




GaussDB A:从数据库到大数据的企业级分布式OLAP数据库
GaussDB A产品概述
- 高扩展:
开放架构,按需水平扩展: Shared-Nothing架构+独创的大规模集群通讯技术,可扩展到2048节点 - 高可靠:
全组件HA,无单节点故障: 集群的协调节点、数据节点等逻辑组件全HA设计 - 高性能:
行列混存,极速查询分析: 全并行计算,行列混存+向量化执行; 并行Bulk Load,数据快速入库 - 易运维:
标准SQL, 平滑应用迁移:兼容标准ANSI SQL2003;提供Oracle、Teradata语法迁移工具。 - 融合大数据 :MPPDB on HDFS(ORCFile/txt/csv); MPPDB on Spark、MPPDB on Oracle
- 云服务:
华为云DWS服务:支持多租户、跨数据源访问、在线扩容、在线升级, 资源按需弹性伸缩等特性
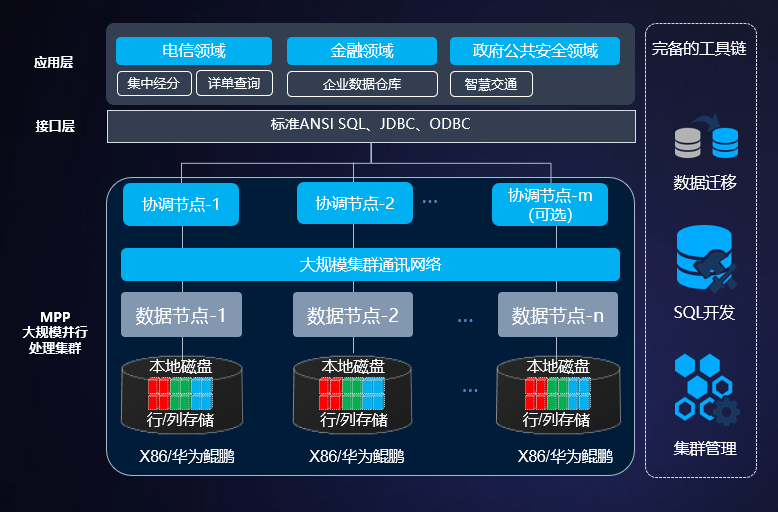
软件逻辑架构:
无共享架构,按需横向扩展x86/华为鲲鹏服务器,实现海量数据高性能SQL分析
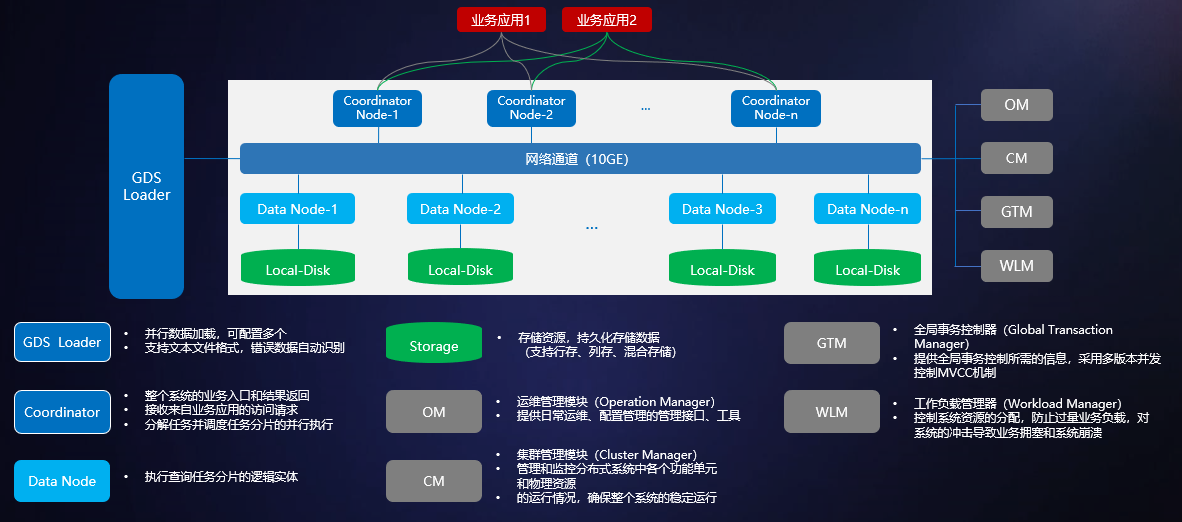
GaussDB A 主要特性
1.高可用
- 数据分布式存储
- 数据分区
- 在线扩容
2.高性能
- 数据并行导入
- 全并行的数据查询处理
- 向量化执行和行列混合引擎
3.多模和融合
- SQL on Anywhere
- 图像特征检索
4.资源管理
- 多集群统一管理
- 工作负载管理
- 基于逻辑集群的资源和数据隔离
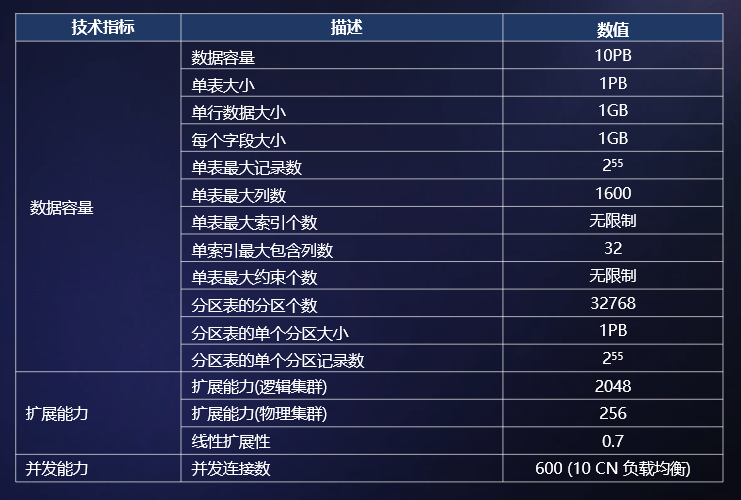
GaussDB A 产品规格
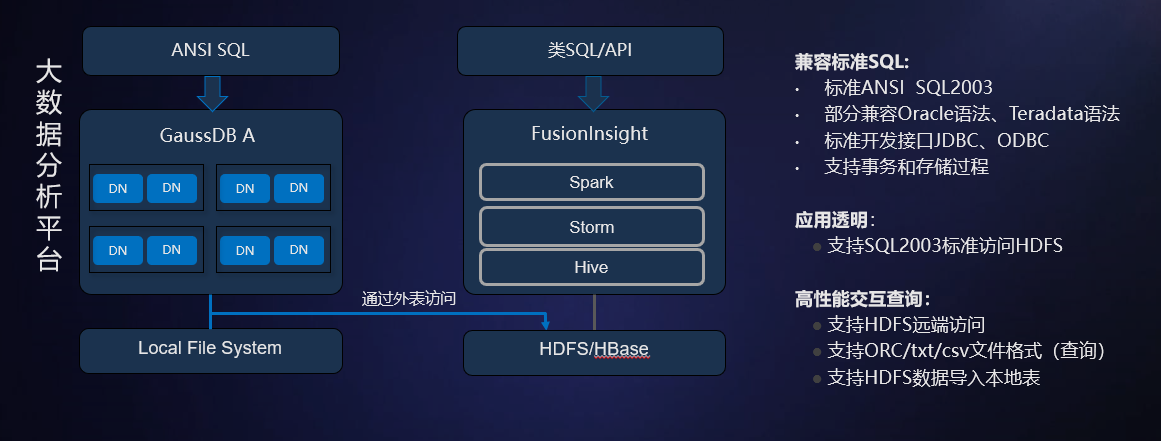
SQL On HDFS,实现互联互通,且兼容标准SQL
