




 猛戳蓝字获取更多阿里百川资讯!
猛戳蓝字获取更多阿里百川资讯!
在上文中,ahuaxuan讲到了索引创建的主体流程,但是索引合并其实还有一个较为重要的细节ahuaxuan没有详细阐述。本文中,ahuaxuan将会详细阐述这个问题
本文分成两部分内容
1 、考虑应用拓机时的数据正确性问题。
2、 jackrabbit是如何解决这些问题的。
而这个细节将会直接影响我们对query module的改造,这个细节虽然不难,但是却很重要,是jackrabbit中一个比较重要的设计。下面让我们一起来看看这个是什么样的细节。
回顾上文,我们知道一个目录合并的主要逻辑是10个以上同层次(一共10个层次,还记得否)的小目录会合并成上一个层次的目录
那么现在的问题是
1. 当低层次的多个小目录合并完成一个高层次的目录之后,我们需要把这些目录删除。
2. 并且要通知程序产生了一个新的目录。
但是这个时候程序突然挂掉,怎么办呢。那么就必须有一个恢复机制。
需要被删除或者需要增加的目录的信息如果没有持久化的机制,那么程序再启动的时候就无法分辨哪些索引数据是要删除的,哪些是新增的。咋办呢,咋整呢?我们得有一个持久化的机制来证明哪些索引目录是需要被删除,哪些是有效的索引目录,这样Repository启动的时候就可以拿到正确的IndexReader。
Ahuaxuan在前面的文章分析过,Action的接口以及其实现类:
其中AddIndex和DeleteIndex这两个Action值的关注,这两个Action一个是创建PersistentIndex,一个是删除PersistentIndex,前面讲过一个PersistentIndex对应一个索引目录,AddIndex和DeleteIndex中必然包含着PersistentIndex相关信息持久化的问题。
我们先来看看AddIndex类的execute方法:
