




学习目标
学习openGauss收集统计信息、打印执行计划、垃圾收集和checkpoint
课程学习
连接数据库
su - omm
gsql -r

课后作业
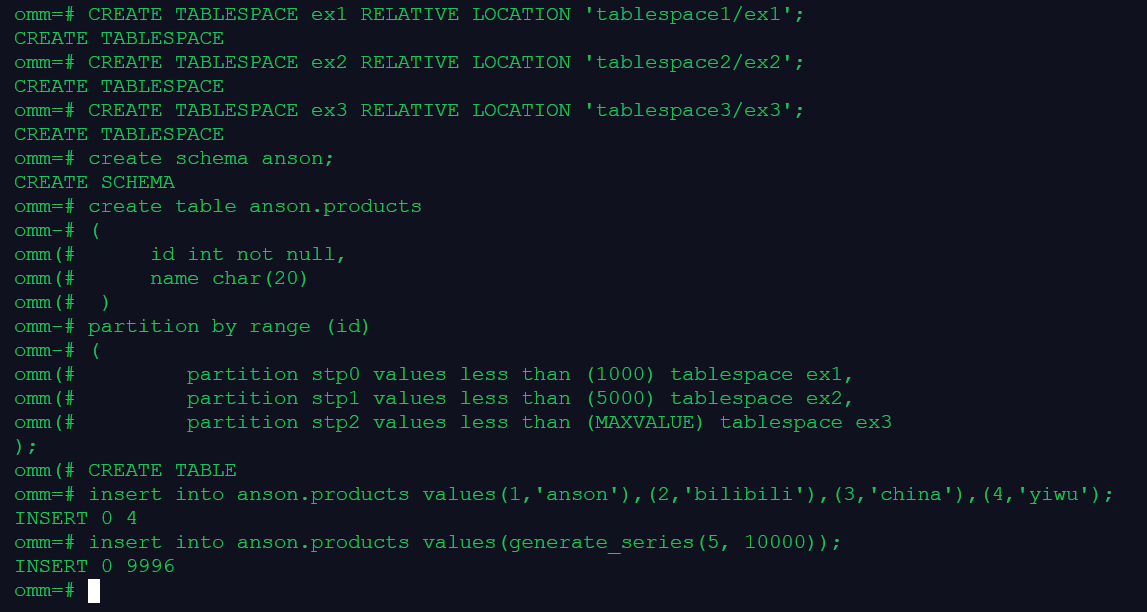
1.创建分区表,并用generate_series(1,N)函数对表插入数据
CREATE TABLESPACE ex1 RELATIVE LOCATION 'tablespace1/ex1';
CREATE TABLESPACE ex2 RELATIVE LOCATION 'tablespace2/ex2';
CREATE TABLESPACE ex3 RELATIVE LOCATION 'tablespace3/ex3';
create schema anson;
create table anson.products
(
id int not null,
name char(20)
)
partition by range (id)
(
partition stp0 values less than (1000) tablespace ex1,
