




使用generate_series插入数据:
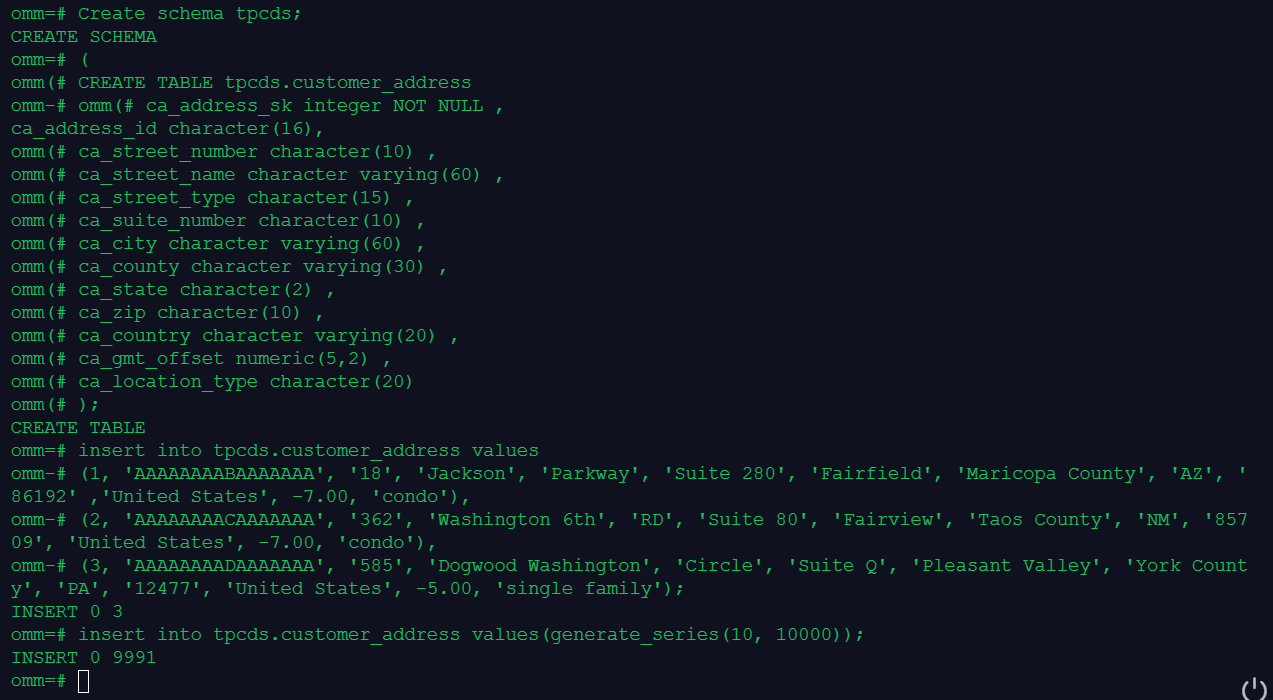
查看统计信息:

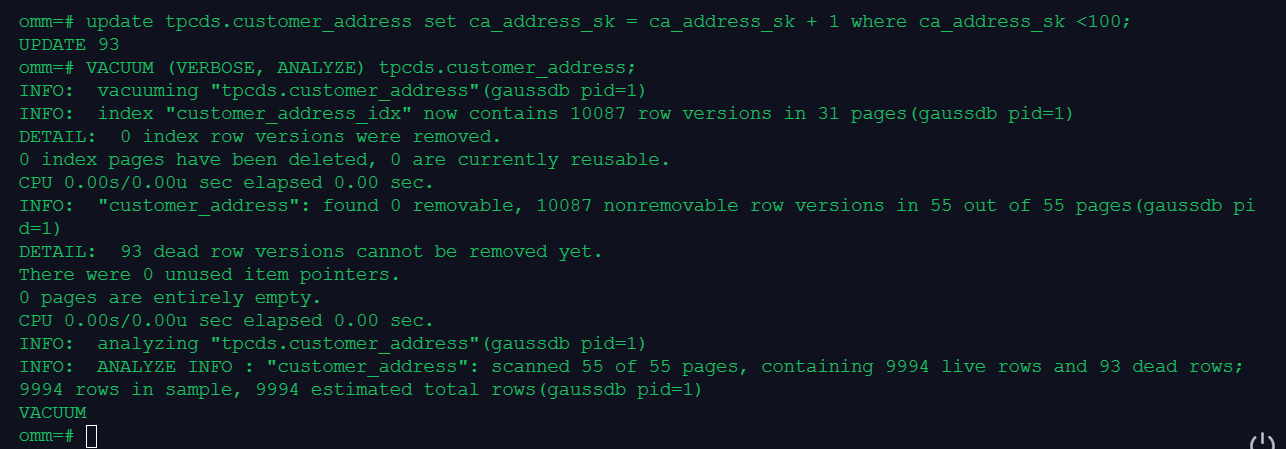
更新统计信息:
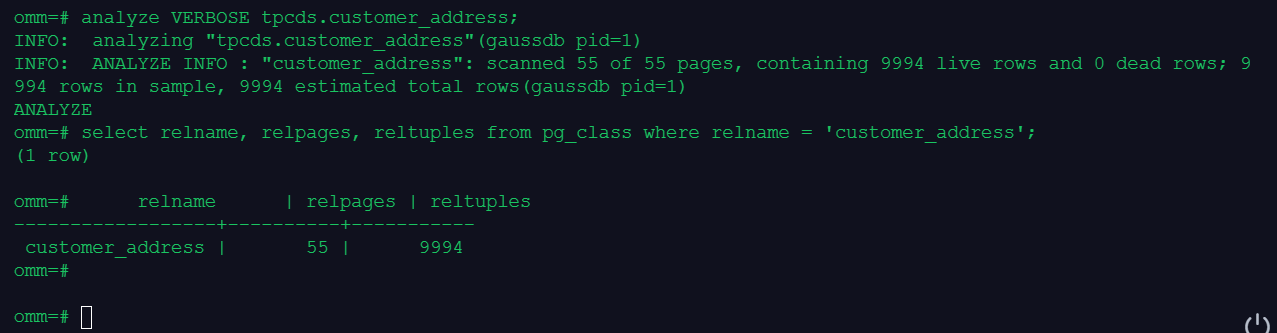
查看执行计划:
禁止开销估计的执行计划
带有聚集函数查询的执行计划

有索引条件的执行计划
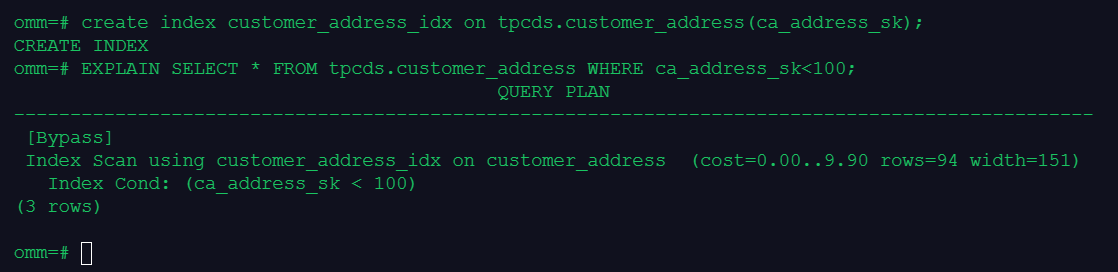
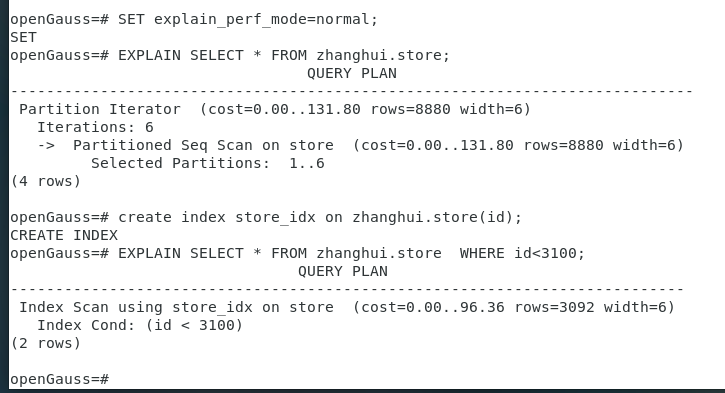
前者走seq scan,后者走index scan。
VACUUM回收表或B-Tree索引中已经删除的行所占据的存储空间
刷新到硬盘:
删除schema:

做作业:
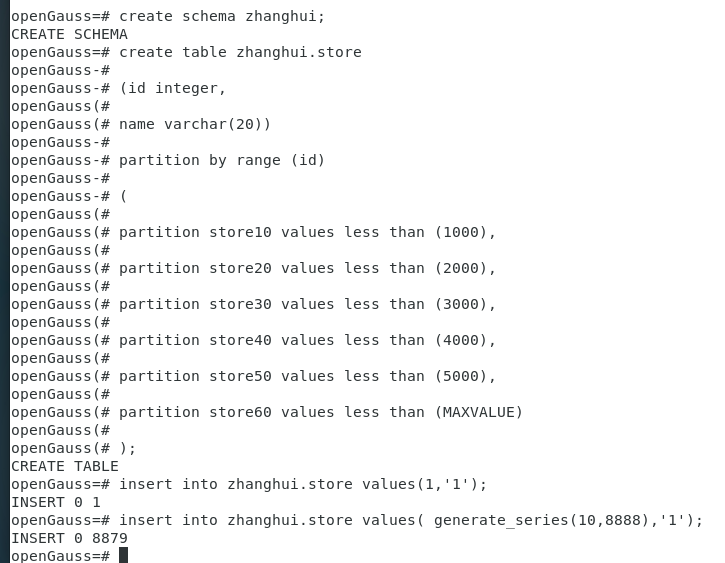