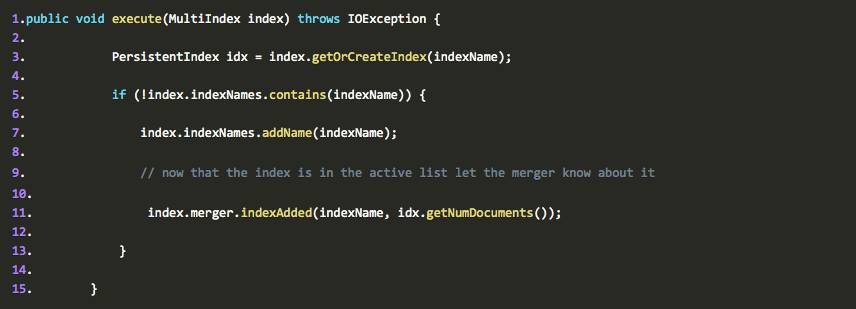
Ok, 代码写得很清楚,如果indexNames不包含一个PersistentIndex的name,那么就将这个PersistentIndex的indexName加入到indexNames中。
再来看看DeleteIndex的execute方法:
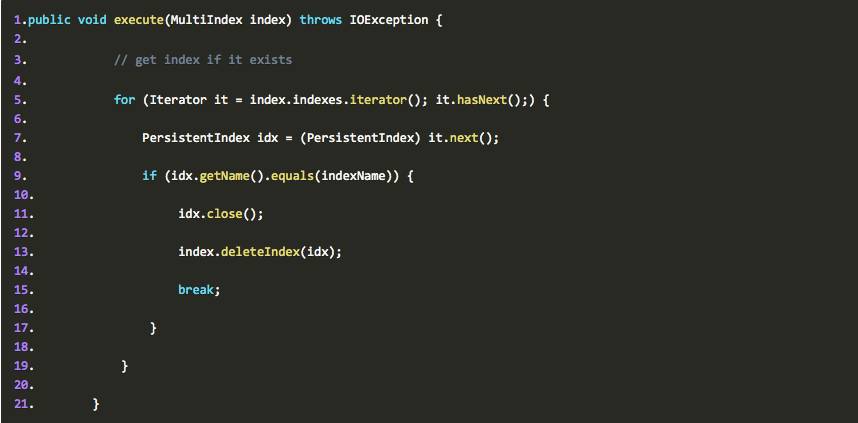
也写的很清楚,当删除一个PersistentIndex时,检查一下indexs(PersistentIndex的集合)中是否包含这个要删除的PersistentIndex,如果包含就执行index.deleteIndex方法:
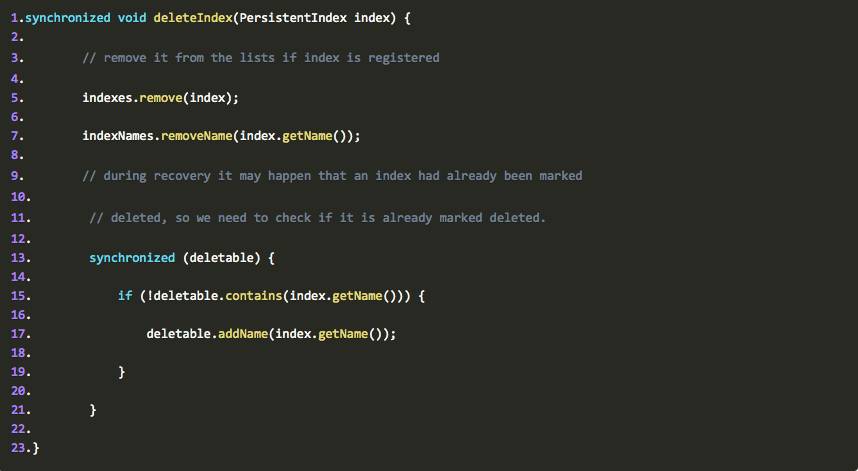
进入这个方法后,我们可以看到,所谓的删除,就是把indexNames中的PersistentIndex的name删除掉,并把这个要删除的indexName加入到deletable中。
关键是indexNames和deletable到底是个什么东西,从这里我们可以看出来,其实indexNames和deletable就记录着PersistentIndex的name,也就是说这两个对象中保存着有效的索引目录和需要被删除的索引目录。当10个目录合并成一个目录的时候,就是把10个目录的name从indexNames中删除,并加入到deletable中去。
Jackrabbit就是通过这种方式来保证应用拓机时索引数据的正确性。
接下来,我们来看看deletable和indexNames到底是什么对象:
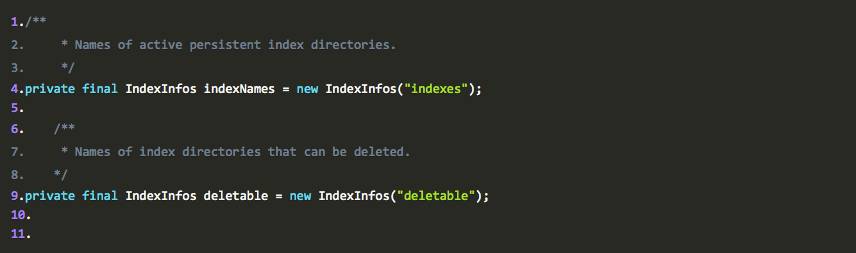
这样我们就明白了,indexs和deletable原来是同一种对象。而且可以肯定,IndexInfos这个类具有持久化的功能,它需要把自身包含的数据持久化到磁盘上。
