




 猛戳蓝字获取更多阿里百川资讯!
猛戳蓝字获取更多阿里百川资讯!
我们从文本提取的逻辑中走出来,回到主体流程。
在前面的文章中,我们可以看到一次索引创建的操作,可能会产生多个 persistentindex 对象,而这些对象其实代表着一个索引目录。随着创建索引的次数越来越多,那么索引目录也在增多,但是索引目录中的数据却不是很多,所以我们需要把多个目录合并,其实也就是索引的合并。
执行这个操作的类是 IndexMerger ,看其定义为:
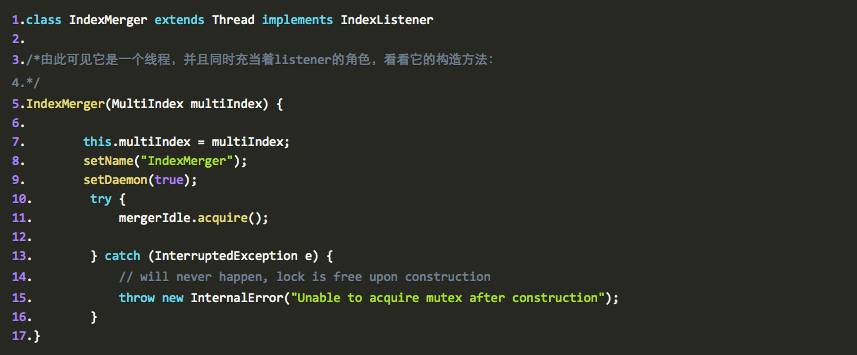
还是一个 deamon 线程。而且一构造就来了一个 mergerIdle.acquire(); 真是迫不及待啊。啥意思啊?得到一把锁,一把非阻塞的锁。
在创建完 IndexMerger ,那么就有可能把 PersistentIndex 加进来了,因为 Merger 类必须知道哪些 PersistentIndex 是需要 Merger 的,那么我们看看负责这段逻辑的代码:这段代码主要负责 3 个功能,一个是初始化 indexBuckets ,这个一个 ArrayList ,其中放的是需要 Merger 的 PersistentIndex 的列表,也就是我们可以认为 indexBucket 里放的还是 list ,这里有一个非常奇怪的设计,就是在初始化的时候将 PersistentIndex 按照 docnums 的范围分组了,一组就是一个 indexBucket 。
第二个是把需要加入的 PersistentIndex 加入到对应的分组中。
第三个是判断是否需要合并,如果需要就加到一个队列中,等待被合并。
先看第一段代码:
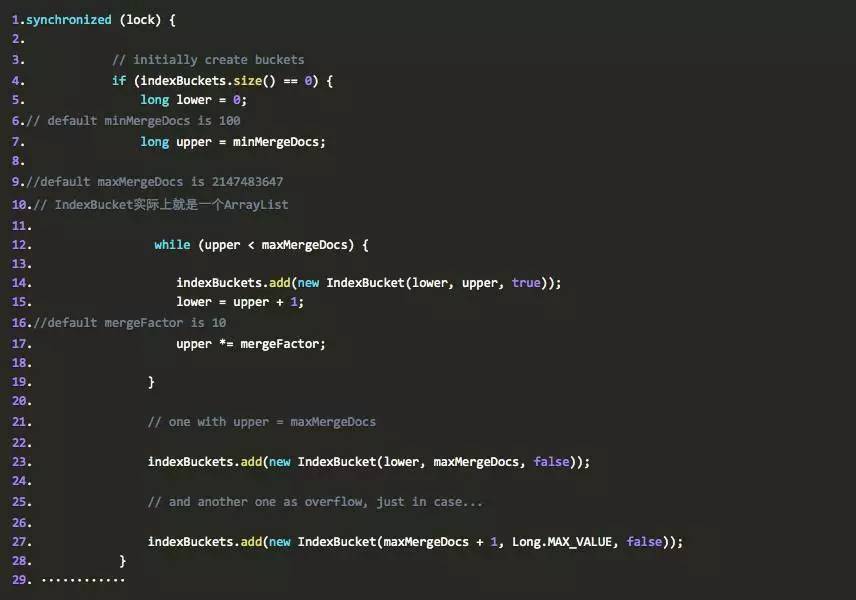
