




背景
面临着各个业务系统中的产生的海量数据,我们有时候不得不在这些海量数据中分析出有用的信息用来做决策分析或报表等,比如我们需要分析出数据录入部门每天产生的几十万数据(有些来自爬虫)从binlog中分析出人工每天录入数据多少,审核数据多少,哪些表比较活跃,传统的做法有可能我们需要改造数据录入系统,将相关业务耦合在业务系统中,有了Flink,我们可以在不改动业务系统的情况下,通过binlog解析程序将数据发往kafka消息中心,通过我们设计的这套系统,通过简单的类似SQL的语句汇总得到相关结果。
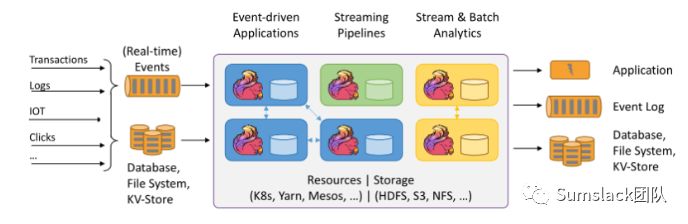
设计
通过上图的flink架构图我们可以知道,如果要编写一个实时流计算的结果程序将起存入MySQL数据库,我们需要做以下步骤:
编写数据源解析程序,将数据源以统一的如JSON格式,放入kafka或其他消息队列中;
编写数据源处理程序,将kafka消息中心的消息通过解析,map,flatmap,filter等一系列操作,得到我们所需的数据流(需要参与计算的基础数据);
通过一系列的sum,avg或其他聚合计算从第二步的数据流中得到聚合结果;
编写一个sink程序,将聚合结果保存到诸如MySQL中;
如果要写一个实时的流计算都要经过上述复杂的开发步骤,那么对于终端开发使用者来说,就太繁琐了,所以聪明的阿里人基于flink提供了一个分支blink,里面将流的操作封装了一系列的Table API,这样开发一个流计算就会被简化成编写SQL(扩展了SQL语法),结合blink思路,如果我们设计一套自己的流处理平台,可以将上述步骤考虑成:
通过create table语句定义流数据的消息来源,比如在我们设计的系统中,如下SQL:
create table mytable(
db varchar(64),
tbl varchar(64),
es bigint comment '{water:true,offset:1000}'
) comment '{type:"kafka10",bootstrapServers:"xxxx",zk:"yyyy",offsetRest:"earliest",groupId:"zzz",topic="test",paralleism:1}';
用来处理从kafka10版本在指定的服务器上从头开始接收消息,其中消息队列名为test,组名test,处理并行度1,并将流结果注册成表名mytable供后续分析,其中定义了每个字段的类型,并将es字段的值设置为水位,偏移量为1秒。
接下去只需要将第一步获取的表数据直接进行聚合计算即可,如我们可以定义如下SQL
insert into test10(myname,myname2,tt)
select db,tbl,count(*) as num FROM mytable group by db,tbl
将mytable表针对db,tbl字段分组,并统计每个库每个表增量数据的变化将结果存放到test10统计结果表中。其中在我们设计的数据表中还指定了sink_id=1,则将结果存放到指定库的指定表中。


