




特别申请:我们公众号已升级后台服务,可通过与我们公众号对话完成文章的Demo效果,本文公众号关键词输入:文本抽取,文本分类,或通过help查看其它更多命令,因公众号有5s响应限制,如未得到及时响应,可重复输入相同内容(间隔5s左右发送)两次获取结果
概述
在我们实际业务数据处理中,针对数据处理除了基于规则外,有时候还需使用NLP解决业务需求,如报价识别:16D 19国网租赁CP001 041900383 4.00/-- 2000/-- AAA
(实体对象抽取,包含债券名称,代码,到期日,价格,报量等),文件分类(文本分类,通过机器自动学习)。目前NLP技术发展迅猛,可以用来解决如下问题(重点解决领域已加粗):
•中文分词•文本分类•情感分析•信息抽取•知识标注•语义匹配•问答系统•对话系统•文本生成•机器翻译•文本摘要或关键字提取
本文从PaddleHub
出发,用来解决NLP问题中经典的文本分类和信息抽取。
功能实现
使用百度的ERNIE
,你几乎无需编码,只需要自定义数据集和调整参数,即可完成模型的训练和预测,以文本分类为例,首先我们准备好训练集,文件类似如下:
label text_acategory_zf_szsh 飞力达:关于筹划发行股份购买资产停牌的进展公告dfzfz 2020年宁夏回族自治区政府专项债券(五至六期)招投标书……
编写一段训练数据集的代码:
model = hub.Module(name='ernie_tiny', version='2.0.2', task='seq-cls', num_classes=len(MyDataset.label_list))tokenizer = model.get_tokenizer()train_dataset = MyDataset(tokenizer,mode='train')test_dataset = MyDataset(tokenizer,mode='test')dev_dataset = MyDataset(tokenizer,mode='dev')#train_dataset = hub.datasets.ChnSentiCorp(tokenizer=model.get_tokenizer(), max_seq_len=128, mode='train')#dev_dataset = hub.datasets.ChnSentiCorp(tokenizer=model.get_tokenizer(), max_seq_len=128, mode='dev')#test_dataset = hub.datasets.ChnSentiCorp(tokenizer=model.get_tokenizer(), max_seq_len=128, mode='test')for i in range(10):print(test_dataset.examples[i])optimizer = paddle.optimizer.Adam(learning_rate=5e-5, parameters=model.parameters()) # 优化器的选择和参数配置trainer = hub.Trainer(model, optimizer, checkpoint_dir='./ckpt_file_cate', use_gpu=True) # fine-tune任务的执行者trainer.train(train_dataset, epochs=100, batch_size=32, eval_dataset=dev_dataset, save_interval=1) # 配置训练参数,启动训练,并指定验证集result = trainer.evaluate(test_dataset, batch_size=32)
训练需要等待一段时间,等训练完后,即可进行文本分类预测,编写代码:
import paddlehub as hubimport paddleimport numpy as np# Data to be prdicteddata = [["浙江义乌农村商业银行股份有限公司2020年第018期同业存单发行情况公告"],["北京市首都公路发展集团有限公司2015年度第二期中期票据兑付公告"],["四川新网银行股份有限公司2020年第010期同业存单发行公告"],["鄂尔多斯银行股份有限公司2020年第065期同业存单发行公告"],["盛京银行股份有限公司2020年第217期同业存单发行情况公告"]]#label_map = label_list=['category_zf_szsh',……,'category_sf_szsh']#label_map = {0: 'negative', 1: 'positive'}label_map = {0:'category_zf_szsh',……,51:'category_sf_szsh'}model = hub.Module(name='ernie_tiny',task='seq-cls',load_checkpoint='./ckpt_file_cate/best_model/model.pdparams',label_map=label_map)results = model.predict(data, max_seq_len=128, batch_size=1, use_gpu=True)print(results)for idx, text in enumerate(data):print('Data: {},{} \t Lable: {}'.format(idx,text[0], results[idx]))
在我们公众号,输入文本分类
后输入文件名试试根据金融文件名将文件自动归类吧,准确率非常高。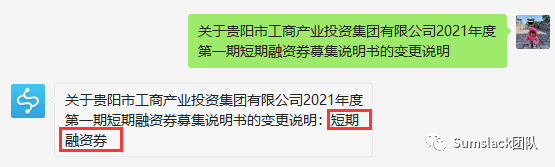
总结
NLP可以大大减少开发工作量,我们之前通过编写脚本规则来进行文本分类,不同的分类我们需要编写不同的脚本,而且没有自学习能力,无法将工作下移到业务部门,通过引入NLP很好的解决了自学习能力,通过标注平台,将文档分类错误的通过业务部门反馈到系统,以便更好的纠正模型,针对业务文本分类再也无需编写代码,即可在未来的文档解析平台通过定义数据集,让平台自动训练即可完成。
你可以继续阅读:
一款自动生成后台代码的管理系统的设计与实现 | “大”中台,“小”前端的架构演变| 云服务平台中推送服务的设计与实现 | 对微服务的理解以及实现一套微服务对外发布API管理平台 | 项目开发中常用的设计模式整理 | 异构语言调用平台的设计与实现 | 大话正则表达式 | 云API平台的设计与实现 | 个税改了,工资少了,不要慌!文末附计算器
关注我们的公众号
长按识别二维码关注我们