仔细阅读代码,我们发现,在初始化 indexBuckets 的代码中,其实按照范围来初始化的,比如当添加第一 IndexBucket 的时候 lower=0 , upper=100
即 new IndexBucket(0 100 , rue )
第二个则为: new IndexBucket(101, 100*10, t rue )
第三个则为: new IndexBucket(1001, 100*10*10, t rue )
第四个则为: new IndexBucket(10001, 100*10*10*10, t rue )
第五个则为: new IndexBucket(100001, 100*10*10*10*10, t rue )
````````````
一直持续下去直到 upper 小于 2147483647 ,且是 10 的最大幂。那么就是说 10 亿,当一个目录中有 10 亿个 document 的 index 数据时,这个目录将不再参与 merge 过程, indexBuckets 中总共有 8 个 IndexBucket, 不过在循环外面还有两个创建 IndexBucket 的语句,不过这两个都是不允许参加合并的,所以第 3 个参数是 false ,也就是说一共有 10 个,第九个是:

那么第十个是:

搞清楚 indexBuckets 的 初始化之后,我们再来看看第二个步骤,把根据 docNums 把对应的 persistentindex 加入到 IndexBucket 中 :
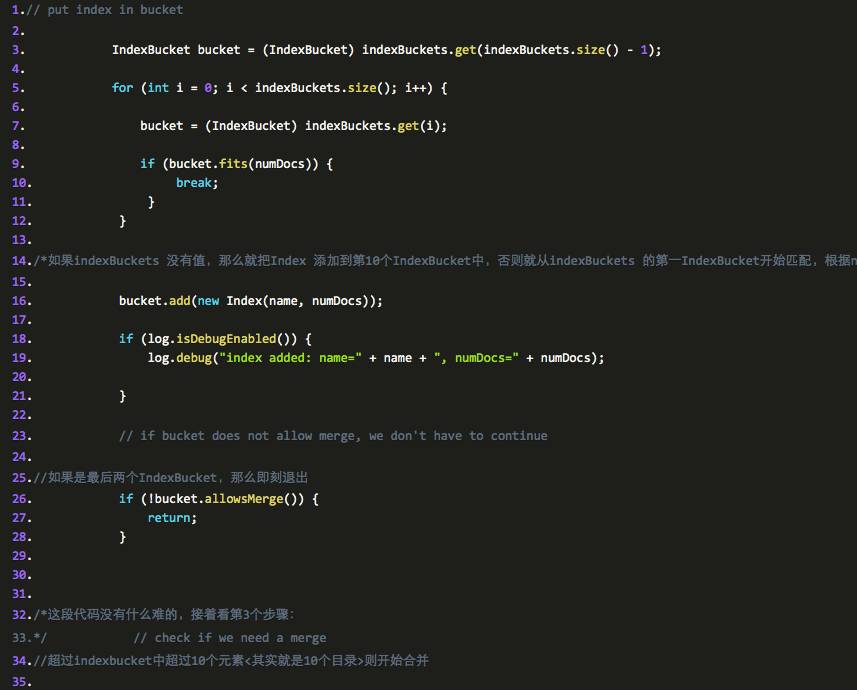
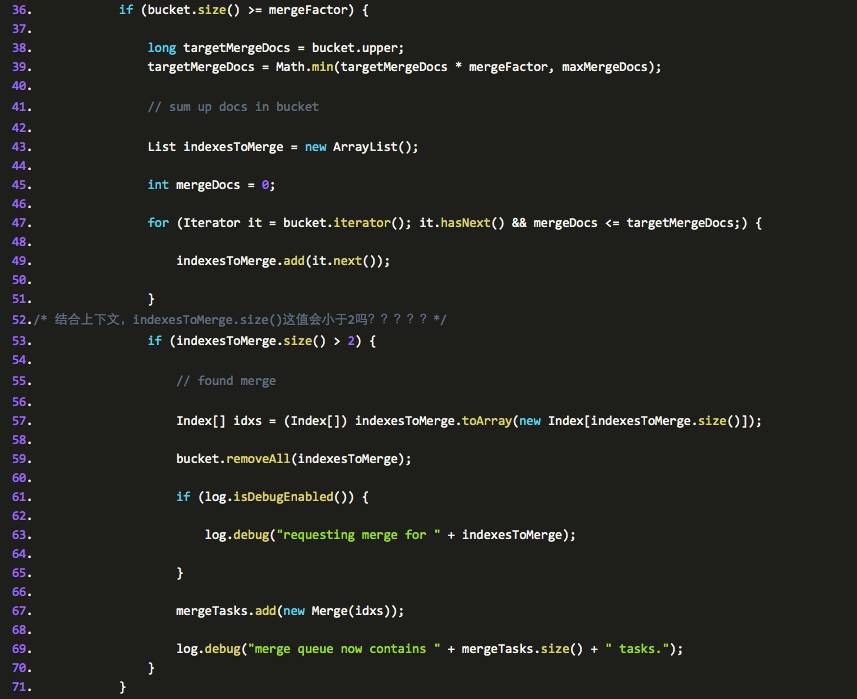
