1、Lambda 表达式简介 大家好,今天我们开始一个新专题 —— Java Lambda 表达式。这是在 Java 8 中出现的一个新特性,但它并不是 Java 独有的,JavaScript、C#、C++ 等在 Java 8 之前就支持 Lambda 表达式的特性,现在的大多数程序语言也都支持 Lambda 表达式。 这个专题中我们学习函数式编程的概念、Lambda 表达式的语法、以及如何在我们的代码中使用 Lambda 表达式。本文我们主要先介绍下 Lambda 表达式是什么?
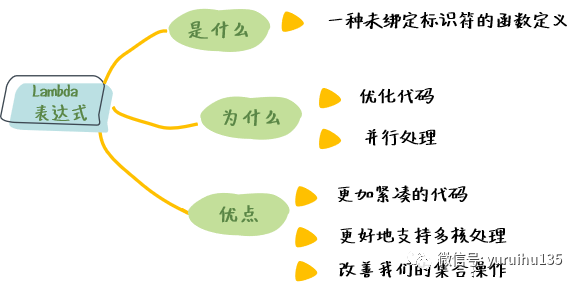
1. 什么是 Lambda 表达式 什么是 Lambda 表达式呢?维基百科是这样定义的:
Lambda expression in computer programming, also called an anonymous function, is a defined function not bound to an identifier. ——维基百科
翻译过来就是 Lambda 表达式也叫作匿名函数,是一种是未绑定标识符的函数定义,在编程语言中,匿名函数通常被称为 Lambda 抽象。
换句话说, Lambda 表达式通常是在需要一个函数,但是又不想费神去命名一个函数的场合下使用。这种匿名函数,在 JDK 8 之前是通过 Java 的匿名内部类来实现,从 Java 8 开始则引入了 Lambda 表达式——一种紧凑的、传递行为的方式。
2. 为什么要引入 Lambda 表达式 Java Lambda 表达式是伴随 Java 8 于 2014 年出现的。这个时候恰好是多核 CPU 和大数据兴起的时候。在这些趋势下,芯片设计者只能采用多核并行的设计思路,而软件开发者必须能够更好地利用底层硬件的并发特性。做过多线程编程的同学应该很清楚,在并发过程中涉及锁相关的编程算法不但容易出错,而且耗时费力。虽然 Java 提供了 java.util.concurrent 包以及很多第三方类库来帮助我们写出多核 CPU 上运行良好的程序,但在大数据集合的处理上面这些工具包在高效的并行操作上都有些欠缺,我们很难通过简单的修改就能够在多核 CPU 上进行高效的运行。
为了解决上述的问题,需要在程序语言上修改现有的 Java ——增加 Lambda 表达式,同时在 Java 8 也引入Stream(java.util.stream) 流——一个来自数据源的元素队列,支持聚合操作,来提供对大数据集合的处理能力。
所以 Lambda 表达式的出现时为了适应多核 CPU 的大趋势,一方面通过它我们方便的高效的并发程序,通过简单地修改就能编写复杂的集合处理算法。
3. Lambda 表达式的优点 那么 Lambda 具体有哪些优点呢?
更加紧凑的代码 :Lambda 表达式可以通过省去冗余代码来减少我们的代码量,增加我们代码的可读性;
更好地支持多核处理 :Java 8 中通过 Lambda 表达式可以很方便地并行操作大集合,充分发挥多核 CPU 的潜能,并行处理函数如 filter、map 和 reduce;
改善我们的集合操作 :Java 8 引入 Stream API,可以将大数据处理常用的 map、reduce、filter 这样的基本函数式编程的概念与 Java 集合结合起来。方便我们进行大数据处理。
4. 我们的第一个例子 前面说了 Lambda 表达式的优点,我们用一个例子来直观的感受下 Lambda 表达式是如何帮我们减少代码行数,增加可读性的。
Swing 是一个与平台无关的 Java 类库(位于 java.awt.* 中),用来编写图形界面( GUI )。里面有一个常见的用法:为了响应用户操作,需要注册一个事件监听器,当用户输入时,监听器就会执行一些操作(这类似于我们网页的上的一个 Botton 按钮,当用户点击按钮后,js 代码会执行相应的动作)。
4.1 使用使用匿名内部类来将行为和点击按钮进行关联 这是我们在 Java 8 以前,通常的写法:
button .addActionListener (new ActionListener (){ @Override public void actionPerformed (ActionEvent actionEvent ) { System .out .println ("button click" ); } }); 代码块123456 在上面的例子中,我们创建了一个对象来实现 ActionListener 接口(这个对象并没有命名,它是一个匿名内部类),这个对象有一个 actionPerformed 方法。当用户点击按钮 button 时,就会调用该方法,输出 button click。
4.2 使用 Lambda 表达式来将行为和点击按钮进行关联 在使用 Lambda 表达式以后的写法:
button .addActionListener (event -> System .out .println ("button click" ));代码块1 我们只用了一行代码就完成了,你是不是一眼就看出来这个点击事件做的就是输出 button click。 关于 Lambda 表 达式其他的两个特点我们将在后续的内容中进行解释。
5. 前置知识 本教程主要讲解的是 Java 8 新特性中的 Lambda 表达式的语法基础以及应用,所以需要学习本教程的读者至少掌握 Java 基础语法,Java 集合,迭代器,还需要了解部分设计模式以及设计原则为后期部分小节学习做铺垫。
6. 小结 本节主要介绍了:
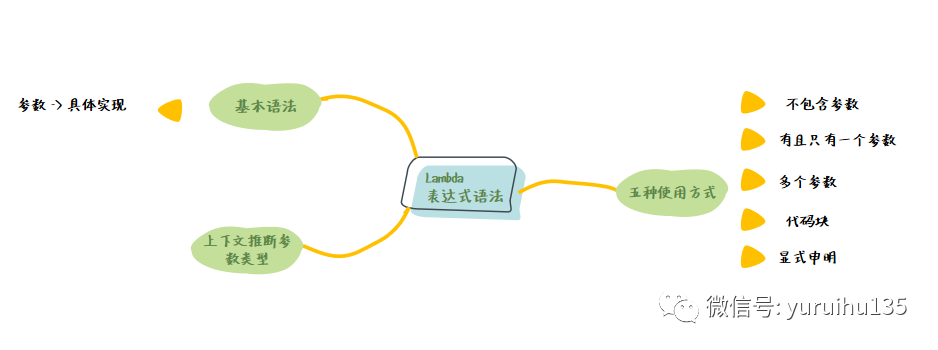
2、Lambda 表达式的语法 本节我们将介绍 Lambda 表达式的语法,了解 Lambda 表达式的基本形式和几种变体,以及编译器是怎么理解我们的 Lambda 表达式的。 掌握了这些基础的知识,我们就能很容易的辨别出 Lambda 表达式,以及它是怎么运作的。
1. 基本语法 现在我们来回顾下第一 个 Lambda 表达式的例子:
button .addActionListener (event -> System .out .println ("button click" ));代码块1 这是一个最基本的 Lambda 表达式,它由三部分组成具体格式是这样子的:
包含一个 Lambda 表达式的运算符 ->,在运算符的左边是输入参数,右边则是函数主体。
概括来讲就是:
Tips: 一段带有输入参数的可执行语句块
Lambda 表达式有这么几个特点:
可选类型声明: 不需要声明参数类型,编译器可以自动识别参数类型和参数值。在我们第一个例子中,并没有指定 event 到底是什么类型;
可选的参数圆括号: 一个参数可以不用定义圆括号,但多个参数需要定义圆括号;
可选的大括号: 如果函数主体只包含一个语句,就不需要使用大括号;
可选的返回关键字: 如果主体只有一个表达式返回值则编译器会自动返回值,大括号需要指明表达式返回了一个数值。
这几个特点是不是看着有点晕呢?不要紧,你只要知道除了我们第一个例子中的 Lambda 表达式的基本形式之外,这些特点还能够形成它的几种变体。接下来我们来看下一个 Lambda 表达式的一些变体。
2. Lambda 表达式的五种形式
2.1 不包含参数
Runnable noArguments = () -> System .out .println ("hello world" );代码块1 在这个例子中,Runnable 接口,只有一个 run 方法,没有参数,且返回类型为 void,所以我们的 Lambda 表达式使用 () 表示没有输入参数。
2.2 有且只有一个参数
ActionListener oneArguments = event -> System .out .println ("hello world" );代码块1 在只有一个参数的情况下 我们可以把 () 省略。