partition stp1 values less than (5000) tablespace ex2,
partition stp2 values less than (MAXVALUE) tablespace ex3
);
insert into anson.products values(1,'anson'),(2,'bilibili'),(3,'china'),(4,'yiwu');
insert into anson.products values(generate_series(5, 10000));
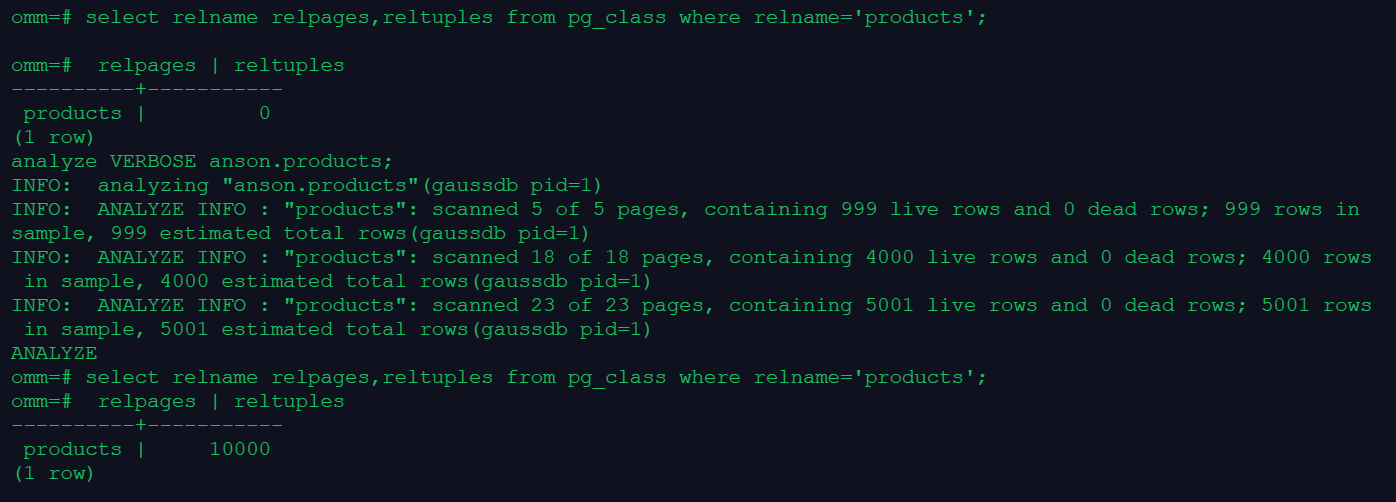
2.收集表统计信息
select relname relpages,reltuples from pg_class where relname='products';
analyze VERBOSE anson.products;
select relname relpages,reltuples from pg_class where relname='products';
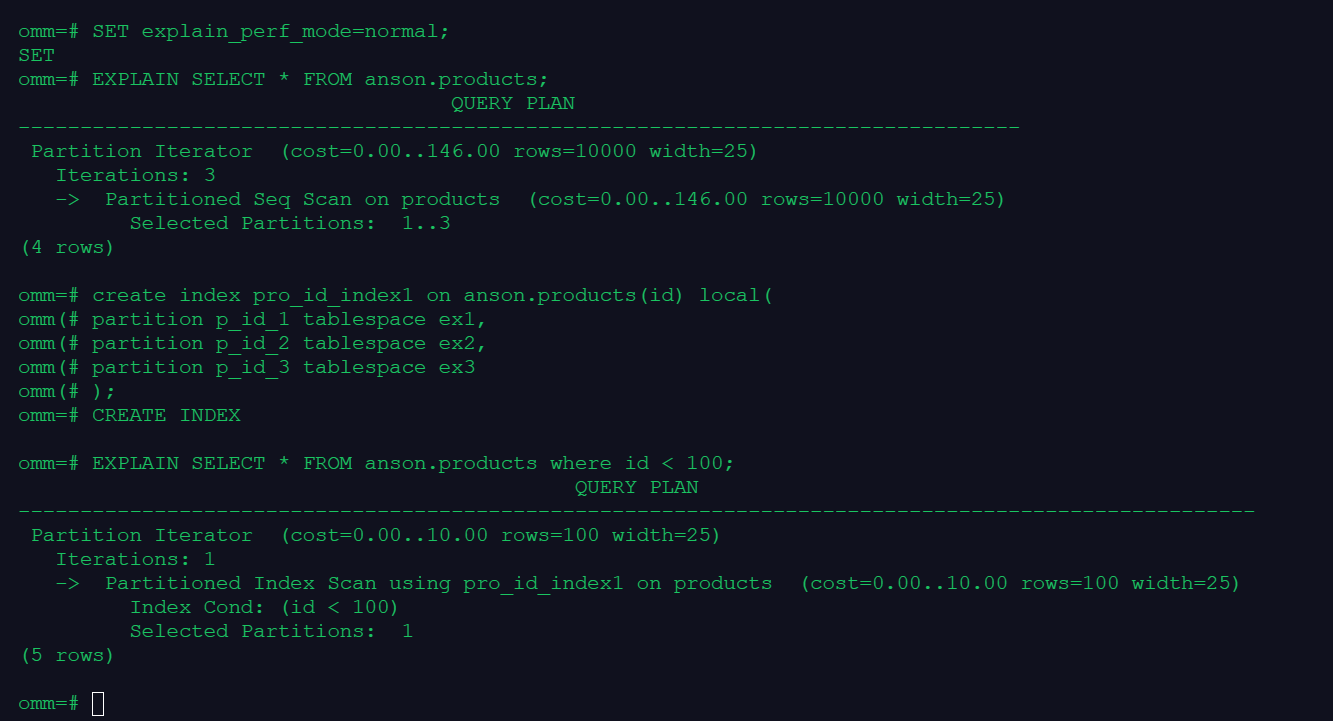
