




分布式环境下创建表
一. 使用OMM用户在任意一下CN实例所在的服务器上进行登录,并创建测试用户
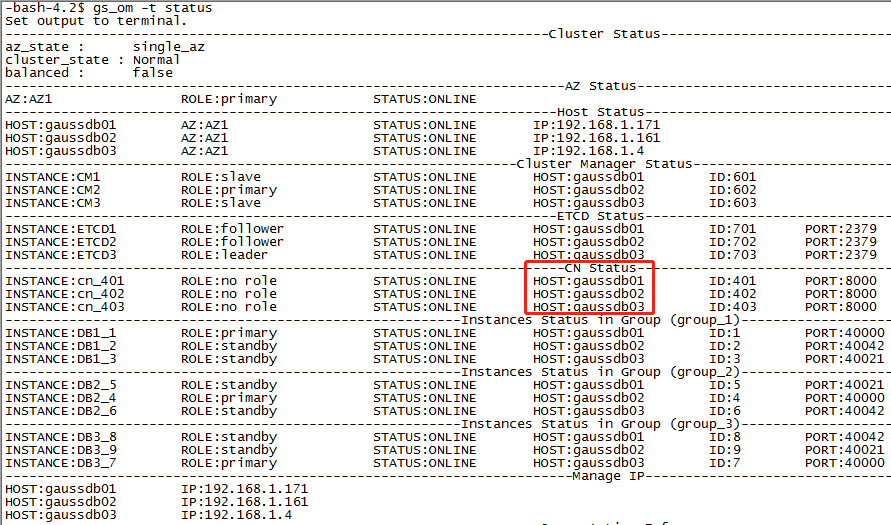
这是一个三节点的分布式集群环境,每个主机上有一个CN,一个主DN,两个从DN。
创建用户:
zsql omm/gaussdb_123@127.0.0.1:8000
create user enmotest identified by Changeme_123;
grant connect,dba,select any table to enmotest;
这一步有几个细节需要注意:
- 连接的是CN实例,而不是DN,如果连到DN上创建用户,那么这个用户及用户下的表不是集群范围可见,相当于单机环境,达不到分布式的目的
- 要用omm用户(建库时使用的用户)连接创建,而不是本机登录,也不是sys用户,否则会遇到如下尴尬的GS-00781报错:
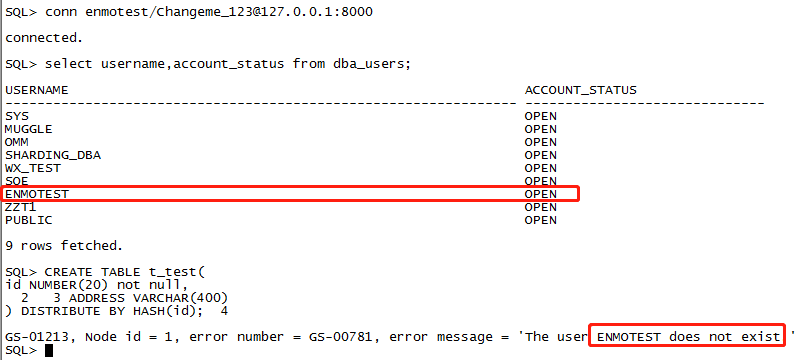
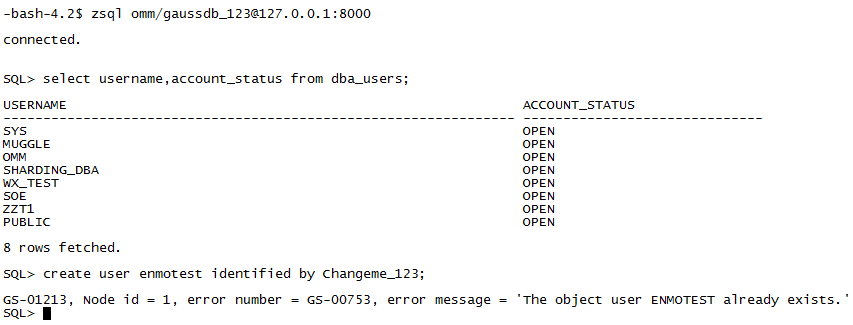
- 保证创建的用户名在现有的环境中是不存在的,例如,现在的主DN中不能已经存在enmotest用户名,否则用CN创建时会提示用户已存在:
二. 建表并插入测试数据
在分布式环境下建表时需要指定DISTRIBUTE BY关键字。
CREATE TABLE t_test(
id NUMBER(20) not null,
ADDRESS VARCHAR(400)
) DISTRIBUTE BY HASH(id); --表示按id字段分布存储数据
SQL> insert into t_test select object_id,object_name from dba_objects;
1200 rows affected.
