





Python的pivot函数用来重塑数据,官方定义如下所示
pivot(index=None, columns=None, values=None)
index: 可选参数。设置新dataframe的行索引,如果未指明,就用当前已存在的行索引。
columns:必选参数。用来设置作为新dataframe的列索引。
values:可选参数。在原dataframe中选中某一列/几列的值,使其在新dataframe的列里显示。如果不指定,则默认将原dataframe中所有的列都显示,这里需要注意:为了将所有的值都显示出来,就会出现多层行索引的情况。
示例如下
df = pd.DataFrame({'A': ['one', 'one', 'two', 'three'] * 3, 'B': ['G', 'H', 'K'] * 4, 'C': ['foo', 'foo', 'foo', 'bar', 'bar', 'bar'] * 2, 'D': np.random.randn(12), 'E': np.random.randn(12)})
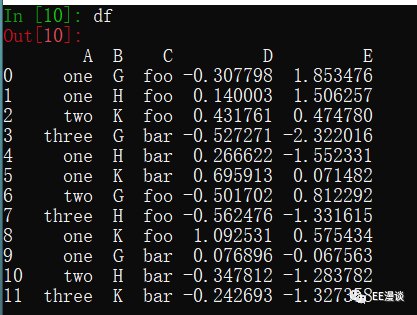
不设置行索引(不指定index),设置新的列索引为B,values取C,如下所示
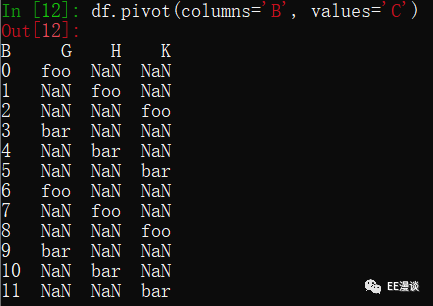
指定values为C和D时,C和D就变成了层次化的列索引。如下图所示
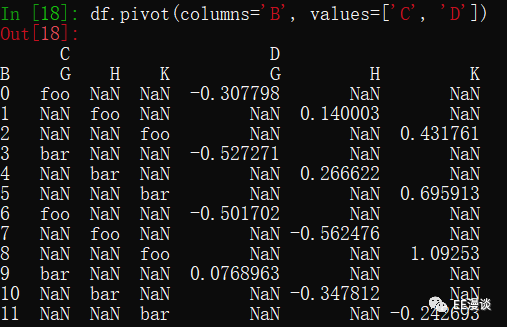
其实可以这样理解:上图为 values只为C时的结果+ values只为D时的结果
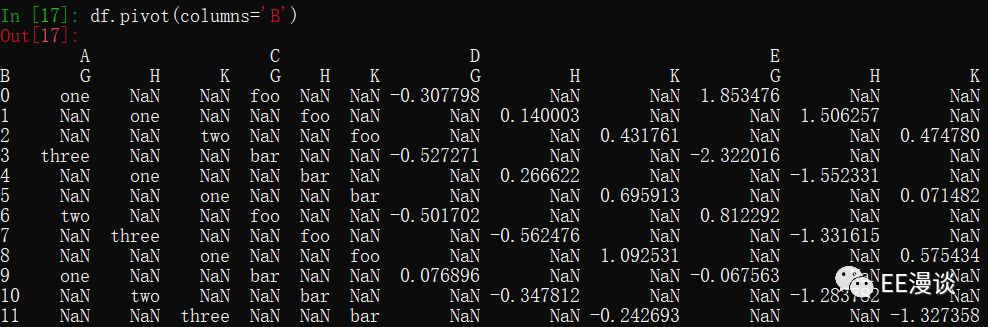
values值取默认时,如下所示(values=A +C +D +E)
使用pivot函数,如果index或者columns中出现了多重值的情况,就会出错。
ValueError: Index contains duplicate entries, cannot reshape
举例如下:df.pivot(index='A', columns='B', values='D')
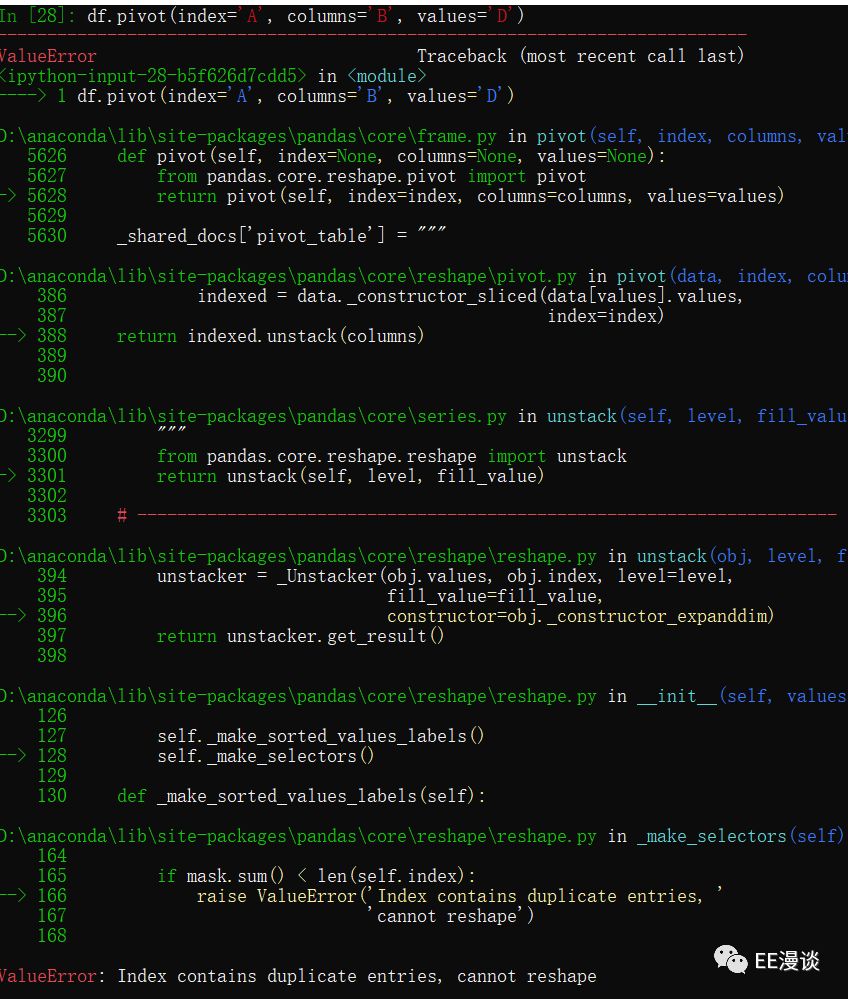
