




概述
Apache Flink 是德国柏林工业大学的几个博士生和研究生从学校开始做起来的项目,之前叫做 Stratosphere
。他们在2014 年开源了这个项目,起名为 Flink
。Flink
是一个低延迟、高吞吐、统一的大数据计算引擎,在阿里巴巴的生产环境中,Flink
的计算平台可以实现毫秒级的延迟情况下,每秒钟处理上亿次的消息或者事件。比如在阿里内部,2018 年双十一,Flink
引擎完美的支撑了高达 17 亿每秒的流量洪峰。
Apache Flink
已经被业界公认是最好的流计算引擎。然而 Flink 其实并不是一个仅仅局限于做流处理的引擎。Apache Flink
的定位是一套兼具流、批、机器学习等多种计算功能的大数据引擎。
开发
唯一的要求是使用Maven 3.0.4(或更高版本)和Java 8.x安装。
入门实例
本例子我们首先用来计算某个本地文件内容出现的单词次数统计,然后根据分布式消息队列传输过来的数据实时统计单词次数,并将最终结果在文件磁盘或消息队列内实时显示。
根据maven原型项目创建maven项目(以下是flink 1.8版本为例):
mvn archetype:generate -DarchetypeGroupId=org.apache.flink -DarchetypeArtifactId=flink-quickstart-java -DarchetypeVersion=1.8.0
在Java开发工具中导入该maven项目,如果项目中未出现maven依赖包,则在项目文件夹打开classpath
文件,加入:
<classpathentry exported="true" kind="con" path="org.eclipse.m2e.MAVEN2_CLASSPATH_CONTAINER">
<attributes>
<attribute name="maven.pomderived" value="true"/>
<attribute name="org.eclipse.jst.component.dependency" value="/WEB-INF/lib"/>
</attributes>
</classpathentry>
重新刷新项目即可。
项目中默认给出了一个批任务和流任务的两个Java类,比如我们编写一个输入任意文件,执行输出文件中统计单词出现个数的例子如下(实现思路:读取文件内容,按行split出每个单词,利用platmap一对多转换成Tuple2对象,并将流输出结果输出到输出文件夹下):
public static void main(String[] args) throws Exception {
final ParameterTool params = ParameterTool.fromArgs(args);
final StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.getConfig().setGlobalJobParameters(params);
DataStream<String> text = env.readTextFile(params.get("input"));
DataStream<Tuple2<String, Integer>> counts =
text.flatMap(new Tokenizer())
//groupby二元组中的第一个字段,按第二个字段的值求和得出每个单词的出现次数
.keyBy(0).sum(1);
counts.writeAsText(params.get("output"));
env.execute("Streaming WordCount");
}
//每行按空格分割获取每个单词并初始化第二个字段的值为1,形如<hello,1>的二元组
public static final class Tokenizer implements FlatMapFunction<String, Tuple2<String, Integer>> {
@Override
public void flatMap(String value, Collector<Tuple2<String, Integer>> out) {
// normalize and split the line
String[] tokens = value.toLowerCase().split("\\W+");
for (String token : tokens) {
if (token.length() > 0) {
out.collect(new Tuple2<>(token, 1));
}
}
}
}
以上例子我们实现了根据本地文件内容统计文件单词出现次数的程序,那么,如果大数据来自消息队列应该如何来处理呢,比如来自kafka消息队列
,首先安装好kafka
集群环境,kafka
依赖zookeeper
,以下是我们开发环境集群环境:
zookeeper
:192.168.1.x:2181,192.168.1.y:2181kafka
:192.168.1.x:9092,192.168.1.y:9092
因为我们要模拟数据来自kafka
,那还需要数据的生产者,可以使用kafka
的命令行,以下命令行是有用的:
查看当前kafaka队列名:
./kafka-topics.sh --zookeeper 192.168.1.x:2181,192.168.1.y:2181 --list
创建kafaka的topic:
./kafka-topics.sh --zookeeper 192.168.1.x:2181,192.168.1.y:2181 --create --topic flink-demo --partitions 30 --replication-factor 2
查看指定topic信息:
./kafka-topics.sh --zookeeper 192.168.1.x:2181,192.168.1.y:2181 --describe --topic flink-demo
