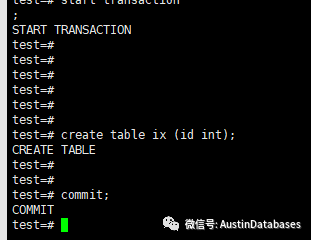
也可以看一下primary 和 standby 的日志
primary

standby

再次基础上,配合keepalive 去验证postgresql 服务,并且其中包含promote命令,就能完成一个最简单的高可用的postgresql。
其实如果MYSQL 的复制能做到强一致性的话,可能也就没有当初MHA什么事情了。MYSQL + KEEPALIVE 也可能是一种可靠的选择。
再次重申,怕有同学误会,觉得我推荐这样的高可用,请在回顾一下题目,最简单的,另外还是那句话,看需求,在做,要不仅仅人家就要一个KONG 的简单需求,并且人家公司也没有POSTGRESQL DBA,要人家REPMGR PATRONI,PG 的 数据库DBA It's too expensive and hard to find 。
关于我们
中国开源软件推进联盟PostgreSQL分会(简称:PG分会)于2017年成立,由国内多家PG生态企业所共同发起,业务上接受工信部产业发展研究院指导。PG分会致力于构建PG产业生态,推动PG产学研用发展,是国内的一家PG行业协会组织。