2.3 有多个参数
BinaryOperator < Long > add = (x ,y ) -> x + y ;代码块1 使用 () 把参数包裹起来,并用 , 来分割参数。上面的代码表示。
2.4 表达式主体是一个代码块
Runnable noArguments = () -> { System .out .print ("hello" ); System .out .println ("world" ); } 代码块1234 当有多行代码的时候我们需要使用 {} 把表达式主体给包裹起来。
2.5 显示声明参数类型
BinaryOperator<Long> add = (Long x, Long y) -> x+y ; 代码块1 通常 Lambda 的参数类型都有编译器推断得出的,也可以显示的声明参数类型。
3. 关于 Lambda 表达式的参数类型 我们再来看一下 2.3 的例子:
BinaryOperator < Long > add = (x ,y ) -> x + y ;代码块1 在这个例子中,参数 x, y 和返回值 x+y 我们都没有指定具体的类型,但是编译器却知道它是什么类型。原因就在于编译器可以从程序的上下文推断出来,这里的上下文包含下面 3 种情况:
通过这 3 种上下文就可以推断出 Lambda 表达式的目标类型。
目标类型并不是一个全新的概念,通常我们在 Java 数据初始化的时候就是根据上下文推断出来的。比如:
String [] array = {"hello" ,"world" };代码块1 等号右边的代码我们并没有声明它是什么类型,系统会根据上下文推断出类型的信息。
4. 小结
本节主要介绍了:
掌握这些知识可以帮助我们快速的辨别一个 Lambda 表达式,方便的去理解程序的意图。
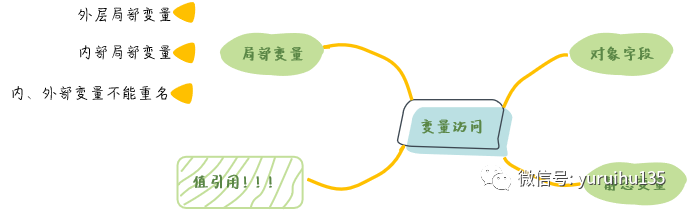
3、Lambda 表达式的变量与作用域 本节我们将分析 Lambda 表达式的局部变量及其作用域进行分析,在这基础上我们会探讨其访问规则背后的原因。
在开始之前我们需要明确一句话:
引用值,而不是变量!
引用值,而不是变量!
引用值,而不是变量!
重要的事情说三遍!!!
1. 访问局部变量 Lambda 表达式不会从父类中继承任何变量名,也不会引入一个新的作用域。Lambda 表达式基于词法作用域,也就是说 Lambda 表达式函数体里面的变量和它外部环境的变量具有相同的语义。
访问局部变量要注意如下 3 点:
可以直接在 Lambda 表达式中访问外层的局部变量;
在 Lambda 表达式当中被引用的变量的值不可以被更改;
在 Lambda 表达式当中不允许声明一个与局部变量同名的参数或者局部变量。
现在我们来仔细说明下这三点。
1.1 可以直接在 Lambda 表达式中访问外层的局部变量 在 Lambda 表达式中可以直接访问外层的局部变量,但是这个局部变量必须是声明为 final 的。
首先我们来看一个例子:
实例演示
import java .util .function .BinaryOperator ;public class LambdaTest1 { public static void main (String [] args ) { final int delta = - 1 ; BinaryOperator < Integer > add = (x , y ) -> x + y + delta ; Integer apply = add .apply (1 , 2 );//结果是2 System .out .println (apply ); } } 可查看在线运行效果
在这个例子中, delta 是 Lambda 表达式中的外层局部变量,被声明为 final,我们的 Lambda 表达式是对两个输入参数 x, y 和外层局部变量 delta 进行求和。
如果这个变量是一个既成事实上的 final 变量的话,就可以不使用 final 关键字。所谓个既成事实上的 final 变量是指只能给变量赋值一次,在我们的第一个例子中, delta 只在初始化的时候被赋值,所以它是一个既成事实的 final 变量。
实例演示
import java .util .function .BinaryOperator ;public class LambdaTest2 { public static void main (String [] args ) { int delta = - 1 ; BinaryOperator < Integer > add = (x , y ) -> x + y + delta ; Integer apply = add .apply (1 , 2 );//结果是2 System .out .println (apply ); } } 相较于第一个例子,我们删除了 final 关键字,程序没有任何问题。
1.2 在 Lambda 表达式当中被引用的变量的值不可以被更改 在 Lambda 表达式中试图修改局部变量是不允许的,那么我们在后面对 delta 赋值会怎么样呢?
public static void main (String ...s ){ int delta = - 1 ; BinaryOperator < Integer > add = (x , y ) -> x + y + delta ; //编译报错 add .apply (1 ,2 ); delta = 2 ; } 代码块123456 这个时候编译器会报错说:
Variable used in lambda expression should be final or effectively final 代码块1
1.3 在 Lambda 表达式当中不允许声明一个与局部变量同名的参数或者局部变量
public static void main (String ...s ){ int delta = - 1 ; BinaryOperator < Integer > add = (delta , y ) -> delta + y + delta ; //编译报错 add .apply (1 ,2 ); } 代码块12345 我们将表达式的第一个参数的名称由 x 改为 delta 时,编译器会报错说:
Variable 'delta' is already defined in the scope 代码块1
2. 访问对象字段与静态变量 Lambda 内部对于实例的字段和静态变量是即可读又可写的。
实例演示
import java .util .function .BinaryOperator ;public class Test { public static int staticNum ; private int num ; public void doTest () { BinaryOperator < Integer > add1 = (x , y ) -> { num = 3 ; staticNum = 4 ; return x + y + num + Test .staticNum ; }; Integer apply = add1 .apply (1 , 2 ); System .out .println (apply ); } public static void main (String [] args ) { new Test ().doTest (); } } 这里我们在 Test类中,定义了一个静态变量 staticNum 和 私有变量 num。并在 Lambda 表达式 add1 中对其作了修改,没有任何问题。
3. 关于引用值,而不是变量 通过前面两节我们对于 Lambda 表达式的变量和作用域有了一个概念,总的来说就是:
Tips: Lambda 表达式可以读写实例变量,只能读取局部变量。
有没有想过这是为什么呢?