3.显示简单查询的执行计划;建立索引并显示有索引条件的执行计划
SET explain_perf_mode=normal;
EXPLAIN SELECT * FROM anson.products;
create index pro_id_index1 on anson.products(id) local(
partition p_id_1 tablespace ex1,
partition p_id_2 tablespace ex2,
partition p_id_3 tablespace ex3
);
EXPLAIN SELECT * FROM anson.products where id < 100;
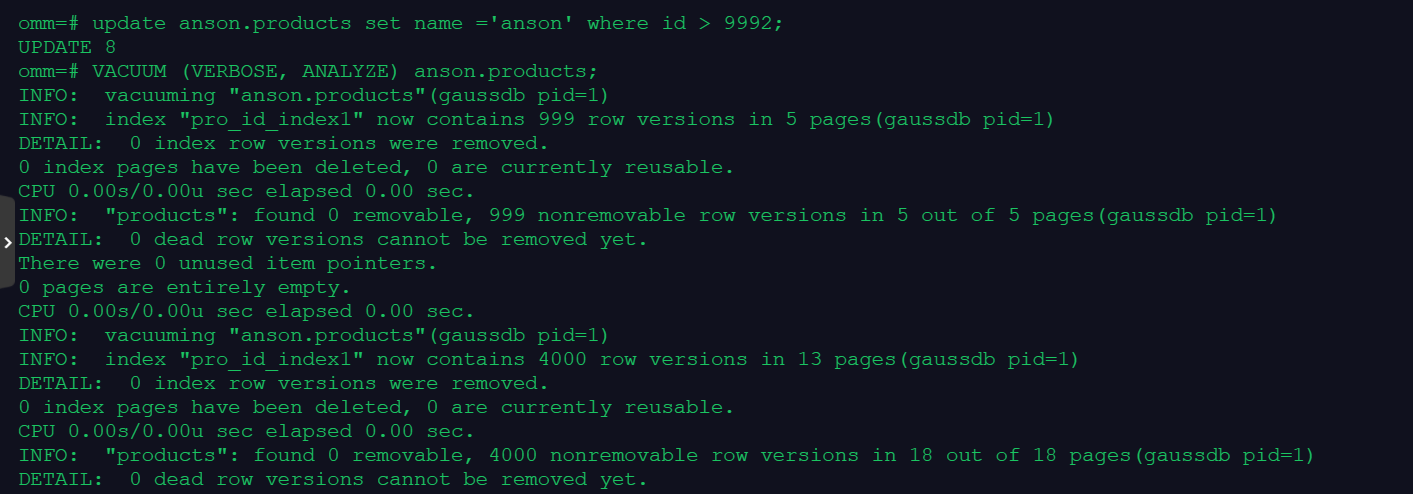
4.更新表数据,并做垃圾收集
update anson.products set name ='anson' where id > 9992;
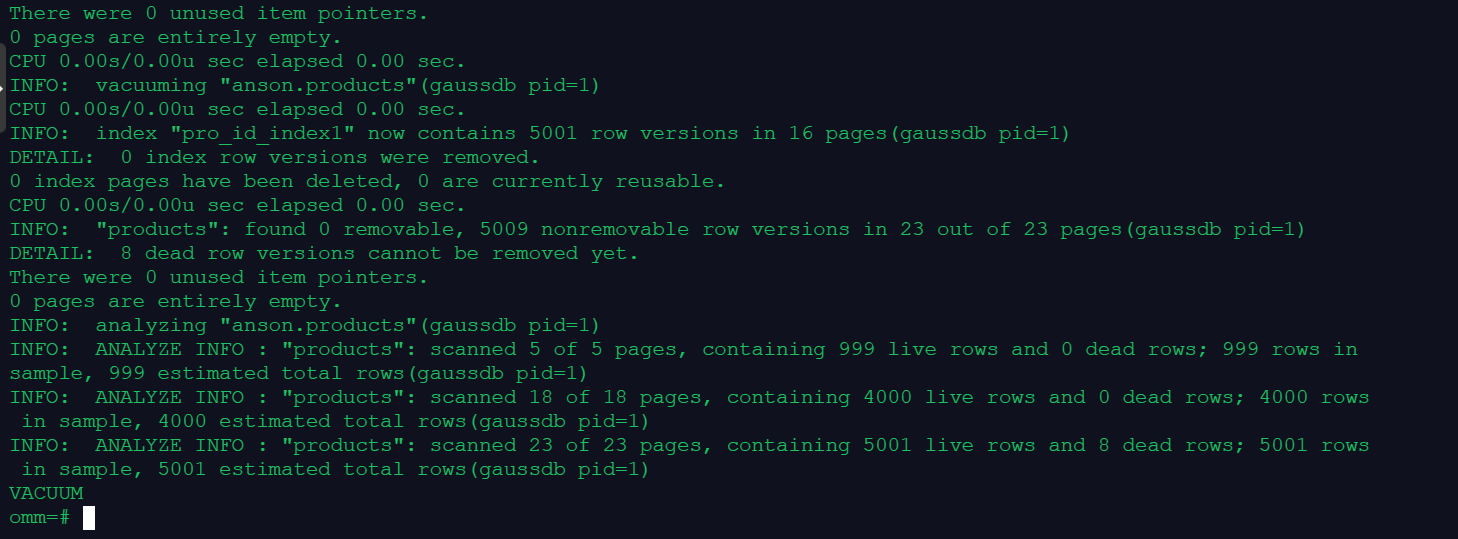
VACUUM (VERBOSE, ANALYZE) anson.products;