这段代码的主要功能是把 indexbucket 里的 persistentindex 信息拿出来,而且量超过 2 的话就把他们加入到一个队列中,并将它们从该 indexbucket 里删除。通过这个步骤,那么 mergeTasks 队列中就存在一些需要合并的 index了。
中场总结:
通过上面的方法和前面的索引提交的文章我们得到一些重要信息:当用户把 ramdirectory 中超过 100 的 docs 的 index data 刷到 fsdirectory 中时,新建一个目录,作为这个新 fsdirectory 的目录,接着把这个 fsdirectory 对应的 PersistentIndex 加到 IndexMerger 类的某个 IndexBucket 中,接着当某个 IndexBucket 中的 PersistentIndex 数量(即这些目录的数量)超过 10 ( mergefactor )的时候,就会执行合并的操作。
那么下面的问题是,合并之后,这 10 个目录将会何去何从,它们是把另外 9 个合并到其中一个中去呢还是怎么滴?接着看吧。
显然,这里又用到生产消费模型,任何调用 indexAdded 方法的都属性生产者,生产者根据一些条件,有选择的把需要合并的 persistentindex 放到 mergeTasks 的队列中,有了生产者肯定存在消费者,文章开头提过, IndexMerger类是一个 deamon 线程,看看它的 run 方法,那么就发现,其实它就是消费者。它主要完成以下几个功能:
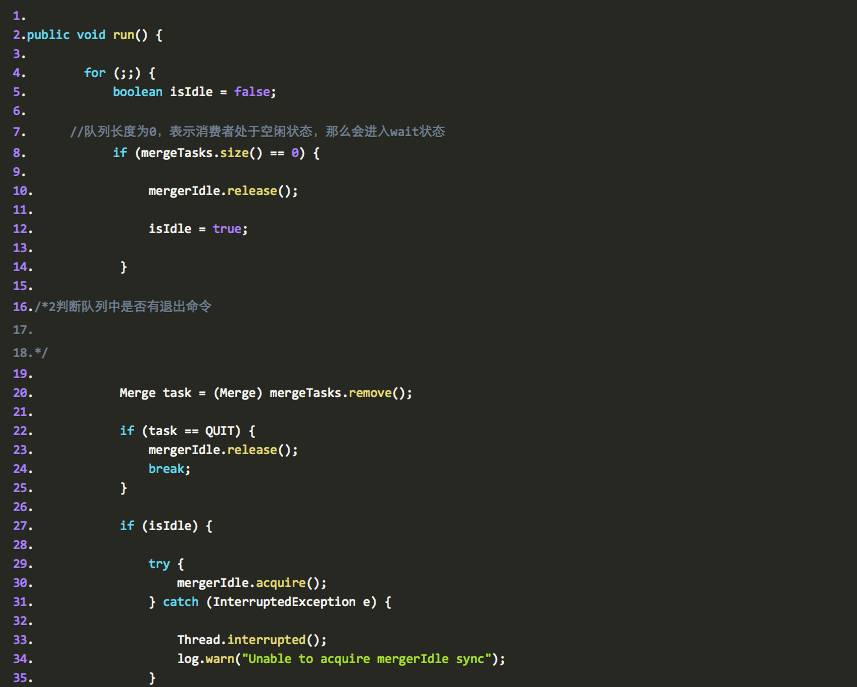
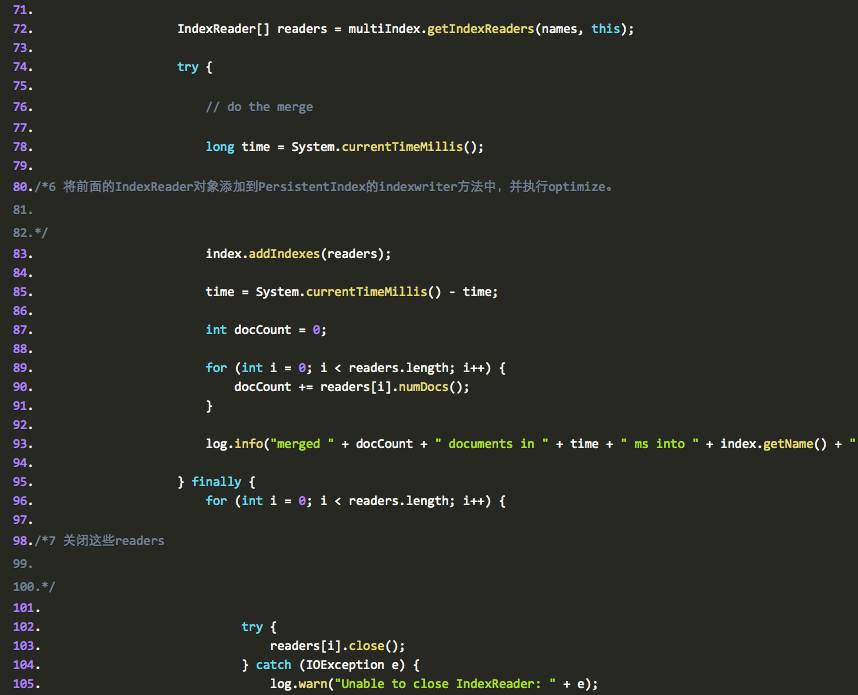