实例变量和局部变量的实现不同:实例变量都存储在堆中,而局部变量则保存在栈上。如果在线程中要直接访问一个非 final局部变量,可能线程执行时这个局部变量已经被销毁了。因此,Java 在访问自由局部变量时,实际上是在访问它的副本,而不是访问原始变量。如果局部变量仅仅赋值一次那就没有什么区别了——因此就没有这个限制(也就是既成事实的 final)。
这个局部变量的访问限制也是 Java 为了促使你从命令式编程模式转换到函数式编程模式,这样会很容易使用 Java 做到并行处理(关于命令式编程模式和函数式编程模式我们将在后续内容中做详细的解释)。
4. 小结
本节我们主要介绍了 Lambda 表达式的变量作用域,主要有这么 3 点需要记住:
引用值,而不是变量;
可以读写实例变量;
只能读取局部变量。
最后我们对于 Lambda 表达式对于变量为什么会有这样的访问限制做了相应的分析。
4、Lambda 表达式的引用 所谓 Lambda 表达式的方法引用可以理解为 Lambda 表达式的一种快捷写法,相较于通常的 Lambda 表达式而言有着更高的 可读性 和 重用性 。
Tips: 一般而言,方法实现比较简单、复用地方不多的时候推荐使用通常的 Lambda 表达式,否则应尽量使用方法引用。
Lambda 表达式的引用分为: 方法引用 和 构造器引用 两类。
方法引用的格式为:
类名::方法名
:: 是引用的运算符,其左边是类名,右边则是引用的方法名。
构造器引用的格式为:
类名::new
同样, :: 是引用的运算符,其左边是类名,右边则是使用关键字 new 表示调用该类的构造函数。构造器引用是一种特殊的引用。
通常引用语法格式有以下 3 种:
接下来我们堆上述 3 种引用逐一进行讲解。
1. 静态方法引用 所谓静态方法应用就是调用类的静态方法。
Tips:
被引用的参数列表和接口中的方法参数一致;
接口方法没有返回值的,引用方法可以有返回值也可以没有;
接口方法有返回值的,引用方法必须有相同类型的返回值。
我们来看一个例子:
public interface Finder { public int find (String s1 , String s2 ); } 代码块123 这里我们定义了一个 Finder 接口,其包含一个方法 find ,两个 String 类型的输入参数,方法返回值为 int 类型。
随后,我们创建一个带有静待方法的类 StaticMethodClass:
//创建一个带有静态方法的类 public class StaticMethodClass { public static int doFind (String s1 , String s2 ){ return s1 .lastIndexOf (s2 ); } } 代码块123456 在 StaticMethodClass 类中,我们查找最后一次出现在字符串 s1 中的 s2 的位置。
在这里 Finder 接口的 find 方法和类 StaticMethodClass 的 doFind 方法有相同的输入参数(参数个数和类型)完全相同,又因为 doFind 方法是一个静态方法,于是我们就可以使用静态方法引用了。
最后,我们在 Lambda 表达式使用这个静态引用:
Finder finder = StaticMethodClass :: doFind ;代码块1 此时, Finder 接口引用了 StaticMethodClass 的静态方法 doFind。
2. 参数方法引用 参数方法引用顾名思义就是可以将参数的一个方法引用到 Lambda 表达式中。
Tips: 接口方法和引用方法必须有相同的 参数 和 返回值 。
同样我们使用前面的 Finder 接口为例:
public interface Finder { public int find (String s1 , String s2 ); } 代码块123 我们希望 Finder 接口搜索参数 s1 的出现参数 s2 的位置,这个时候我们会使用 Java String 的 indexOf 方法 String.indexOf 来进行查询,通常我们是这么使用 Lambda 表达式的:
Finder finder = (s1,s2 )-> s1 .indexOf (s2 );代码块1 我们发现,接口 Finder 的 find 方法与 String.indexOf 有着相同的方法签名(相同的输入和返回值),那么我们就可以使用参数方法引用来进一步简化:
//参数方法引用 Finder finder = String :: indexOf ;//调用find方法 int findIndex = finder .find ("abc" ,"bc" )//输出find结果。 System .out .println ("返回结果:" + findIndex )代码块1234567 输出为:
此时,编译器会使用参数 s1 为引用方法的参数,将引用方法与 Finder 接口的 find 方法进行类型匹配,最终调用 String 的 indexOf 方法。
3. 实例方法引用 实例方法引用就是直接调用实例的方法。
Tips: 接口方法和实例的方法必须有相同的参数和返回值。
我们来看一例子: 首先我们定义一个序列化接口:
public interface Serializer { public int serialize (String v1 ); } 代码块123 然后我们定一个转换类 StringConverter:
public class StringConverter { public int convertToInt (String v1 ){ return Integer .valueOf (v1 ); } } 代码块12345 这个时候 Serializer.serialize 方法和 StringConvertor.converToInt 有着相同的方法签名(即,输入和输出都是相同的),那么,我们可以创建一个 StringConvertor 的实例,并通过 Lambda 表达式将其并引用给 convertToInt() 方法。
StringConverter stringConverter = new StringConverter ();Serializer serializer = StringConverter ::convertToInt ;代码块12 我们在第一行代码中创建了 StringConverter 的对象,在第二行代码中,通过 实例方法引用来引用 StringConverter 的 convertToInt 方法。
4. 构造器引用 构造器引用便是引用一个类的构造函数
Tips: 接口方法和对象构造函数的参数必须相同。
其格式如下:
我们来看一个例子:
public interfact MyFactory { public String create (char [] chars ) } 代码块123 我们定义了 MyFactory 接口 有一个 create 方法,接收一个 char[] 类型的输入参数,返回值类型为 String, 它与 String(char[] chars) 这个 String 的构造函数有着相同的方法签名。这个时候我们就可以使用构造器引用了:
MyFactory myfactory = String ::new ;代码块1 它等价于 Lambda 表达式:
MyFactory myfactory = chars -> new String (chars );代码块1
5. 小结
本节我们主要学习了 Lambda 表达式的引用,引用是基于方法调用的事实提供一种简短的语法,让我们无需看完整的代码就能弄明白代码的意图。
5、Lambda 表达式 VS 匿名内部类 本节我们将重点讨论下 Lambda 表达式与匿名内部类之间除了语法外还有哪些差别。再开始讲解之前我们先列出两者重要的两点区别:
我们来看一个例子:
实例演示
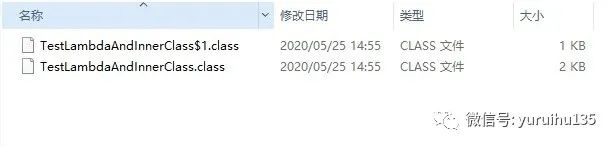
public class TestLambdaAndInnerClass { public void test (){ //匿名类实现 Runnable innerRunnable = new Runnable (){ @Override public void run () { System .out .println ("call run in innerRunnable:\t" + this .getClass ()); } }; //Lambda表达式实现 Runnable lambdaRunnable = () -> System .out .println ("call run in lambdaRunnable:\t" + this .getClass ()); new Thread (innerRunnable ).start (); new Thread (lambdaRunnable ).start (); } public static void main (String ...s ){ new TestLambdaAndInnerClass ().test (); } } 返回结果为:
call run in innerRunnable: class com.github.x19990416.item.TestLambdaAndInnerClass$1 call run in lambdaRunnable: class com.github.x19990416.item.TestLambdaAndInnerClass 代码块12 上面的例子分别在内部类和 Lambda 表达式中调用各自的 this 指针。我们发现 Lambda 表达式的 this 指针指向的是其外围类 TestLambdaAndInnerClass,匿名内部类的指针指向的是其本身。(对于 super 也是一样的结果)
