




今天学习openGauss收集统计信息、打印执行计划、垃圾收集和checkpoint,以下是作业和心得:
1. 连接openGauss
su - omm gsql -r
2. 创建分区表,并用generate_series(1,N)函数对表插入数据
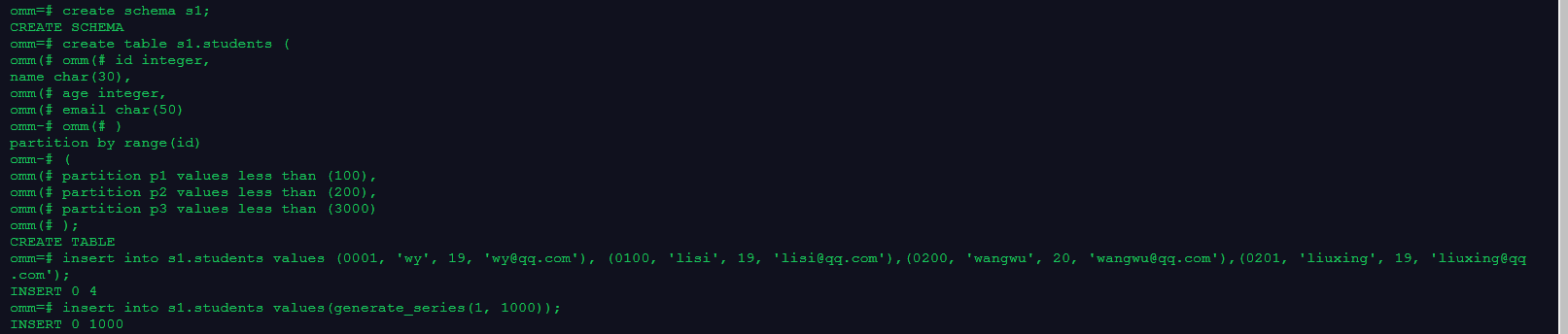
create schema s1;
create table s1.students (
id integer,
name char(30),
age integer,
email char(50)
)
partition by range(id)
(
partition p1 values less than (100),
partition p2 values less than (200),
partition p3 values less than (3000)
);
insert into s1.students values (0001, 'wy', 19, 'wy@qq.com'), (0100, 'lisi', 19, 'lisi@qq.com'),(0200, 'wangwu', 20, 'wangwu@qq.com'),(0201, 'liuxing', 19, 'liuxing@qq.com');
insert into s1.students values(generate_series(1, 1000));
/
3. 收集表统计信息
select relname, relpages, reltuples from pg_class where relname = 'students';
analyze VERBOSE s1.students;
select relname, relpages, reltuples from pg_class where relname = 'students';
/

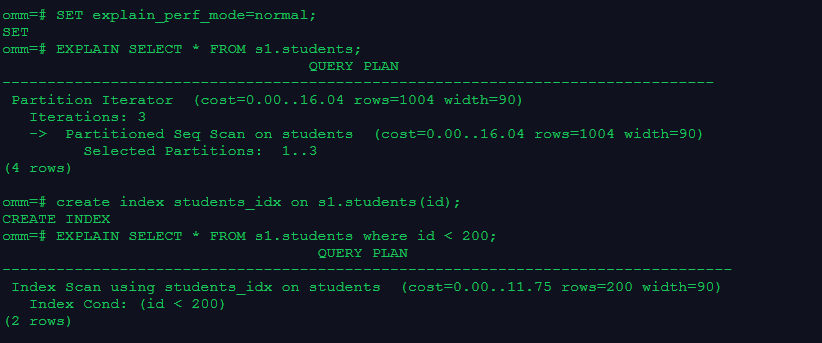
