




tsvector和tsquery的含义:tsvector类型表示为文本搜索优化的文件格式,tsquery类型表示文本查询
1.用tsvector @@ tsquery和tsquery @@ tsvector完成两个基本文本匹配
SELECT 'the openguass is a chinese database very good'::tsvector @@ 'openguass & very'::tsquery AS RESULT;
SELECT 'openguass & and'::tsquery @@ 'the openguass is a chinese database very good'::tsvector AS RESULT;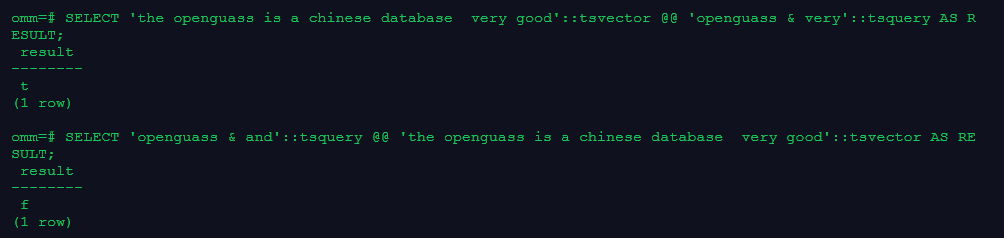
SELECT to_tsvector('the openguass is a chinese database very good') @@ to_tsquery('openguass & database') AS RESULT;
SELECT to_tsvector('the openguass is a chinese database very good') @@ to_tsquery('openguass & data') AS RESULT;
2.创建表且至少有两个字段的类型为text类型,在创建索引前进行全文检索
CREATE SCHEMA test;
CREATE TABLE test.tb1(id int, body text, title text, last_mod_date date);
INSERT INTO test.tb1 VALUES(1, 'we are chinese peaple, we are very luck''lear substr say helly, hello world''we are small.', 'ChinaHongKang', '2021-1-1');
INSERT INTO test.tb1 VALUES(2, 'aa bb cc dd ee fff', 'America', '2021-1-1');
INSERT INTO test.tb1 VALUES(3, 'ggg hhh iii lll kkk www', 'England','2021-1-1');
SELECT id, body, title FROM test.tb1 WHERE to_tsvector(body) @@ to_tsquery('luck');
SELECT id, body, title FROM test.tb1 WHERE to_tsvector(title || ' ' || body) @@ to_tsquery('ChinaHongKang & are');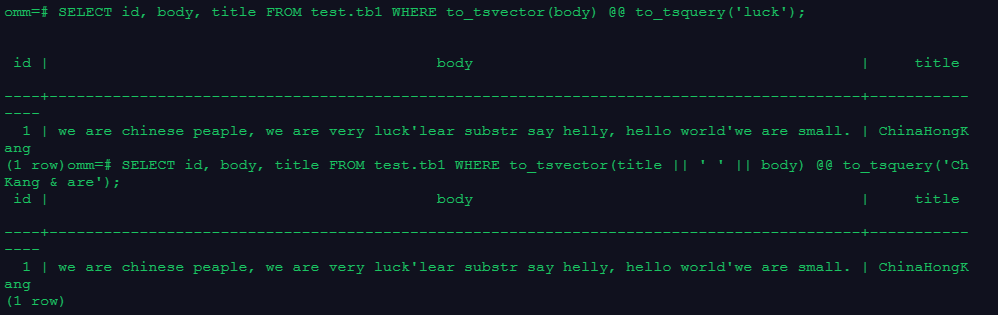
3.创建GIN索引
CREATE INDEX tb_idx_1 ON test.tb1 USING gin(to_tsvector('english', body));
CREATE INDEX tb_idx_2 ON test.tb1 USING gin(to_tsvector('english', title || ' ' || body));
\d+ test.tb1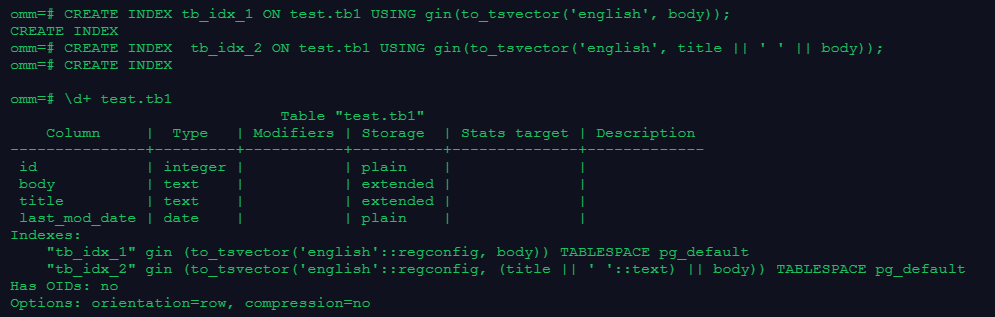
4.清理数据
drop schema test cascade;