我们来看下编译出来的文件:
其中 TestLambdaAndInnerClass$1.class 是匿名类 innerRunnable 编译出来的 class 文件,对于 Lambda 表达式 lambdaRunnable 则没有编译出具体的 class 文件。
这说明对于 Lambda 表达式而言,编译器并不认为它是一个完全的类(或者说它是一个特殊的类对象),所以也不具备一个完全类的特征。
Tips: 匿名类的 this、 super 指针指向的是其自身的实例,而 Lambda 表达式的 this、 super 指针指向的是创建这个 Lambda 表达式的类对象的实例。
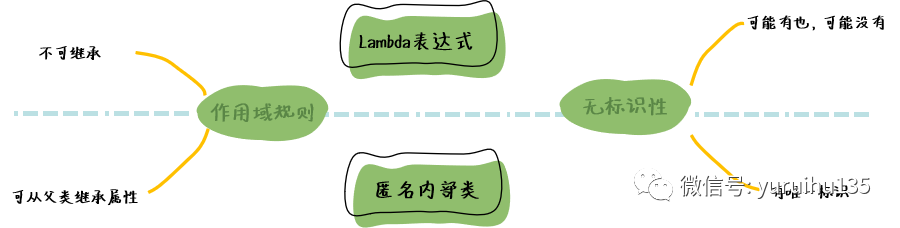
1. 无标识性问题 在 Lambda 表达式出现之前,一个 Java 程序的行为总是与对象关联,以标识、状态和性为为特征。然而 Lambda 表达式则违背了这个规则。
虽然 Lambda 表达式可以共享对象的一些属性,但是表示行为是其唯一的用处。由于没有状态,所以表示问题也就不那么重要了。在 Java 语言的规范中对 Lambda 表达式唯一的要求就是必须计算出其实现的相当的函数接口的实例类。如果 Java 对每个 Lambda 表达式都拥有唯一的表示,那么 Java 就没有足够的灵活性来对系统进行优化。
2. Lambda 表达式的作用域规则 匿名内部类与大多数类一样,由于它可以引用从父类继承下来的名字,以及声明在外部类中的名字,所以它的作用域规则非常复杂。
Lambda 表达式由于不会从父类型中继承名字,所以它的作用于规则要简单很多。除了参数以外,用在 Lambda 表达式中的名字的含义与表达式外面是一样的。
由于 Lambda 表达式的声明就是一个语句块,所以 this 与 super与表达式外围环境的含义一样,换言之它们指向的是外围对象的父类对象。
3. 小结 本节我们主要讨论了 Lambda 表达式与匿名内部类的本质区别,其中重要的是要记住 this 和 super 在两者之间的作用范围。记住这个作用范围可以更好的帮助我们理解 Lambda 表达式的作用域,避免我们在使用 Lambda 表达式中由于作用域引起的 bug,这一类的 bug 在实际中定位是非常困难的。
在 Java 里面,所有的方法参数都是有固定类型的,比如将数字 9 作为参数传递给一个方法,它的类型是 int;字符串 “9” 作为参数传递给方法,它的类型是 String。那么 Lambda 表达式的类型由是什么呢?通过本节我们学习什么是函数式接口,它与 Lambda 表达式的关系。
6、函数式接口概述 在 Java 里面,所有的方法参数都是有固定类型的,比如将数字 9 作为参数传递给一个方法,它的类型是 int;字符串 “9” 作为参数传递给方法,它的类型是 String。那么 Lambda 表达式的类型由是什么呢?通过本节我们学习什么是函数式接口,它与 Lambda 表达式的关系。
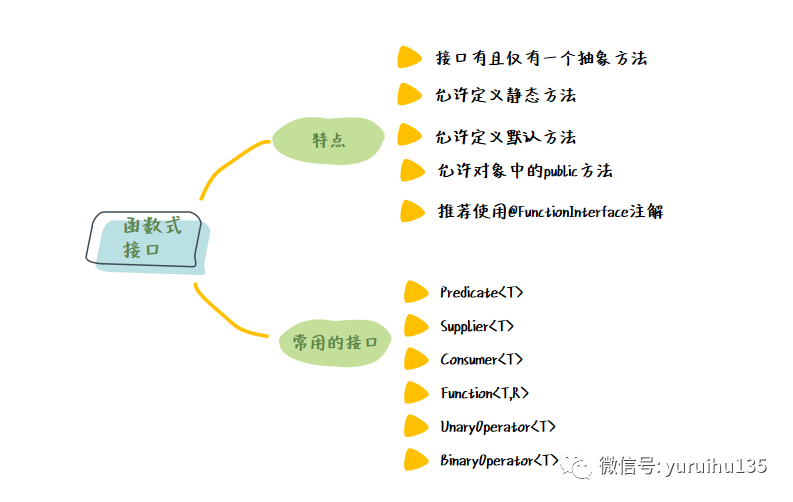
1. 什么是函数式接口 函数式接口(Functional Interface)就是一个有且仅有一个抽象方法,但是可以有多个非抽象方法的接口,它可以被隐式转换为 Lambda 表达式。
Tips: 换句话说函数式接口就是 Lambda 表达式的类型。
在函数式接口中,单一方法的命名并不重要,只要方法签名和 Lambda 表达式的类型匹配即可。
Tips: 通常我们会为接口中的参数其一个有意义的名字来增加代易读性,便于理解参数的用途。
函数式接口有下面几个特点:
接口有且仅有一个抽象方法;
允许定义静态方法;
允许定义默认方法;
允许 java.lang.Object 中的 public 方法;
推荐使用 @FunctionInterface 注解(如果一个接口符合函数式接口的定义,加不加该注解都没有影响,但加上该注解可以更好地让编译器进行检查)。
我们来看函数式接口的例子:
实例演示
@FunctionalInterface interface TestFunctionalInterface { //抽象方法 public void doTest (); //java.lang.Object中的public方法 public boolean equals (Object obj ); public String toString (); //默认方法 public default void doDefaultMethod (){System .out .println ("call dodefaultMethod" );} //静态方法 public static void doStaticMethod (){System .out .println ("call doStaticMethod" );} public static void main (String ...s ){ //实现抽象方法 TestFunctionalInterface test = ()-> { System .out .println ("call doTest" ); }; //调用抽象方法 test .doTest (); //调用默认方法 test .doDefaultMethod (); //调用静态方法 TestFunctionalInterface .doStaticMethod (); //调用toString方法 System .out .println (test .toString ()); } } 我们将得到如下结果:
call doTest call dodefaultMethod call doStaticMethod com.github.x19990416.item.TestFunctionalInterface$$Lambda$1/0x00000008011e0840@63961c42 代码块1234 我们通过 toString 方法可以发现, test 对象被便已成为 TestFunctionalInterface 的一个 Lambda 表达式。
2. @FunctionalInterface 接下来我们再来看下 @FunctionalInterface注解的作用:
首先我们定义一个接口 TestFunctionalInterface,包含两个方法 doTest1 和 doTest2:
interfact TestFunctionalInterface { //一个抽象方法 public void doTest1 (); //另一个抽象方法 public void doTest2 (); } 代码块123456 此时对于编译期而言我们的代码是没有任何问题的,它会认为这就是一个普通的接口。当我们使用 @FunctionalInterface 后:
//这是一个错误的例子!!!! @FunctionalInterface interfact TestFunctionalInterface { //一个抽象方法 public void doTest1 (); //另一个抽象方法 public void doTest2 (); } 代码块12345678 此时,会告诉编译器这是一个函数式接口,但由于接口中有两个抽象方法,不符合函数式接口的定义,此时编译器会报错:
Multiple non-overriding abstract methods found in interface 代码块1
3. 常用的函数式接口 JDK 8 之后新增了一个函数接口包 java.util.function 这里面包含了我们常用的一些函数接口:
接口 参数 返回类型 说明 Predicate T boolean 接受一个输入参数 T,返回一个布尔值结果 Supplier None T 无参数,返回一个结果,结果类型为 TConsumer T void 代表了接受一个输入参数 T 并且无返回的操作 Function<T,R> T R 接受一个输入参数 T,返回一个结果 RUnaryOperator T T 接受一个参数为类型 T,返回值类型也为 TBinaryOperator (T,T) T 代表了一个作用于于两个同类型操作符的操作,并且返回了操作符同类型的结果
3.1 Predicate 条件判断并返回一个Boolean值,包含一个抽象方法 (test) 和常见的三种逻辑关系 与 (and) 、或 (or) 、非 (negate) 的默认方法。
Predicate 接口通过不同的逻辑组合能够满足我们常用的逻辑判断的使用场景。
实例演示