5.清理数据
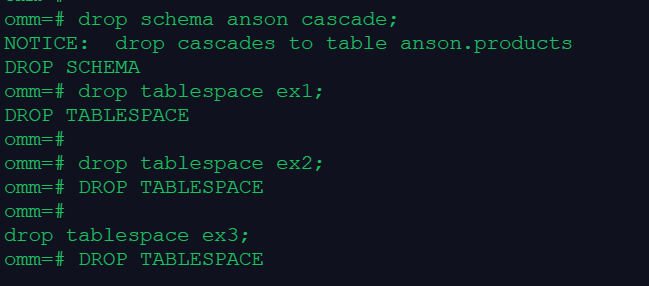
drop schema anson cascade;
drop tablespace ex1;
drop tablespace ex2;
drop tablespace ex3;
写在最后
19天咯,结合之前学习的知识点,完成今天的作业,很享受整个学习的过程,既充实又满足,积累知识点,触类旁通,今天学的是openGauss收集统计信息、打印执行计划、垃圾收集和checkpoint,让人非常期待完成所有课程,更加了解openGauss数据库,同时知悉各数据库的异同之处,能顺畅的使用openGauss数据库,期待国产数据库越来越强大。
最后修改时间:2021-12-22 09:39:22
「喜欢这篇文章,您的关注和赞赏是给作者最好的鼓励」
关注作者
【版权声明】本文为墨天轮用户原创内容,转载时必须标注文章的来源(墨天轮),文章链接,文章作者等基本信息,否则作者和墨天轮有权追究责任。如果您发现墨天轮中有涉嫌抄袭或者侵权的内容,欢迎发送邮件至:contact@modb.pro进行举报,并提供相关证据,一经查实,墨天轮将立刻删除相关内容。