GaussDB将HDFS上存储的结构化数据映射为外部表,从而利用数据库SQL引擎的能力对HDFS上的数据进行分析。
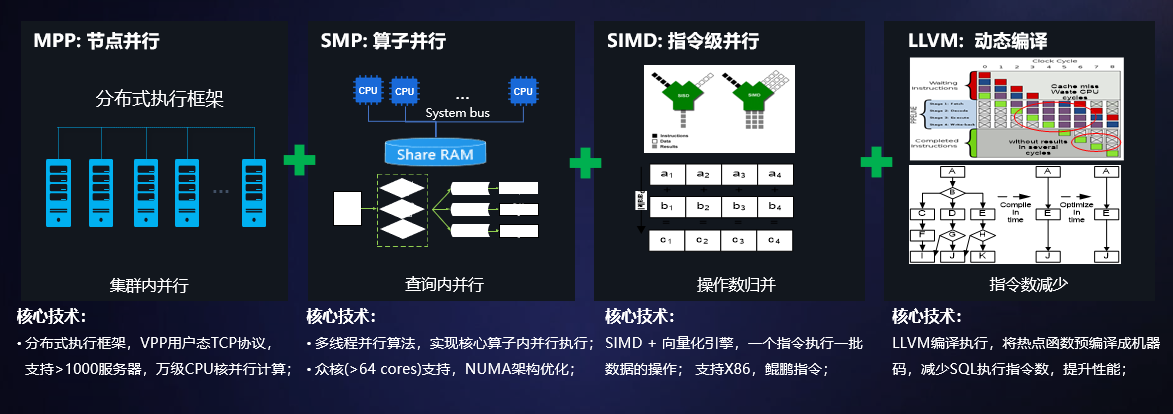
GaussDB A全并行架构,最大化利用系统计算资源利用率
核心问题:
x86 PC Server集群架构下,单核处理能力有限,如何利用x86多核计算资源,提升集群处理性能;
未来鲲鹏64众核架构下,解决众核、Numa架构资源利用问题;
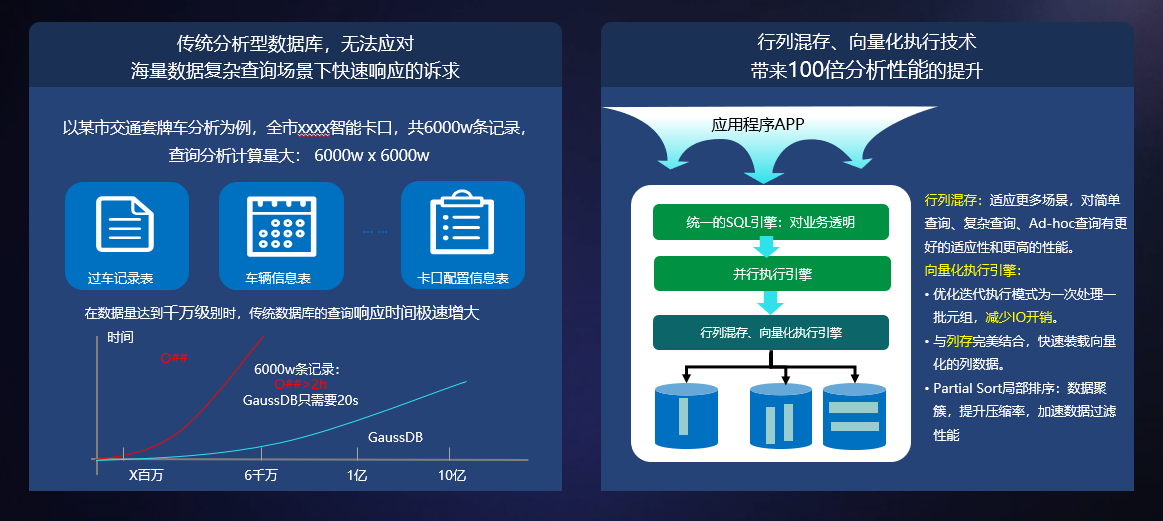
行列混存、向量化执行技术,实现万亿数据关联分析秒级响应
异构计算框架发挥多样性算力优势,实现多维比对分析GPU加速
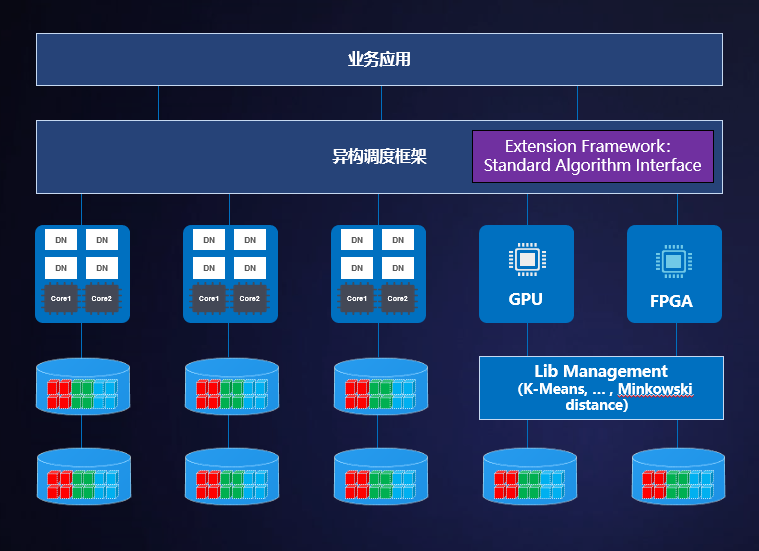
关键技术:
- 可编程执行框架:支持统一框架集成各种ISV算法(可同时集成多家ISV算法,根据场景调用),算法下推全并行执行