import java .util .function .Predicate ;public class DemoPredicate { public static void main (String [] args ) { //条件判断 doTest (s -> s .length () > 5 ); //逻辑非 doNegate (s -> s .length () > 5 ); //逻辑与 boolean isValid = doAnd (s -> s .contains ("H" ),s -> s .contains ("w" )); System .out .println ("逻辑与的结果:" + isValid ); //逻辑或 isValid = doOr (s -> s .contains ("H" ),s -> s .contains ("w" )); System .out .println ("逻辑或的结果:" + isValid ); } private static void doTest (Predicate < String > predicate ) { boolean veryLong = predicate .test ("Hello World" ); System .out .println ("字符串长度很长吗:" + veryLong ); } private static boolean doAnd (Predicate < String > resource , Predicate < String > target ) { boolean isValid = resource .and (target ).test ("Hello world" ); return isValid ; } private static boolean doOr (Predicate < String > one , Predicate < String > two ) { boolean isValid = one .or (two ).test ("Hello world" ); return isValid ; } private static void doNegate (Predicate < String > predicate ) { boolean veryLong = predicate .negate ().test ("Hello World" ); System .out .println ("字符串长度很长吗:" + veryLong ); } } 可查看在线运行效果
结果如下:
字符串长度很长吗:true 字符串长度很长吗:false 逻辑与的结果:true 逻辑或的结果:true 代码块1234
3.2 Supplier 用来获取一个泛型参数指定类型的对象数据(生产一个数据),我们可以把它理解为一个工厂类,用来创建对象。
Supplier 接口包含一个抽象方法 get,通常我们它来做对象转换。
实例演示
import java .util .function .Supplier ;public class DemoSupplier { public static void main (String [] args ) { String sA = "Hello " ; String sB = "World " ; System .out .println ( getString ( () -> sA + sB ) ); } private static String getString (Supplier < String > stringSupplier ) { return stringSupplier .get (); } } 可查看在线运行效果
结果如下:
上述例子中,我们把两个 String 对象合并成一个 String。
3.3 Consumer 与 Supplier 接口相反,Consumer 接口用于消费一个数据。
Consumer 接口包含一个抽象方法 accept 以及默认方法 andThen 这样 Consumer 接口可以通过 andThen 来进行组合满足我们不同的数据消费需求。最常用的 Consumer 接口就是我们的 for 循环, for 循环里面的代码内容就是一个 Consumer 对象的内容。
实例演示
import java .util .function .Consumer ;public class DemoConsumer { public static void main (String [] args ) { //调用默认方法 consumerString (s -> System .out .println (s )); //consumer接口的组合 consumerString ( // toUpperCase()方法,将字符串转换为大写 s -> System .out .println (s .toUpperCase ()), // toLowerCase()方法,将字符串转换为小写 s -> System .out .println (s .toLowerCase ()) ); } private static void consumerString (Consumer < String > consumer ) { consumer .accept ("Hello" ); } private static void consumerString (Consumer < String > first , Consumer < String > second ) { first .andThen (second ).accept ("Hello" ); } } 可查看在线运行效果
结果如下:
在调用第二个 consumerString 的时候我们通过 andThen 把两个 Consumer 组合起来,首先把 Hello 全部转变成大写,然后再全部转变成小写。
3.4 Function 根据一个类型的数据得到另一个类型的数据,换言之,根据输入得到输出。
Function 接口有一个抽象方法 apply 和默认方法 andThen,通过 andThen 可以把多个 Function 接口进行组合,是适用范围最广的函数接口。
实例演示
import java .util .function .Function ;public class DemoFunction { public static void main (String [] args ) { doApply (s -> Integer .parseInt (s )); doCombine ( str -> Integer .parseInt (str )+ 10 , i -> i *= 10 ); } private static void doApply (Function < String , Integer > function ) { int num = function .apply ("10" ); System .out .println (num + 20 ); } private static void doCombine (Function < String , Integer > first , Function < Integer , Integer > second ) { int num = first .andThen (second ).apply ("10" ); System .out .println (num + 20 ); } } 可查看在线运行效果
结果如下:
上述四个函数接口是最基本最常用的函数接口,需要熟悉其相应的使用场景并能够熟练使用。 UnaryOperator 和 BinaryOperator 作用与 Funciton 类似,大家可以通过 Java 的源代码进一步了解其作用。
4. 小结
本节,我们主要阐述了函数式接口的定义以及其与 Lambda 表达式的关系。并对新增的 java.util.function 包中常用的函数式接口进行了解释。这些接口常用于集合处理中(我们将在后续的内容进一步学习),关于函数式接口主要记住一点,那就是:
接口有且仅有一个抽象方法
7、函数式数据处理 Java 8 中新增的特性其目的是为了帮助开发人员写出更好地代码,其中关键的一部分就是对核心类库的改进。流( Stream )和集合类库便是核心类库改进的内容。
1. 从外部迭代到内部迭代 对于一个集合迭代是我们常用的一种操作,通过迭代我们可以处理返回每一个操作。常用的就是 for 循环了。我们来看个例子:
实例演示
import java .util .Arrays ;import java .util .List ;public class Test { public static void main (String ...s ){ List < Integer > numbers = Arrays .asList (new Integer []{1 ,2 ,3 ,4 ,5 ,6 ,7 }); int counter = 0 ; for (Integer integer : numbers ){ if (integer > 5 ) counter ++ ; } System .out .println (counter ); }} 12345678910111213 可查看在线运行效果
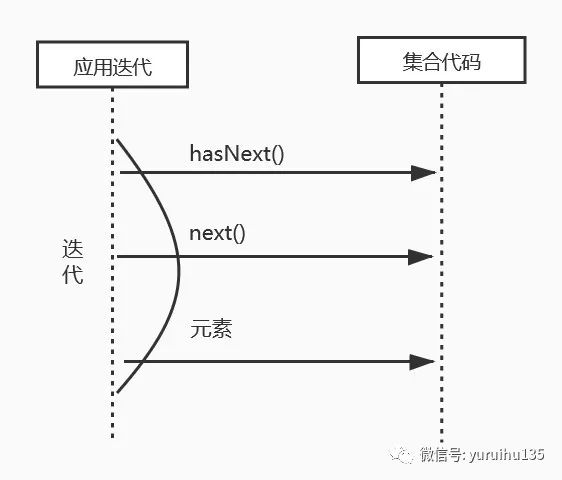
这里我们统计数组 numbers 中大于 5 的元素的个数,我们通过 for 循环对 numbers 数组进行迭代,随后对每一个元素进行比较。这个调用过程如下:
在这个过程中,编译器首先会调用 List 的 iterator() 方法产生一个 Iterator 对象来控制迭代过程,这个过程我们称之为 外部迭代 。在这个过程中会显示调用 Iterator 对象的 hasNext() 和 next() 方法来完成迭代。
这样的外部迭代有什么问题呢?
Tips: 对于循环中不同操作难以抽象。
比如我们前面的例子,假设我们要对大于 5 小于 5 和等于 5 的元素分别进行统计,那么我们所有的逻辑都要写在里面,并且只有通过阅读里面的逻辑代码才能理解其意图,这样的代码可阅读性是不是和 Lambda 表达式的可阅读性有着天壤之别呢?