4. 显示简单查询的执行计划;建立索引并显示有索引条件的执行计划
SET explain_perf_mode=normal;
EXPLAIN SELECT * FROM s1.students;
create index students_idx on s1.students(id);
EXPLAIN SELECT * FROM s1.students where id < 200;
/
5. 更新表数据,并做垃圾收集
update s1.students set id = id + 1 where id < 100;
VACUUM (VERBOSE, ANALYZE) s1.students;
/
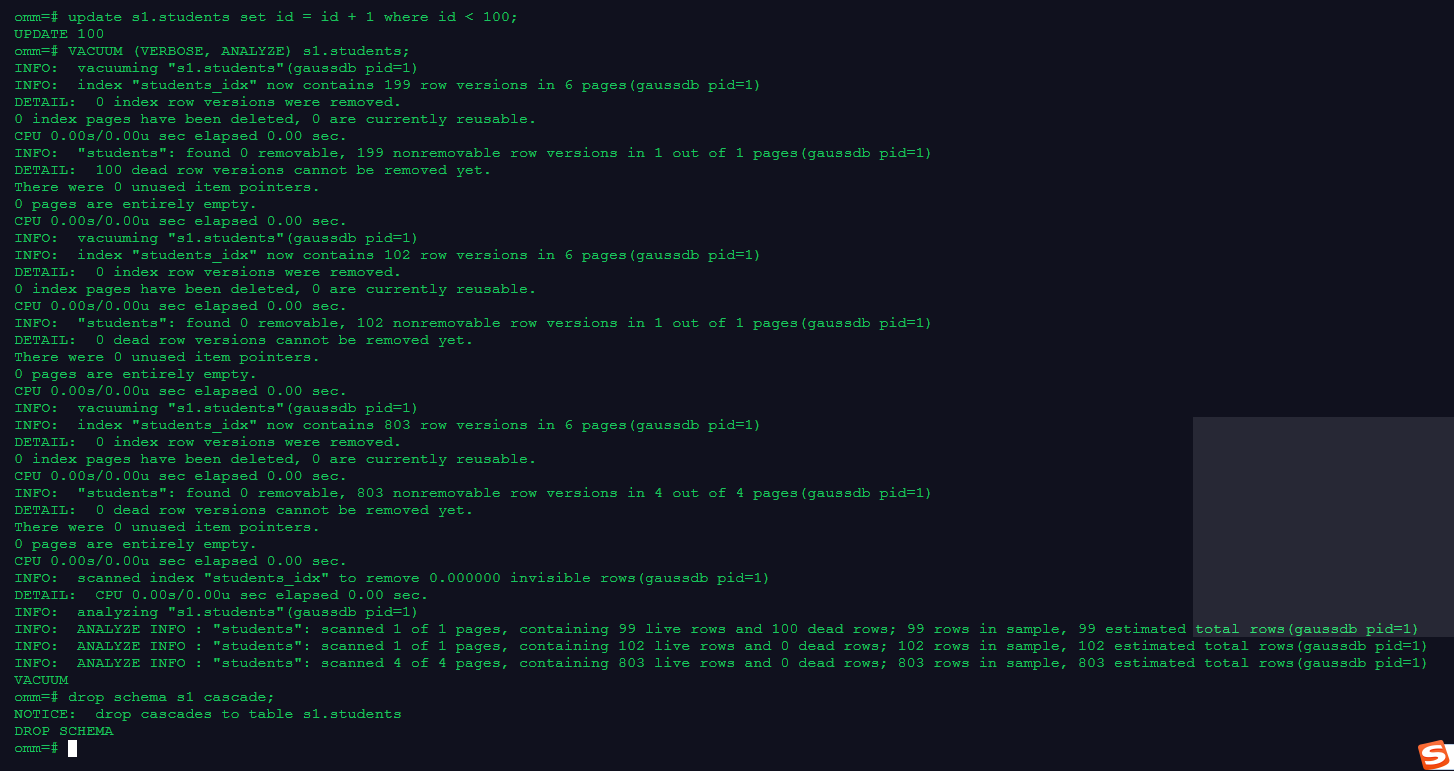
6. 清理数据
drop schema s1 cascade;
/
通过学习和作业,巩固了openGauss收集统计信息、打印执行计划、垃圾收集和checkpoint的知识。对于ANALYZE收集统计信息,目前仅支持行存表、列存表。默认收集统计信息的采样比例是30000行(即: guc参数default_statistics_target默认设置为100),如果表的总行数超过一定行数(大于1600000),建议设置guc参数default_statistics_target为-2,即按2%收集样本估算统计信息。
对于在批处理脚本或者存储过程中生成的中间表,也需要在完成数据生成之后显式的调用ANALYZE。
对于表中多个列有相关性且查询中有同时基于这些列的条件或分组操作的情况,可尝试收集多列统计信息,以便查询优化器可以更准确地估算行数,并生成更有效的执行计划。
「喜欢这篇文章,您的关注和赞赏是给作者最好的鼓励」
关注作者
【版权声明】本文为墨天轮用户原创内容,转载时必须标注文章的来源(墨天轮),文章链接,文章作者等基本信息,否则作者和墨天轮有权追究责任。如果您发现墨天轮中有涉嫌抄袭或者侵权的内容,欢迎发送邮件至:contact@modb.pro进行举报,并提供相关证据,一经查实,墨天轮将立刻删除相关内容。