查看所有topic列表:./kafka-topics.sh --zookeeper 192.168.1.x:2181,192.168.1.y:2181 --list
生产kafaka数据:
./kafka-console-producer.sh --broker-list 192.168.1.x:9092 --topic flink-demo
控制台消费数据:
./kafka-console-consumer.sh --zookeeper 192.168.1.x:2181,192.168.1.y0:2181 --topic flink-demo --from-beginning
查看组下topic消费信息:
./kafka-consumer-groups.sh --bootstrap-server 192.168.1.x:9092 --describe --group transaction
那么以上的程序我们就可以改写为:
public static void main(String[] args) throws Exception {
final StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setStreamTimeCharacteristic(TimeCharacteristic.EventTime);
env.enableCheckpointing(1000);
env.getCheckpointConfig().setCheckpointingMode(CheckpointingMode.EXACTLY_ONCE);
Properties properties = new Properties();
properties.setProperty("bootstrap.servers", "192.168.1.x:9092");
// only required for Kafka 0.8
properties.setProperty("zookeeper.connect", "192.168.1.y:2181");
properties.setProperty("group.id", "transaction");
//接收kafaka消息并统计单词出现次数
DataStream<String> stream = env
.addSource(new FlinkKafkaConsumer010<>("flink-test", new SimpleStringSchema(), properties));
//转换
DataStream<Tuple2<String, Integer>> counts =
stream.flatMap(new Tokenizer())
.keyBy(0).sum(1);
counts.writeAsText("f:/kafaka-out");
env.execute("hello world");
}
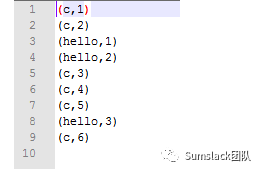
使用./kafka-console-producer.sh --broker-list 192.168.1.x:9092 --topic flink-托尔斯泰,
在kafka
用命令行不断生产数据,我们就可以在f:/kafaka-out
下看到单词出现次数统计了,而是是实时的,如下图:
如果我们想要把最终的结果发往kafka,然后让其他程序消费,我们只需要为最终的输出增加一个sink即可,代码如下:
private static final String KAFKA_PRODUCER_TOPIC = "flink-o";
Properties KAFKA_PROP = new Properties();
KAFKA_PROP.setProperty("bootstrap.servers", "192.168.1.x:9092");
KAFKA_PROP.setProperty("zookeeper.connect", "192.168.1.y:2181");
KAFKA_PROP.setProperty("group.id", "flink");
DataStream<String> counts2 = counts.map( s -> s.getField(0)+"==>" + s.getField(1));
counts2.addSink(new FlinkKafkaProducer010<String>(KAFKA_PRODUCER_TOPIC,new SimpleStringSchema(),KAFKA_PROP));
可以在kafka服务器用控制台消费对应的kafka队列:
./kafka-console-consumer.sh --bootstrap-server 192.168.1.x:9092 --topic flink-o --from-beginning --partition 0
开一个控制台生产单词,如下:
./kafka-console-producer.sh --broker-list 192.168.1.x:9092 --topic flink-test
这样在不断生产单词的情况下,对应的消费控制台能不断的收到最新的单词统计数据,如下:
生产单词端(不断的输入单词,自动汇总):

消费端(可以将结果输出到Web或其他终端):

Flink目前已被包括BAT,滴滴,美团等众多互联网公司中使用,所以用它来处理批/流计算是一个不错的选择。
你可以继续阅读:
一款自动生成后台代码的管理系统的设计与实现 | “大”中台,“小”前端的架构演变| 云服务平台中推送服务的设计与实现 | 对微服务的理解以及实现一套微服务对外发布API管理平台 | 项目开发中常用的设计模式整理 | 异构语言调用平台的设计与实现 | 大话正则表达式 | 云API平台的设计与实现 | 个税改了,工资少了,不要慌!文末附计算器
关注我们的公众号
长按识别二维码关注我们