Java 8 中提供了另一种通过 Stream 流来实现 内部迭代 的方法。我们先来看具体的例子:
实例演示
import java .util .List ;import java .util .Arrays ;public class Test { public static void main (String ...s ){ List < Integer > numbers = Lists .newArrayList (1 ,2 ,3 ,4 ,5 ,6 ,7 ); long counter = numbers .stream ().filter (e -> e > 5 ).count (); System .out .println (counter ); }} 12345678910 可查看在线运行效果
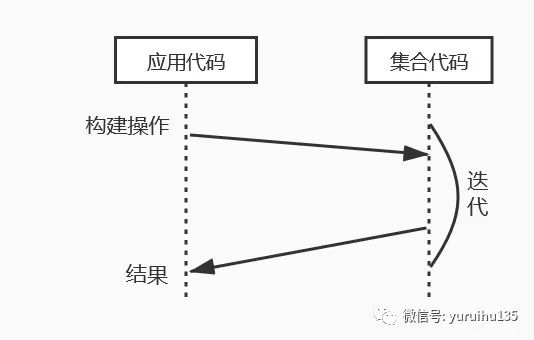
在这个例子中,我们调用 stream() 方法获取到 Stream 对象,然后调用该对象的 filter() 方法对元素进行过滤,最后通过 count() 方法来计算过滤后的 Stream 对象中包含多少个元素对象。
与外部迭代不同,内部迭代并不是返回控制对象 Iterator, 而是返回内部迭代中的相应接口 Stream。进而把对集合的复杂逻辑操作变成了明确的构建操作。
在这个例子中,通过内部迭代,我们把整个过程被拆分成两步:
找到大于 5 的元素;
统计这些元素的个数。
这样一来我们代码的可读性是不是大大提升了呢?
2. 实现机制 在前面的内部迭代例子中,整个操作过程被分成了过滤和计数两个简单的操作。我们再来看一下之前的例子,并做了一些改造:
实例演示
import java .util .ArrayList ;import java .util .Collections ;import java .util .List ;import java .util .stream .Stream ;public class Test { public static void main (String ...s ){ List < Integer > numbers = new ArrayList < Integer > (); Collections .addAll (numbers ,new Integer []{1 ,2 ,3 ,4 ,5 ,6 ,7 }); Stream stream1 = numbers .stream (); numbers .remove (6 ); //直接使用numbers的stream() long counter = numbers .stream ().filter (e -> e > 5 ).count (); System .out .println (counter ); //调用之前的stream1 counter = stream1 .filter (ex -> (Integer )ex > 5 ).count (); System .out .println (counter ); } } 可查看在线运行效果
返回结果:
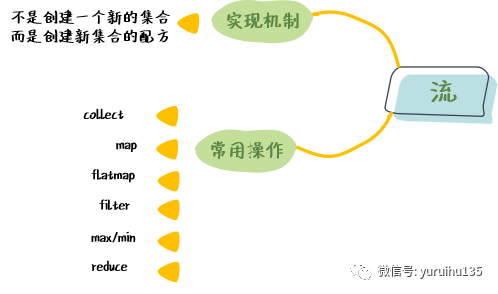
在这个例子中,我们在获取到 Stream 对象 stream1 后删除了数组 numbers 中的最后一个元素,随后分别对 numbers 和 stream1 进行过滤统计操作,会发现两个结果是一样的,stream1 中的内容跟随 numbers 一起做相应的改变。这说明 Stream 对象不是一个新的集合,而是创建新集合的配方 。同样,像 filter() 虽然返回 Stream 对象,但也只是对 Stream 的刻画,并没有产生新的集合。
我们通常对于这种不产生集合的方法叫做 惰性求值方法 ,相对应的类似于 count() 这种返回结果的方法我们叫做 及早求值方法 。
我们可以把多个惰性求值方法组合起来形成一个惰性求值链,最后通过及早求值操作返回想要的结果。这类似建造者模式,使用一系列操作设置属性和配置,最后通过一个 build 的方法来创建对象。通过这样的一个过程我们可以让我们对集合的构建过程一目了然。这也就是 Java 8 风格的集合操作。
3. 常用的流操作 为了更好地理解 Stream API,我们需要掌握它的一些常用操作,接下来我们将逐个学习几种常用的操作。
3.1 collect collect 操作是根据 Stream 里面的值生成一个列表,它是一个求值操作。
Tips: collect 方法通常会结合 Collectors 接口一起使用,是一个通用的强大结构,可以满足数据转换、数据分块、字符串处理等操作。
我们来看一些例子:
生成集合:
实例演示
import java .util .stream .Stream ;import java .util .List ;import java .util .stream .Collectors ;public class Test { public static void main (String ...s ){ List < String > collected = Stream .of ("a" ,"b" ,"c" ).collect (Collectors .toList ()); System .out .println (collected ); }} 可查看在线运行效果
使用 collect(Collectors.toList()) 方法从 Stream 中生成一个列表。
集合转换:
使用 collect 来定制集合收集元素。
实例演示
import java .util .List ;import java .util .stream .Stream ;import java .util .stream .Collectors ;import java .util .TreeSet ;public class Test { public static void main (String ...s ){ List < String > collected = Stream .of ("a" ,"b" ,"c" ,"c" ).collect (Collectors .toList ()); TreeSet < String > treeSet = collected .stream ().collect (Collectors .toCollection (TreeSet ::new )); System .out .println (collected ); System .out .println (treeSet ); }}
输出结果: [a, b, c, c] [a, b, c] 代码块123 使用 toCollection 来定制集合收集元素,这样就把 List 集合转换成了 TreeSet
转换成值:
使用 collect 来对元素求值。
实例演示
import java .util .List ;import java .util .stream .Stream ;import java .util .stream .Collectors ;public class Test { public static void main (String ...s ){ List < String > collected = Stream .of ("a" ,"b" ,"c" ).collect (Collectors .toList ()); String maxChar = collected .stream ().collect (Collectors .maxBy (String ::compareTo )).get (); System .out .println (maxChar ); }} 可查看在线运行效果
上面我们使用 maxBy 接口让收集器生成一个值,通过方法引用调用了 String 的 compareTo 方法来比较元素的大小。同样还可以使用 minBy 来获取最小值。
数据分块:
比如我们对于数据 1-7 想把他们分成两组,一组大于 5 另外一组小于等于 5,我们可以这么做:
实例演示
import java .util .List ;import java .util .Map ;import java .util .stream .Stream ;import java .util .stream .Collectors ;public class Test { public static void main (String ...s ){ List < Integer > collected = Stream .of (1 ,2 ,3 ,4 ,5 ,6 ,7 ).collect (Collectors .toList ()); Map < Boolean ,List < Integer >> divided = collected .stream ().collect (Collectors .partitioningBy (e -> e > 5 )); System .out .println (divided .get (true )); System .out .println (divided .get (false )); }} 可查看在线运行效果
输出结果: [6, 7] [1, 2, 3, 4, 5] 代码块123 通过 partitioningBy 接口可以把数据分成两类,即满足条件的和不满足条件的,最后将其收集成为一个 Map 对象,其 Key 为 Boolean 类型, Value 为相应的集合元素。