提交Job,交给Flink执行即可。
从上述我们设计的思路中可看出,开发流计算程序我们在一般情况下都无需编写代码,通过我们提供的web控制台定义相关SQL和设置,即可交给Flink执行计算任务,如果你要取计算结果,可以从指定的sink的存储地方如MySQL中获取结果。
实现
按以上的设计思路,我们可以较简单的实现一个程序模型,首先由一个IJobTask接口,用来启动计算任务,启动一个计算任务的代码如下:
//taskSink这是根据数据库计算任务信息得到的对象,如图 - 计算任务表
IJobTask jobTask = new JobTask(taskSink);
jobTask.bindConsumer();
jobTask.bindSink();
jobTask.exec();
由于数据来源可以来自包括kafka/mysql/log4j等,所以我们可以定义一个ITaskConsumer接口,然后编写不同的实现类,并定义一个抽象类AbsTaskConsumer用于实现数据来源处理中的一些抽象公共保护方法,Sink的实现思路类似,所以JobTask内部类的实现思路非常简单:
public class JobTask extends AbsJobTask{
private AbsTaskConsumer consumer = null;
private AbsTaskSink sink = null;
private JobTask() {}
public JobTask(JobTaskBean task) {
this.task = task;
}
@Override
public void bindConsumer() {
TaskEnv.env.setStreamTimeCharacteristic(TimeCharacteristic.EventTime);
TaskEnv.env.getCheckpointConfig().setCheckpointingMode(CheckpointingMode.EXACTLY_ONCE);
if(task.getConsumer().getConsumerType() == ConsumerType.KAFKA10) {
consumer = new ConsumerKafka10();
}else if(task.getConsumer().getConsumerType() == ConsumerType.KAFKA111) {
consumer = new ConsumerKafka111();
}
if(consumer!=null) {
consumer.bindTask(this);
}
}
@Override
public void bindSink() {
if(task.getSink().getSinkType() == SinkType.MYSQL) {
sink = new TaskSinkMySQL();
sink.bindTask(this);
}
}
}
以上我们只实现了数据来源来自于KAFKA10版本和KAFAKA1.1.1版,其他数据来源可以编写相应实现类。Sink类似,我们实现了一个存储到MySQL的TaskSinkMySQL实现类,如果要把计算结果存储到Redis等可任意扩展。
在实现的过程中我们还需要使用到如下技术:
SQL解析:我们需要将create table的SQL语句解析出结果,根据SQL语句中提取出每个字段类型和字段名,以便转换为对应的Flink Table API,我们这里使用Druid SQL解析库。
kafka命令语句:模拟生产数据,可参考《Apache Flink开发概述》。
Flink SQL语法:https://ci.apache.org/projects/flink/flink-docs-release-1.8/dev/table/sql.html
实例
我们实现一个从kafka10从获取json数据,其中tt设置为水位字段,偏移量1000,我们统计当天每分钟新增的数据量,比如有如下数据:
{myname:"xxx",tt:"2019-06-14 10:00:00"}
{myname:"xxx",tt:"2019-06-14 10:00:30"}
{myname:"xxx",tt:"2019-06-14 10:01:14"}
{myname:"xxx",tt:"2019-06-14 10:01:12"}
{myname:"xxxx",tt:"2019-06-14 10:02:25"}
统计结果应该是:
2019-06-14 10:00 2
2019-06-14 10:01 2
2019-06-14 10:02 1
我们在系统中,只要新建一个计算任务,然后选择采用kafka10作为数据源方式,以mysql作为sink,定义一个接收消息的消息队列名就可以了,最后定义两个SQL:
# 定义json格式的字段类型,以tt作为水位字段,延迟200毫秒
create table tc_13(
myname varchar(64),
tt timestamp comment '{water:true,offset:200}'
);
# 滑动窗口模式,每分钟汇总数据条数
insert into stat_demo(dt,num)
select TUMBLE_START(rowtime, INTERVAL '1' MINUTE) as dt,count(myname) as num
from tc_13
GROUP BY TUMBLE(rowtime, INTERVAL '1' MINUTE)
在Linux命令行中输入测试数据:
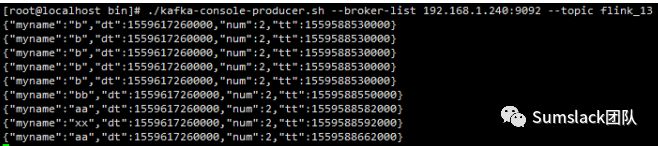

不是很简单?按这个思路,实现您自己的大数据计算分析平台吧:)
你可以继续阅读:
一款自动生成后台代码的管理系统的设计与实现 | “大”中台,“小”前端的架构演变| 云服务平台中推送服务的设计与实现 | 对微服务的理解以及实现一套微服务对外发布API管理平台 | 项目开发中常用的设计模式整理 | 异构语言调用平台的设计与实现 | 大话正则表达式 | 云API平台的设计与实现 | 个税改了,工资少了,不要慌!文末附计算器
关注我们的公众号
长按识别二维码关注我们