1.创建分区表,并用generate_series(1,N)函数对表插入数据
create schema zhanghui;
create table zhanghui.store
(id integer,
name varchar(20))
partition by range (id)
(
partition store10 values less than (1000),
partition store20 values less than (2000),
partition store30 values less than (3000),
partition store40 values less than (4000),
partition store50 values less than (5000),
partition store60 values less than (MAXVALUE)
);
insert into zhanghui.store values(1,'1');
insert into zhanghui.store values( generate_series(10,8888),'1');
2.收集表统计信息
select relname, relpages, reltuples from pg_class where relname = 'store';
analyze VERBOSE zhanghui.store;
select relname, relpages, reltuples from pg_class where relname = 'store';

3.显示简单查询的执行计划;建立索引并显示有索引条件的执行计划
SET explain_perf_mode=normal;
EXPLAIN SELECT * FROM zhanghui.store;
create index store_idx on zhanghui.store(id);
EXPLAIN SELECT * FROM zhanghui.store WHERE id<3100;
4.更新表数据,并做垃圾收集
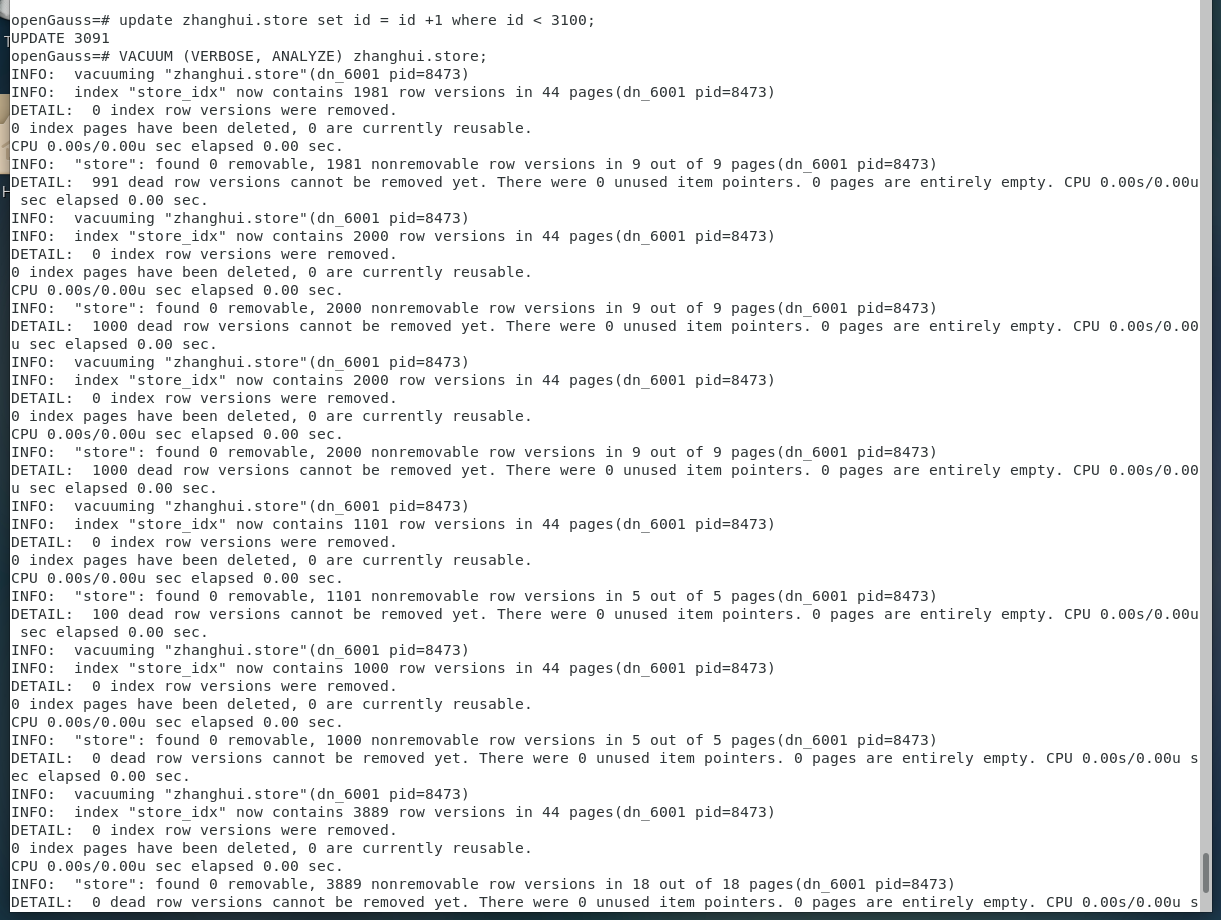
update zhanghui.store set id = id +1 where id < 3100;
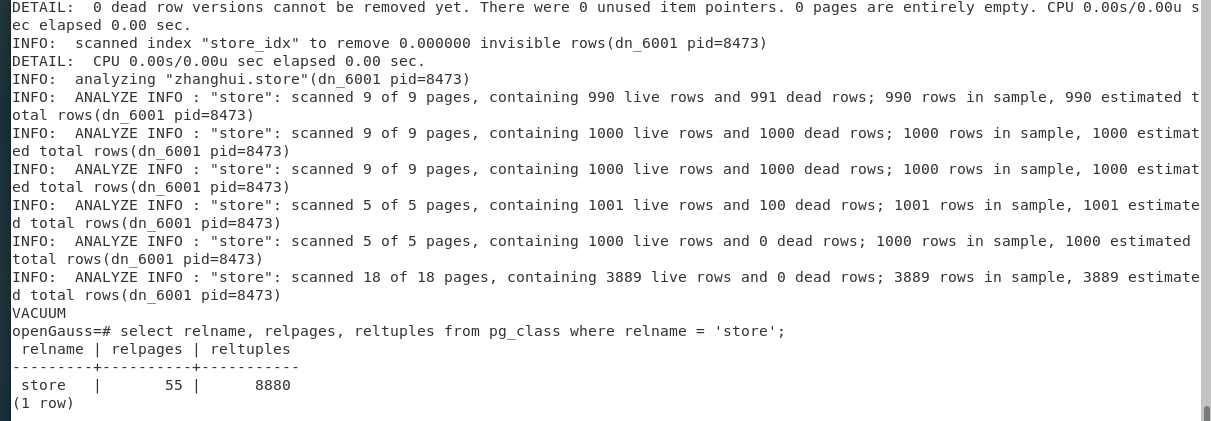
VACUUM (VERBOSE, ANALYZE) zhanghui.store;
select relname, relpages, reltuples from pg_class where relname = 'store';
5.清理数据
drop table zhanghui.store;