同样我们还可以使用 groupingBy 方法来对数据进行分组收集,这类似于 SQL 中的 group by 操作。
字符串处理:
collect 还可以来将元素组合成一个字符串。
实例演示
import java .util .List ;import java .util .stream .Stream ;import java .util .stream .Collectors ;public class Test {public static void main (String ...s ){ List < String > collected = Stream .of ("a" ,"b" ,"c" ).collect (Collectors .toList ()); String formatted = collected .stream ().collect (Collectors .joining ("," ,"[" ,"]" )); System .out .println (formatted ); } } 可查看在线运行效果
这里我们把 collected 数组的每个元素拼接起来,并用 [ ] 包裹。
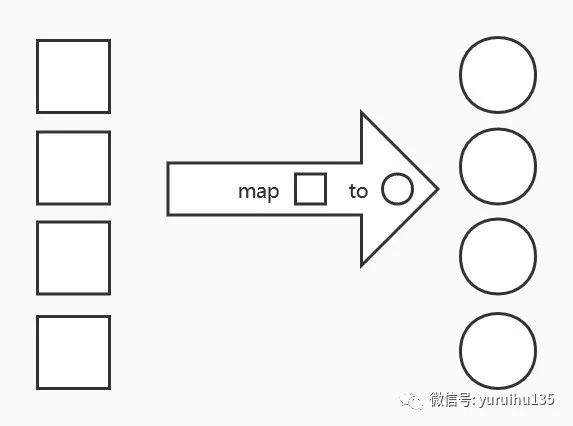
3.2 map map 操作是将流中的对象换成一个新的流对象,是 Stream 上常用操作之一。其示意图如下:
比如我们把小写字母改成大写,通常我们会使用 for 循环:
实例演示
import java .util .List ;import java .util .ArrayList ;import java .util .Collections ;public class Test {public static void main (String ...s ){ List < String > collected = new ArrayList <> (); List < String > newArr = new ArrayList <> (); Collections .addAll (newArr ,new String []{"a" ,"b" ,"c" }); for (String string : newArr ){ collected .add (string .toUpperCase ()); } System .out .println (collected ); } } 可查看在线运行效果
此时,我们可以使用 map 操作来进行转换:
实例演示
import java .util .List ;import java .util .stream .Stream ;import java .util .stream .Collectors ;public class Test { public static void main (String ...s ){ List < String > collected = Stream .of ("a" ,"b" ,"c" ).collect (Collectors .toList ()); List < String > upperCaseList = collected .stream ().map (e -> e .toUpperCase ()).collect (Collectors .toList ()); System .out .println (upperCaseList ); }} 可查看在线运行效果
在 map 操作中,我们 把 collected 中的每一个元素转换成大写,并返回。
3.3 flatmap flatmap 与 map 功能类似,只不过 map 对应的是一个流,而 flatmap 可以对应多个流。
我们来看一个例子:
实例演示
import java .util .List ;import java .util .Arrays ;import java .util .stream .Collectors ;public class Test { public static void main (String ...s ){ List < String > nameA = Arrays .asList ("Mahela" , "Sanga" , "Dilshan" ); List < String > nameB = Arrays .asList ("Misbah" , "Afridi" , "Shehzad" ); List < List < String >> nameSets = Arrays .asList (nameA ,nameB ); List < String > flatMapList = nameSets .stream () .flatMap (pList -> pList .stream ()) .collect (Collectors .toList ()); System .out .println (flatMapList ); }} 可查看在线运行效果
返回结果:[Mahela, Sanga, Dilshan, Misbah, Afridi, Shehzad] 代码块1 通过 flatmap 我们把集合 nameSets 中的字集合合并成了一个集合。
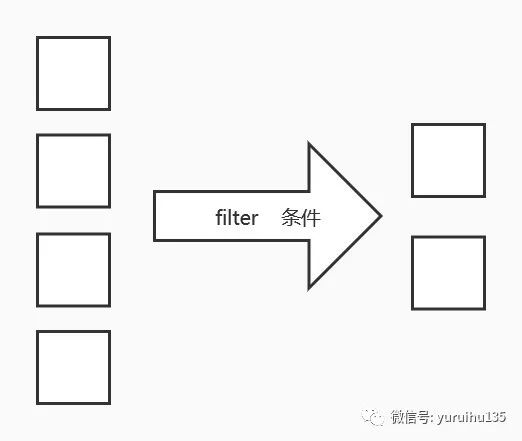
3.4 filter filter 用来过滤元素,在元素遍历时,可以使用 filter 来提取我们想要的内容,这也是集合常用的方法之一。其示意图如下:
我们来看一个例子:
实例演示
import java .util .List ;import java .util .ArrayList ;import java .util .Collections ;import java .util .stream .Collectors ;public class Test { public static void main (String ...s ) { List < Integer > numbers = new ArrayList <> (); Collections .addAll (numbers ,new Integer []{1 ,2 ,3 ,4 ,5 ,6 ,7 }); List < Integer > collected = numbers .stream () .filter (e -> e > 5 ).collect (Collectors .toList ()); System .out .println (collected ); }} 可查看在线运行效果
此时, filter 会遍历整个集合,将满足将满足条件的元素提取出来,并通过收集器收集成新的集合。
3.5 max/min max/min 求最大值和最小值也是集合上常用的操作。它通常会与 Comparator 接口一起使用来比较元素的大小。示例如下:
实例演示
import java .util .List ;import java .util .Collections ;public class Test { public static void main (String ...s ) { List < Integer > numbers = new ArrayList <> (); Collections .addAll (numbers ,new Integer []{1 ,2 ,3 ,4 ,5 ,6 ,7 }); Integer max = numbers .stream ().max (Comparator .comparing (k -> k )).get (); Integer min = numbers .stream ().min (Comparator .comparing (k -> k )).get (); System .out .println ("max:" + max ); System .out .println ("min:" + min ); }} 可查看在线运行效果
我们可以在 Comparator 接口中定制比较条件,来获得想要的结果。
3.6 reduce reduce 操作是可以实现从流中生成一个值,我们前面提到的如 count、 max、 min 这种及早求值就是由 reduce 提供的。我们来看一个例子:
实例演示
import java .util .stream .Stream ;public class Test { public static void main (String ...s ) { int sum = Stream .of (1 ,2 ,3 ,4 ,5 ,6 ,7 ).reduce (0 ,(acc ,e )-> acc + e ); System .out .println (sum ); }}
上面的例子是对数组元素进行求和,这个时候我们就要使用 reduce 方法。这个方法,接收两个参数,第一个参数相当于是一个初始值,第二参数则为具体的业务逻辑。上面的例子中,我们给 acc 参数赋予一个初始值 0 ,随后将 acc 参数与各元素求和。
4. 小结
以上我们学习了 Java 8 的流及常用的一些集合操作。我们需要常用的函数式接口和流操作非常熟悉才能更好地使用这些新特性。
另外,请思考一个问题,在本节关于集合的操作中都将集合通过 stream() 方法转换成了 Stream 对象,那么我们还有必要对外暴露一个集合对象(List 或者 Set)吗?