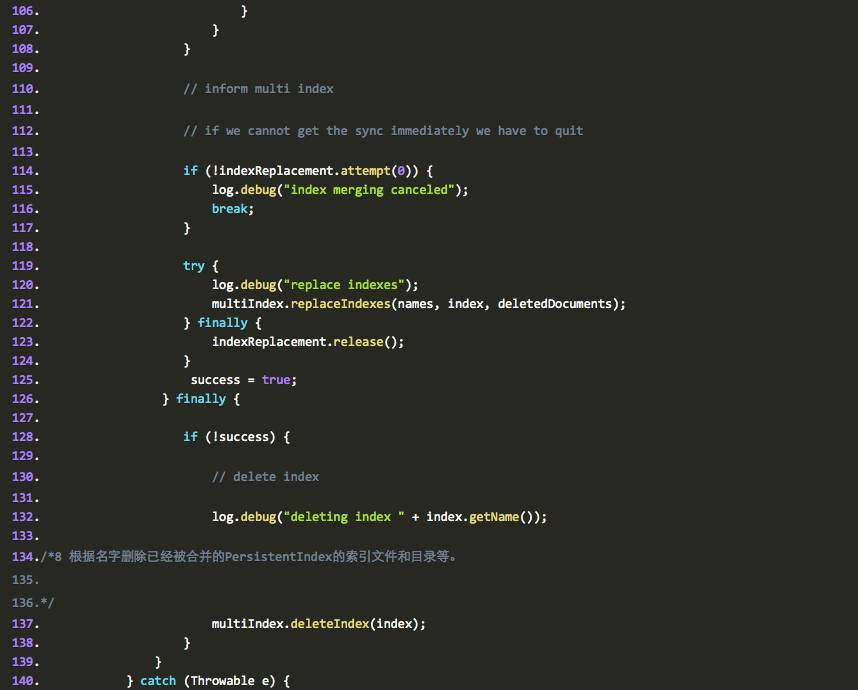
1 判断消费者是否空闲
2 判断队列中是否有退出命令
3 如果空闲则进入 wait 状态
4 根据 persistentindex 的名字取到所有的 persistentindex
的 IndexReader 对象
5 再创建一个新的 PersistentIndex, , 原来的 index 文件合并到这个新的目录中
6 将前面的 IndexReader 对象添加到 PersistentIndex 的 indexwriter 方法中,并执行 optimize 。
7 关闭这些 readers
8 根据名字删除已经被合并的 PersistentIndex 的索引文件和目录等。
我们再来看看代码,代码中已经加入了 ahuaxuan 的注释:


看到这里爱思考的同学们一定会意识到这里还漏了什么,是什么呢?前面讲到,一个 bucket 中超过 10 个目录,会被合并一个新的目录,那么也就是说这个新目录中至少有 1000 个 document 的索引数据,这样下来,如果我有 100000个节点,而且恰好每个目录中之后 1000 个 document 的数据,那么就得用 100 个目录来存储数据了。这样带来的问题是,每做一次查询,都需要把 100 个 indexReader 传给 search ,即使使用多线程并行搜索,那目录数也还是太多了,而且如果是 100w 个节点,那就更不得了了,所以 jackrabbit 中一定还有机制会把这些目录合并成更大目录的逻辑。为什么这么说,因为之前在创建 indexbucket 中的时候,分了 8 个允许合并的段,而上面的逻辑只会用到前面一个 bucket,后面的几个肯定是有用处的,那么是谁来触发它们的,它们在哪里呢?