SQL> insert into t_test select * from t_test;
1200 rows affected.
SQL> insert into t_test select * from t_test;
2400 rows affected.
SQL> insert into t_test select * from t_test;
4800 rows affected.
SQL> insert into t_test select * from t_test;
9600 rows affected.
SQL> insert into t_test select * from t_test;
19200 rows affected.
SQL> commit;
多插入几次,生成接近20000行数据。
三. 运行模拟查询语句,观察三个节点的性能
SQL> select count(1) from t_test a,t_test b;
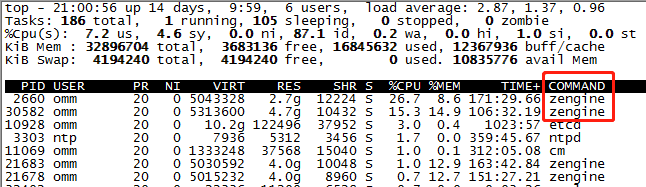
语句运行时,三个节点上都有负载产生:
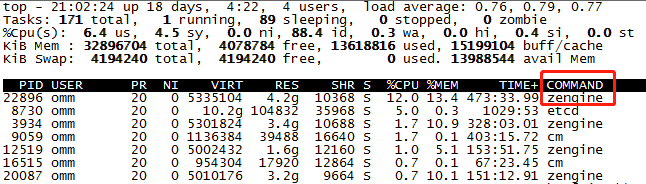
节点一:可以观察到有两个zengine进程在工作,其中2600是cn(sql发起方),30582是dn
节点二:只有一个dn进程在工作

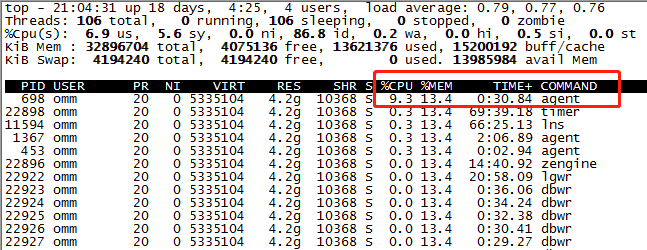
用top -H -p 22896观察进程中的线程运行情况,可以看到真正在干活的是一个agent的线程:
节点三:情况与节点二类似
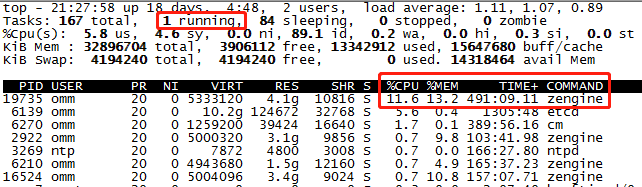
这是高斯数据库share-nothing分布式架构的优势,把数据打散到各个节点,然后各个节点进行分布式查询处理,降低查询时节点之间的数据流动,又能提升查询效率。
用如下代码,模拟插入一张一千万纪录的表:
begin
for i in 1..10000000 loop
insert into t_test values(i,lpad('test',100,'a'));
end loop;
commit;
end;
/
语法和oracle完全兼容。
一千万数据平均分布到三个DN节点中,如:
进入到节点一的dn中查询:
zsql omm/gaussdb_123@127.0.0.1:40000
SQL> select count(1) from enmotest.t_test;
COUNT(1)
--------------------
3333216
说明:参照gs_om -t status的信息,40000端口是节点一上dn实例(DB1_1)的端口。
Oracle单实例查询,耗时11秒:
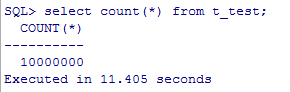
Gauss分布式查询,耗时1.1秒
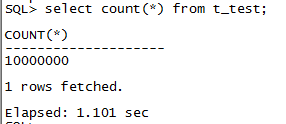
以上测试场景不严格,不用于对比高斯和Oracle的性能,环境不一样,也说明不了问题。
最后修改时间:2020-02-18 08:28:57
「喜欢这篇文章,您的关注和赞赏是给作者最好的鼓励」
关注作者
【版权声明】本文为墨天轮用户原创内容,转载时必须标注文章的来源(墨天轮),文章链接,文章作者等基本信息,否则作者和墨天轮有权追究责任。如果您发现墨天轮中有涉嫌抄袭或者侵权的内容,欢迎发送邮件至:contact@modb.pro进行举报,并提供相关证据,一经查实,墨天轮将立刻删除相关内容。