接着我们来看看这个类中有些什么东西:
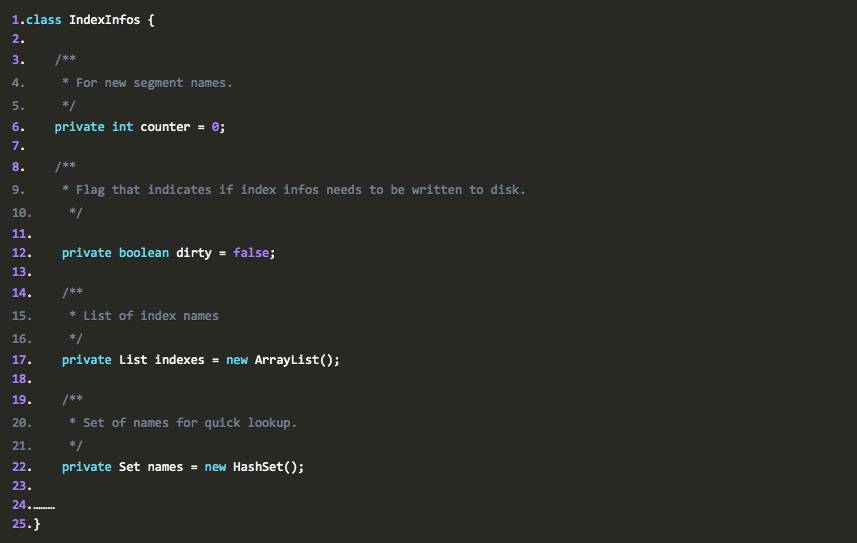
从这段代码看来,似乎这个类里面只有一个indexes是我们已知的(names是为了快速判断一个indexname是否在indexs这个list中),而且我们没有看到持久化的相关信息,抱着这样的想法,我们继续往下看,下面我们再来看看如何把一个PersistentIndex的数据indexName加入这个类中:
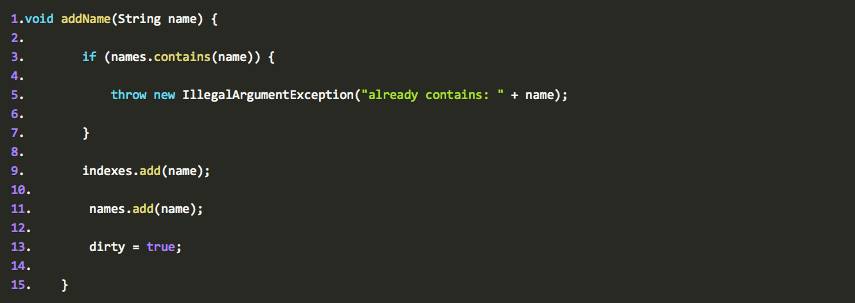
还是没有持久化的信息,ahuaxuan很焦虑,肾上腺激素含量开始升高,啥都别说了,接着看吧,1秒钟之后,终于发现这个方法:
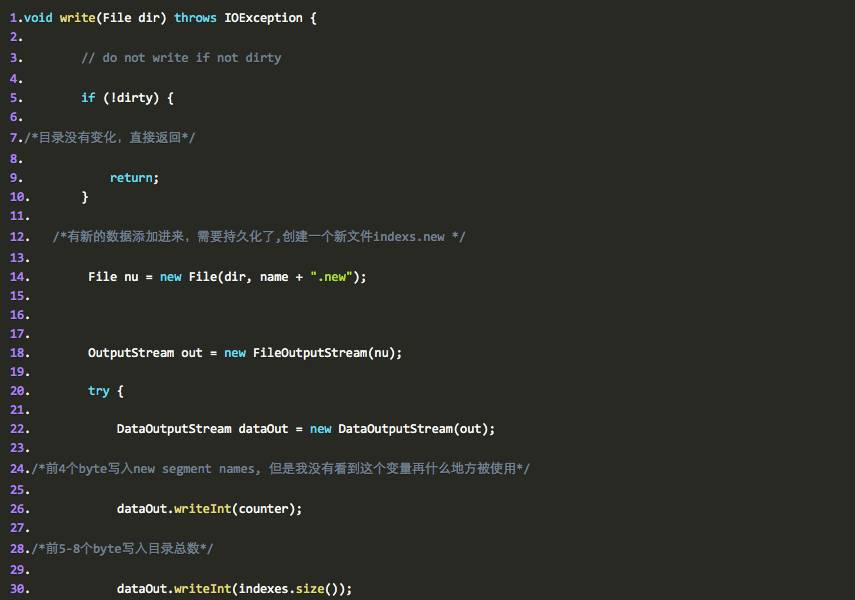
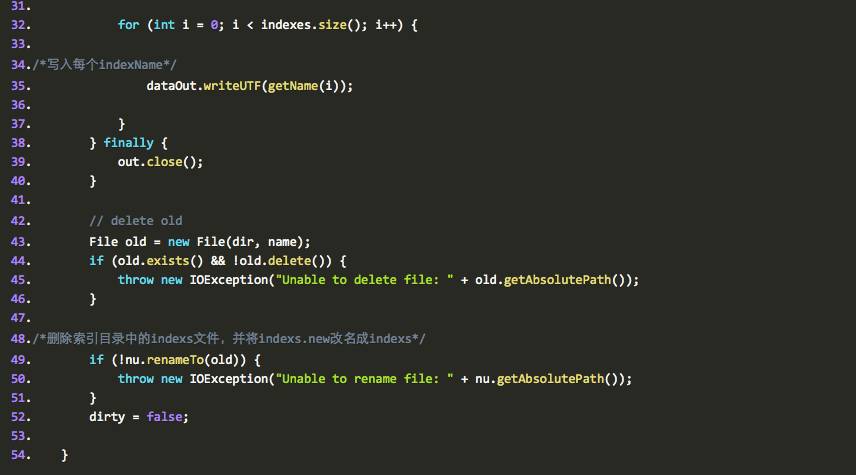
由此可见,IndexInfos确实有把新添加的PersistentIndex对应的目录持久化起来,什么时候做这件事情呢,当然是在添加索引介绍的时候,比如说flush的时候,没错,就是前面讲到的multiIndex#update中的三大方法中的flush(记住它的触发条件哦),flush的时候,内存中的有效的索引目录的信息就会被持久化到磁盘上。
同样的道理,deletable中也是这样的逻辑,要删除的目录也会被持久化起来。
既然保存下来了,我们不妨看看什么时候会用到,于是乎查看read方法:
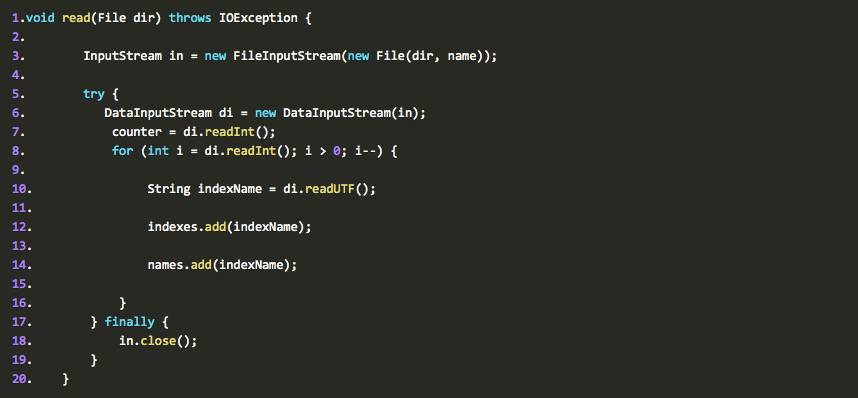
果不其然,有这么一个read方法,这个方法就是负责解析文件,并把文件中的数据拿出来放到内存中。那么这个方法是谁来调用的呢:ctrl+shift+g.