我们看到在上面的 run 方法中,我们有一个方法没有讲到: multiIndex .replaceIndexes(names, index, deletedDocuments );
我们将会在这个方法中寻找到真相,同样, ahuaxuan 在代码中加入了自己的注释
/* obsoleteIndexes 是需要被删除的 dir ,因为他们的数据已经被合并到新的目录里, index 参数则表示那个对应那个新目录的 PersistentIndex , deleted 表示需要被删除的类 */
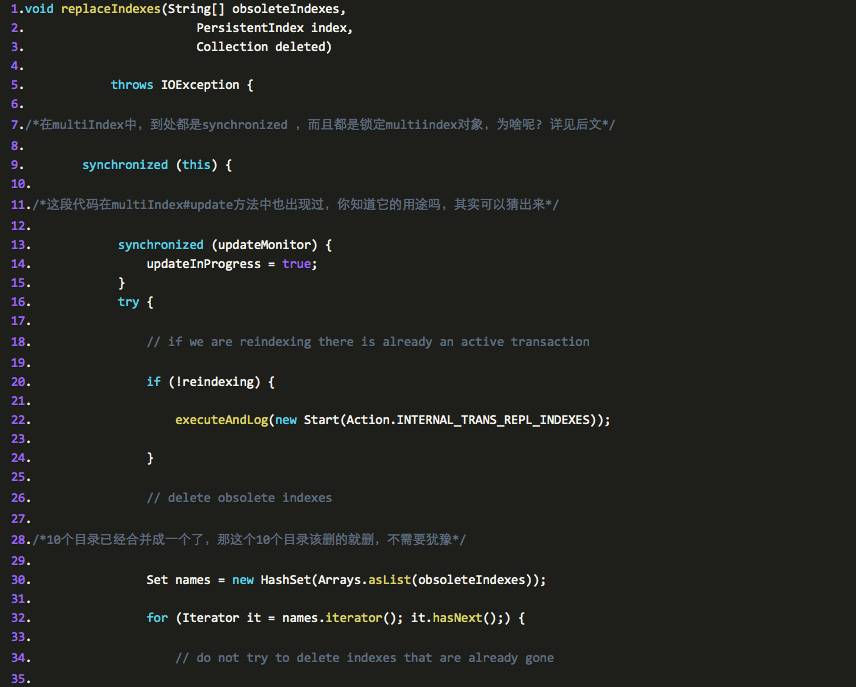

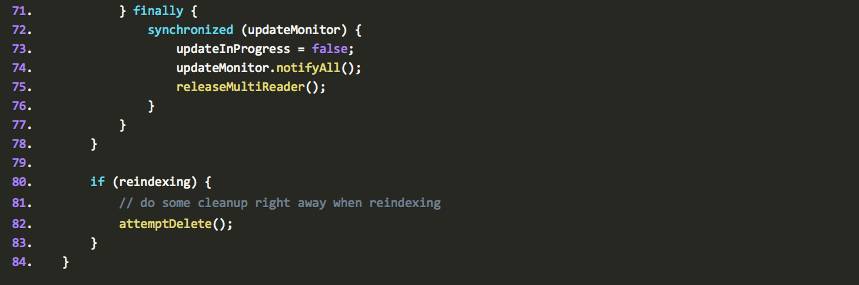
看完这段方法,我们发现,小的目录合并成大目录之后,这个大目录又被加到 indexbucket 等待下一次被合并,如此递归,一直当一个目录的 document 的 index 数据超过 10 亿,那么就不会再合并了.因为在前面的流程中,我们看到,ramdirectory中的数据只有满100才会加入到fsdirectory中,这意味着一开始用到的目录就是101-1000级别的目录(101-1000的目录表示这些目录中的document的index数据也只有101-1000个这个范围。)。这种目录超过10个就会合并成一个新目录。依次类推高层目录。见图中ahuaxuan的注释
说到这里,大部分人都知道了,很多参数可以控制合并的调优,这些参数在前文已经讲过了,不再赘述。
到这里,IndexMerger的主体流程基本上完成了,其实就是一个生产-消费模型+小目录生产大目录,大目录生成更大目录的算法,这样做的好处是什么?当然是尽量少改动索引文件,应该说是便于分布式的查询架构。但是在后文中,我们会详细分析jackrabbit还没有为分布式查询准备好的原因,它的这块设计还有待改进,人无完人,框架亦是如此,不用过于苛求,也不必抱怨,用的不爽,那么就---改它,再不行---重新实现(某个模块或者全部)。
TO BE CONTINUED
阿里百川(baichuan.taobao.com)是阿里巴巴集团“云”+“端”的核心战略是阿里巴巴集团无线开放平台,基于世界级的后端服务和成熟的商业组件,通过“技术、商业及大数据”的开放,为移动创业者提供可快速搭建App、商业化APP并提升用户体验的解决方案;同时提供多元化的创业服务-物理空间、孵化运营、创业投资等,为移动创业者提供全面保障。
点击【 阅读原文】查看更多精彩!