这是为什么呢?设置df 的index为A,在对df进行reshape时,A列的‘one’需要进行合并,如下图所示
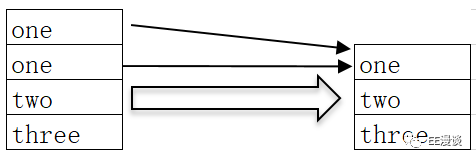
设置columns为B,则B列的G,H,K列开始合并,如下图所示
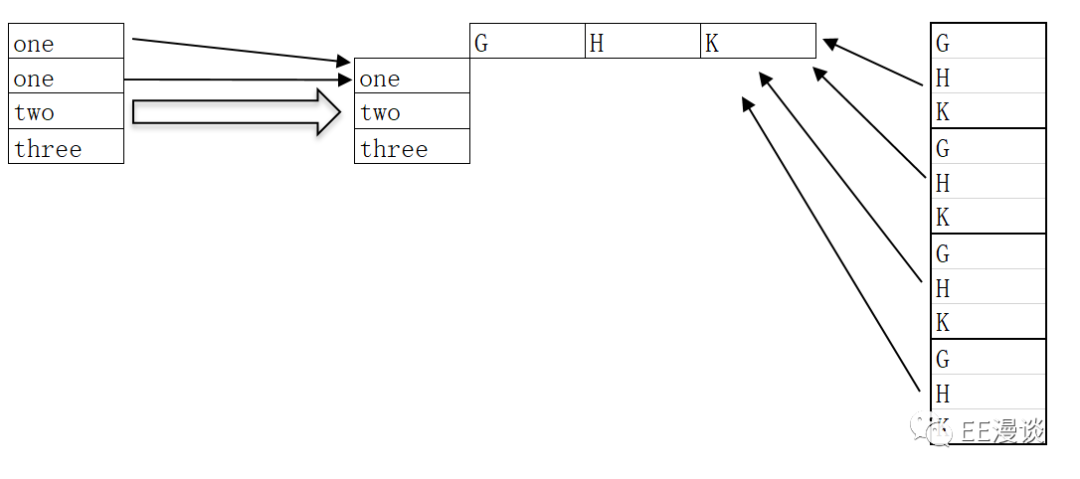
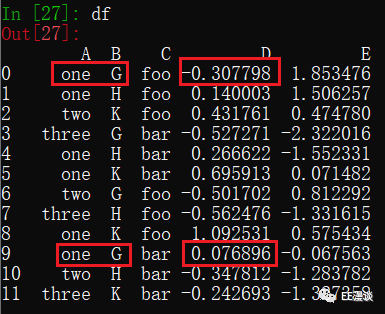
设置values值为D,此时就会出现问题:one和G对应的数值到底是-0.3,还是0.07呢?Python无法进行分辨,就会报错。
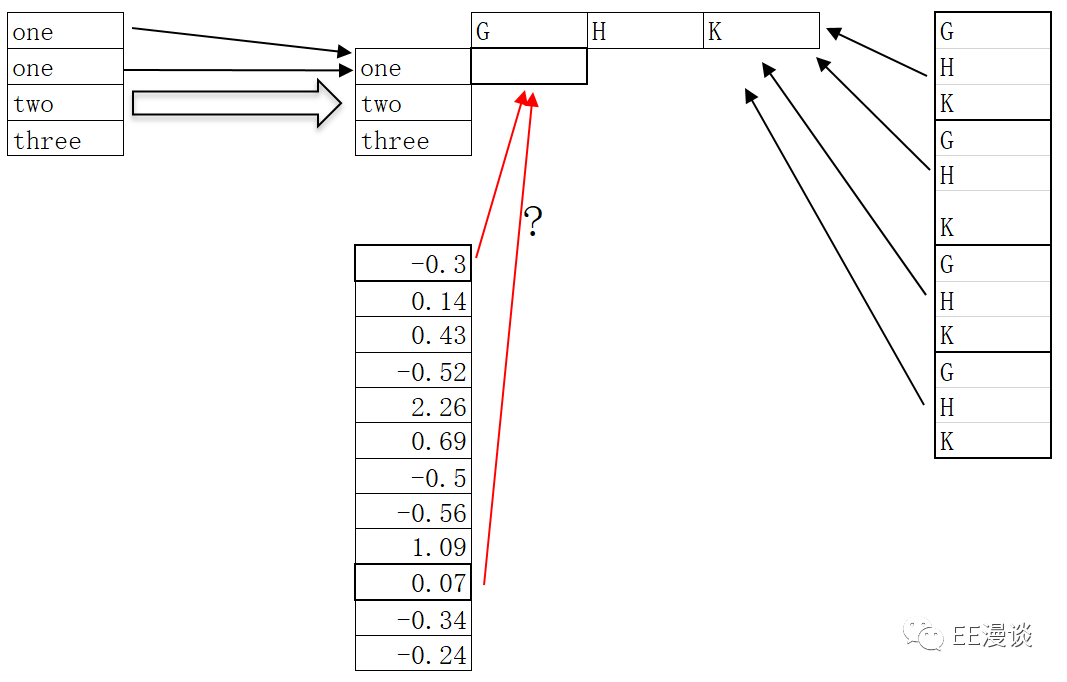
通过上面的分析,就可以发现pivot函数就是set_index()和unstack()函数的集合。

df.set_index([‘B’, ’D’])
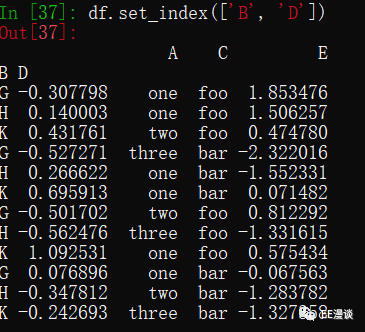
再将D列unstack,就与pivot效果完全相同

通过以上的学习,你掌握pivot的用法了么?