- 多维数据比对碰撞算法加速:使用GPU加速技术提升图像特征数据碰撞分析
- 支持多种类AI比对算法,如Minkowski Distance(相似度比较)、K-Means(聚类)
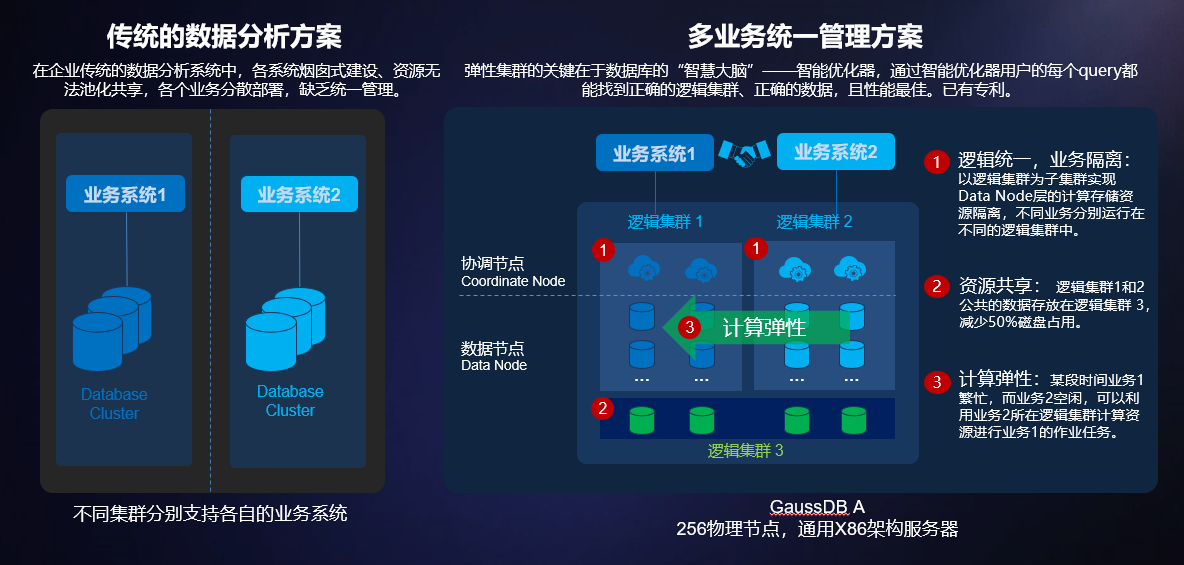
弹性集群,通过多租户支持多业务统一管理
注:本文取自华为GaussDB生态与标准CTO王伟民的公开课《45分钟探索华为自研GaussDB数据库》课件,课件查看下载链接如下:https://www.modb.pro/doc/2171
「喜欢这篇文章,您的关注和赞赏是给作者最好的鼓励」
关注作者
【版权声明】本文为墨天轮用户原创内容,转载时必须标注文章的来源(墨天轮),文章链接,文章作者等基本信息,否则作者和墨天轮有权追究责任。如果您发现墨天轮中有涉嫌抄袭或者侵权的内容,欢迎发送邮件至:contact@modb.pro进行举报,并提供相关证据,一经查实,墨天轮将立刻删除相关内容。
