




1.HDFS
Hadoop分布式文件系统被设计成适合运行在通用硬件(commodity hardware)上的分布式文件系统。它和现有的分布式文件系统有很多共同点。但同时,它和其他的分布式文件系统的区别也是很明显的。HDFS是一个高度容错性的系统,适合部署在廉价的机器上。HDFS能提供高吞吐量的数据访问,非常适合大规模数据集上的应用。HDFS放宽了一部分POSIX约束,来实现流式读取文件系统数据的目的。HDFS在最开始是作为Apache Nutch搜索引擎项目的基础架构而开发的。
HDFS组成部分:
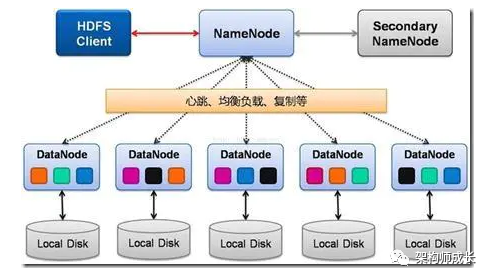
HDFS由四部分组成,HDFS Client、NameNode、DataNode和Secondary NameNode。HDFS是一个主/从(Mater/Slave)体系结构,HDFS集群拥有一个NameNode和一些DataNode。NameNode管理文件系统的元数据,DataNode存储实际的数据。
HDFS客户端:就是客户端。
1、提供一些命令来管理、访问 HDFS,比如启动或者关闭HDFS。
2、与 DataNode 交互,读取或者写入数据;读取时,要与 NameNode 交互,获取文件的位置信息;写入 HDFS 的时候,Client 将文件切分成 一个一个的Block,然后进行存储。
NameNode:即Master,
1、管理 HDFS 的名称空间。
2、管理数据块(Block)映射信息
3、配置副本策略
4、处理客户端读写请求。
DataNode:就是Slave。NameNode 下达命令,DataNode 执行实际的操作。
1、存储实际的数据块。
2、执行数据块的读/写操作。
Secondary NameNode:并非 NameNode 的热备。当NameNode 挂掉的时候,它并不能马上替换 NameNode 并提供服务。
1、辅助 NameNode,分担其工作量。
2、定期合并 fsimage和fsedits,并推送给NameNode。
3、在紧急情况下,可辅助恢复 NameNode。
2.HBase
HBase是一个分布式的、非关系型开源数据库。HBase有如下几个特点:HBase是No-SQL的一个典型实现,提升了系统的可扩展性;HBase支持线性水平扩展,极大提升了系统的可伸缩性和运算能力;HBase参考了Google的BigTable建模,使用java实现,底层也是建立在HDFS(Hadoop分布式文件系统)之上,可以搭建在廉价的PC机集群上。HBase的目标是处理非常庞大的表,可以通过水平扩展的方式,利用廉价计算机集群处理由超过10亿行数据和数百万列元素组成的数据表。
HBase与传统的关系数据库的区别主要体现在以下几个方面:
数据类型:关系数据库采用关系模型,具有丰富的数据类型和存储方式,HBase则采用了更加简单的数据模型,它把数据存储为未经解释的字符串。
数据操作:关系数据库中包含了丰富的操作,其中会涉及复杂的多表连接。HBase操作则不存在复杂的表与表之间的关系,只有简单的插入、查询、删除、清空等,因为HBase在设计上就避免了复杂的表和表之间的关系。
存储模式:关系数据库是基于行模式存储的。HBase是基于列存储的,每个列族都由几个文件保存,不同列族的文件是分离的。
数据索引:关系数据库通常可以针对不同列构建复杂的多个索引,以提高数据访问性能。HBase只有一个索引——行键,通过巧妙的设计,HBase中的所有访问方法,或者通过行键访问,或者通过行键扫描,从而使得整个系统不会慢下来。
数据维护:在关系数据库中,更新操作会用最新的当前值去替换记录中原来的旧值,旧值被覆盖后就不会存在。而在HBase中执行更新操作时,并不会删除数据旧的版本,而是生成一个新的版本,旧有的版本仍然保留。
可伸缩性:关系数据库很难实现横向扩展,纵向扩展的空间也比较有限。相反,HBase和BigTable这类分布式数据库就是为了实现灵活的水平扩展而开发的,能够轻易地通过在集群中增加或者减少硬件数量来实现性能的伸缩。
Hbase数据模型
Hbase是一个稀疏、多维度、排序的映射表,这张表的索引是行键、列族、列限定符和时间戳。存储结构如下图:
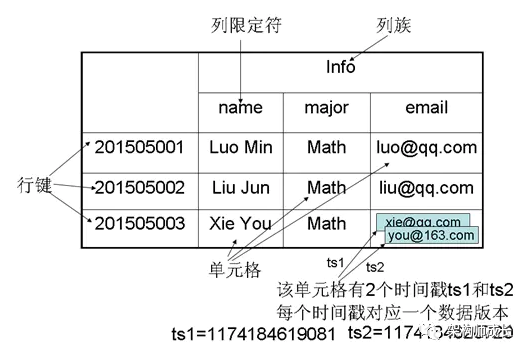
每个值是一个未经解释的字符串,没有数据类型。用户在表中存储数据,每一行都有一个可排序的行键和任意多的列。
表在水平方向由一个或多个列族组成,一个列族中可以包含任意多个列,同一个列族里面的数据存储在一起。
列族支持动态扩展,可以很轻松地添加一个列族或列,无需预先定义列的数量以及类型,所有列均以字符串形式存储,用户需要自行进行数据类型转换。
HBase中执行更新操作时,并不会删除数据旧的版本,而是生成一个新的版本,旧的版本仍然保留(这是和HDFS只允许追加不允许修改的特性相关的)。
3.Hive