发现在MultiIndex的构造方法里确实用到了:
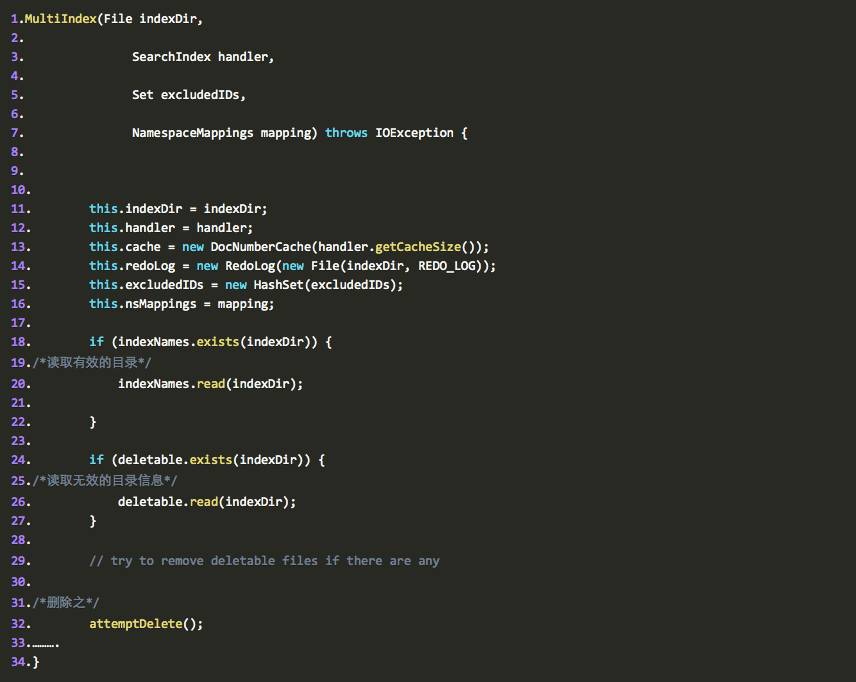
通过这种方式,jackrabbit就可以保证在程序在不执行添加索引,或者索引合并(因为这两个操作中都有AddIndex和DeleteIndex被执行,也就是说这个两个操作都会导致目录变更)的时候突然拓机的情况下,程序重启还能正常提供服务。
如果程序正在执行merge操作,产生了新目录,需要删除老的目录,这个时候情况比较麻烦:
1、在这两个信息没有被持久化到磁盘上之前程序歇菜了,那可能还好办,毕竟原始的数据还在磁盘上,不过产生的新目录不能被读取到,因为不在indexes文件里。
2、但是indexNames持久化成功,deletable持久化失败,那就没有办法了,这样就会导致这些个需要删除的目录信息不存在于deletable中,而新的有效目录也存在于indexNames中,那么程序重启的时候能读到这个目录,但是不知道哪些目录需要被删除。
在这样的场景下会产生一些冗余目录和冗余文件,但是不影响正常数据,后面会讲到redolog和indexes的关系,很重要,是保证数据完整性的重要一步。
总结
真相如此简单,但是却不得不考虑,由此证明,写代码,写框架,尤其数据库之类的东西,重要的是逻辑的严谨性,最重要的还是逻辑的严谨性,如同设计模式这类的东西只是辅助技巧,切不可舍本求末,亦不可舍主求次。主次分明才是最好的平衡。
阿里百川(baichuan.taobao.com)是阿里巴巴集团“云”+“端”的核心战略是阿里巴巴集团无线开放平台,基于世界级的后端服务和成熟的商业组件,通过“技术、商业及大数据”的开放,为移动创业者提供可快速搭建App、商业化APP并提升用户体验的解决方案;同时提供多元化的创业服务-物理空间、孵化运营、创业投资等,为移动创业者提供全面保障。
点击【 阅读原文】查看更多精彩!