是一个建立在Hadoop架构之上的数据仓库。它能够提供数据的精炼,查询和分析。hive是基于Hadoop的一个数据仓库工具,可以将结构化的数据文件映射为一张数据库表,并提供简单的SQL查询功能,可以将SQL语句转换为MapReduce任务进行运行。其优点是学习成本低,可以通过类SQL语句快速实现简单的MapReduce统计,不必开发专门的MapReduce应用,十分适合数据仓库的统计分析。
Hive 不应该用来进行实时的查询(Hive 的设计目的,也不是支持实时的查询)。因为它需要很长时间才可以返回结果;HBase 则非常适合用来进行大数据的实时查询,例如 Facebook 用 HBase 进行消息和实时的分析。
4.Hue
是一个开源的Apache Hadoop UI系统,最早是由Cloudera Desktop演化而来,由Cloudera贡献给开源社区,它是基于Python Web框架Django实现的。通过使用Hue我们可以在浏览器端的Web控制台上与Hadoop集群进行交互来分析处理数据,例如操作HDFS上的数据,运行MapReduce Job等等。
5.Impala
是Cloudera公司主导开发的新型查询系统,它提供SQL语义,能查询存储在Hadoop的HDFS和HBase中的PB级大数据。已有的Hive系统虽然也提供了SQL语义,但由于Hive底层执行使用的是MapReduce引擎,仍然是一个批处理过程,难以满足查询的交互性。相比之下,Impala的最大特点也是最大卖点就是它的快速。
Impala没有再使用缓慢的Hive+MapReduce批处理,而是通过使用与商用并行关系数据库中类似的分布式查询引擎(由Query Planner、Query Coordinator和Query Exec Engine三部分组成),可以直接从HDFS或HBase中用SELECT、JOIN和统计函数查询数据,从而大大降低了延迟。
Impala相对于Hive所使用的优化技术:
没有使用MapReduce进行并行计算,虽然MapReduce是非常好的并行计算框架,但它更多的面向批处理模式,而不是面向交互式的SQL执行。与MapReduce相比Impala把整个查询分成一执行计划树,而不是一连串的MapReduce任务,在分发执行计划后,Impala使用拉式获取数据的方式获取结果,把结果数据组成按执行树流式传递汇集,减少了把中间结果写入磁盘的步骤,再从磁盘读取数据的开销。Impala使用服务的方式避免每次执行查询都需要启动的开销,即相比Hive没了MapReduce启动时间。
使用LLVM产生运行代码,针对特定查询生成特定代码,同时使用Inline的方式减少函数调用的开销,加快执行效率。
用C++实现,做了很多有针对性的硬件优化,例如使用SSE指令。
更好的IO调度,Impala知道数据块所在的磁盘位置能够更好的利用多磁盘的优势,同时Impala支持直接数据块读取和本地代码计算checksum。
通过选择合适的数据存储格式可以得到最好的性能(Impala支持多种存储格式)。
最大使用内存,中间结果不写磁盘,及时通过网络以stream的方式传递。
6.Sqoop
Sqoop是一种旨在在Hadoop与关系数据库或大型机之间传输数据的工具。您可以使用Sqoop从关系数据库管理系统(RDBMS)(例如MySQL或Oracle)或大型机中将数据导入Hadoop分布式文件系统(HDFS),在Hadoop MapReduce中转换数据,然后将数据导出回RDBMS 。Sqoop使用MapReduce导入和导出数据,这提供了并行操作以及容错能。
7.yarn
Apache Hadoop YARN (Yet Another Resource Negotiator,另一种资源协调者)是一种新的 Hadoop 资源管理器,它是一个通用资源管理系统,可为上层应用提供统一的资源管理和调度,它的引入为集群在利用率、资源统一管理和数据共享等方面带来了巨大好处。
YARN的基本思想是将JobTracker的两个主要功能(资源管理和作业调度/监控)分离,主要方法是创建一个全局的ResourceManager(RM)和若干个针对应用程序的ApplicationMaster(AM)。这里的应用程序是指传统的MapReduce作业或作业的DAG(有向无环图)。
YARN 分层结构的本质是 ResourceManager。这个实体控制整个集群并管理应用程序向基础计算资源的分配。ResourceManager 将各个资源部分(计算、内存、带宽等)精心安排给基础 NodeManager(YARN 的每节点代理)。ResourceManager 还与 ApplicationMaster 一起分配资源,与 NodeManager 一起启动和监视它们的基础应用程序。在此上下文中,ApplicationMaster 承担了以前的 TaskTracker 的一些角色,ResourceManager 承担了 JobTracker 的角色。
Yarn 资源调度通常默认 CDH 设置 DRF 作为默认的调度器,该资源调度将会在考虑内存的同时也考虑 CPU 需求作为调度的条件。