Tips: 在编程过程中,使用 Stream 工厂比对外暴露集合对象要更好一些。仅需要暴露 Stream 接口,在实际操作中无论怎么使用都影响内部的集合。
所以,Java 8 风格不是一蹴而就的,我们可以对已有的代码进行重构来练习和强化 Java 8 的编程风格,时间长了自然就对 Stream 对象有更深的理解了。
8、Lambda 表达式修改设计模式 本节内容并不是讨论设计模式,而是讨论如何使用 Lambda 表达式让现有的设计模式变得更简洁,或者在某些情况是有一些不同的实现方式。我们可以从另一个角度来学习使用和理解 Lambda 表达式。
Tips: 要更好地理解本节内容需要对涉及的四个设计模式有一定的了解,具体可以查阅相关资料。
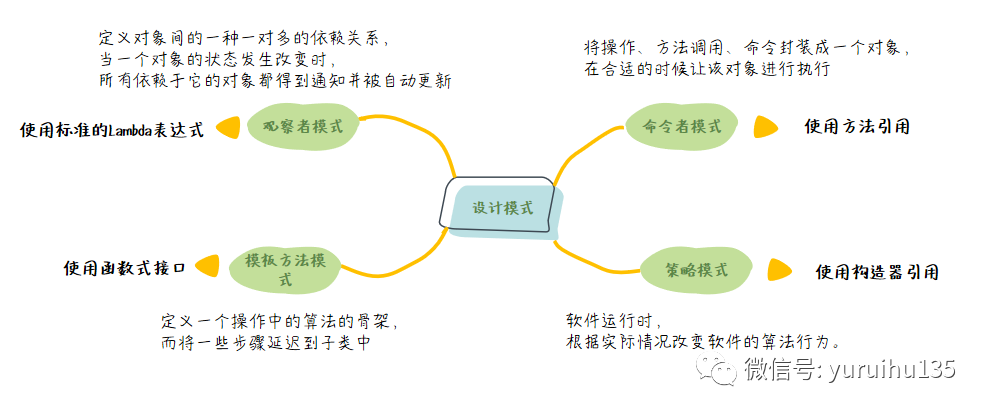
1. 命令者模式 命令者模式是将操作、方法调用、命令封装成一个对象,在合适的时候让该对象进行执行。
它包五个角色:
客户端(Client) :发出命令;
调用者(Invoker) :调用抽象命令,还可以记录执行的命令;
接受者(Receiver) :命令的实际执行者,一个命令会存在一个或多个接收者;
抽象命令(Command) :定义命令执行方法;
具体命令(Concrete Command) :调用接收者,执行命令的具体方法。
命令者模式被大量运用在组件化的图形界面系统、撤销功能、线城市、事务和向导中。我们来看一个例子,我们实现一个将一系列命令录制下来的功能,有点类似于 Word 中的撤销功能那样记录每一步的操作。
//定义一个命令接收者,包含打开、关闭和保存三个操作 public class Editor { public void save (){ System .out .println ("do save" ) } public void open (); public void close (); } // 定名命令对象,所有操作都要实现这个接口 public interface Action { public void perform (); } //实现保存命令操作 public Save implements Action { private final Editor editor ; public Save (Editor editor ){ this .editor = editor ; } public void perform (){ editor .save (); } } //实现打开命令操作 public class Open implements Action { private final Editor editor ; public Open (Editor editor ){ this .editor = editor ; } public void perform (){ editor .open (); } } //实现关闭命令操作 public class Close implements Action { private final Editor editor ; public Close (Editor editor ){ this .editor = editor ; } public void perform (){ editor .close (); } } //定义命令发起者来记录和顺序执行命令 public class Invoker { private final List < Action > actions = new ArrayList <> (); public void record (Action action ){ actions .add (action ); } public void run (){ for (Action action : actions ) { action .perform (); } } } //定义客户端,用来记录和执行命令 public class Client { public static void main (String ...s ){ Invoker invoker = new Invoker (); Editor editor = new Editor (); //记录保存操作 invoker .record (new Save (editor )); //记录打开操作 invoker .record (new Open (editor )); //记录关闭操作 invoker .record (new Close (editor )); invoker .run (); } } 输出结果: do save do open do close 代码块12345 以上是一个完整的命令者模式的例子,我们使用 Lambda 表达式来修改客户端:
public class Client { public static void main (String ...s ){ Invoker invoker = new Invoker (); Editor editor = new Editor (); //记录保存操作 invoker .record (()-> editor .open ()); //记录打开操作 invoker .record (()-> editor .save ()); //记录关闭操作 invoker .record (()-> editor .close ()); invoker .run (); } } 代码块12345678910111213 我们使用引用方法来修改客户端:
public class Client { public static void main (String ...s ){ Invoker invoker = new Invoker (); Editor editor = new Editor (); //记录保存操作 invoker .record (editor ::open ); //记录打开操作 invoker .record (editor ::save ); //记录关闭操作 invoker .record (editor ::close ); invoker .run (); } } 通过这样的改造,我们的代码意图更加明显了呢,一看就明白具体记录的是哪个操作。
2. 策略模式 策略模式是软件运行时,根据实际情况改变软件的算法行为。
常见的策略模式就是文件压缩软件,通常一个压缩软件可以支持多种压缩算法如 zip 、gzip、rar 等,通过策略模式可以让压缩软件根据我们具体的操作来实现不同的压缩算法。我们来看一个压缩数据的策略模式的例子:
//定义压缩策略接口 public interface CompressionStrategy { public OutputStream compress (OutputStream data ) throws IOException ; } //gzip压缩策略 public class GzipStrategy implements CompressionStrategy { @Override public OutputStream compress (OutputStream data ) throws IOException { return new GZIPOutputStream (data ); } } //zip压缩策略 public class ZipStrategy implements CompressionStrategy { @Override public OutputStream compress (OutputStream data ) throws IOException { return new ZipOutputStream (data ); } } //在构造类时提供压缩策略 public class Compressor { private final CompressionStrategy strategy ; public Compressor (CompressionStrategy strategy ){ this .strategy = strategy ; } public void compress (Path inFiles , File outputFile ) throws IOException { try (OutputStream outputStream = new FileOutputStream (outputFile )){ Files .copy (inFiles ,strategy .compress (outputStream )); } } } 代码块123456789101112131415161718192021222324252627282930313233 //使用具体的策略初始化压缩策略 //gzip策略 Compressor gzipCompressor = new Compressor (new GzipStrategy ()); //zip策略 Compressor zipCompressor = new Compressor (new ZipStrategy ());代码块12345 以上就是一个完整的 zip 和 gzip 的压缩策略。现在我们用 Lambda 表达式来优化初始化压缩策略
//使用构造器引用优化初始化压缩策略 //gzip策略 Compressor gzipCompressor = new Compressor (GzipStrategy ::new ); //zip策略 Compressor zipCompressor = new Compressor (ZipStrategy ::new );代码块12345
3. 观察者模式 观察者模式是定义对象间的一种一对多的依赖关系,当一个对象的状态发生改变时,所有依赖于它的对象都得到通知并被自动更新。
观察者模式被适用于消息通知、触发器之类的应用场景中
观察者模式包含三个类 主题(Subject)、观察者(Observer)和客户端(Client)。Subject 对象带有绑定观察者到 Client 对象和从 Client 对象解绑观察者的方法。
我们来看一个例子:现在我们用观察者模式实现根据输入的数字,自动将输入的数字其转变成对应十六进制和二进制。
//定义一个观察者 public interface Observer { public void update (int num ); } //创建主题 public static class Subject { private List < Observer > observers = new ArrayList <> (); private int num ; public int getNum (){ return num ; } private void setNum (int num ){ this .num = num ; this .notifyAllObservers (); } private void addObserver (Observer observer ) { observers .add (observer ); } private void notifyAllObservers (){ for (Observer observer :observers ){ observer .update (num ); } } } //创建二进制观察者 public static class BinaryObserver implements Observer { private Subject subject ; @Override public void update (int num ) { System .out .println ( "Binary String: " + Integer .toBinaryString ( num ) ); } } //创建十六进制观察者 public static class HexObserver implements Observer { @Override public void update (int num ) { System .out .println ( "Hex String: " + Integer .toHexString ( num ) ); } } //使用 Subject 和实体观察者对象 public class Demo { public static void main (String ... s ){ Subject subject = new Subject (); subject .addObserver (new BinaryObserver ()); subject .addObserver (new HexObserver ()); System .out .println ("first input is:11" ); subject .setNum (11 ); System .out .println ("second input is:15" ); subject .setNum (15 ); } } 输出结果: first input is:11 Binary String : 1011 Hex String : b second input is:15 Binary String : 1111 Hex String : f 代码块12345678 同样我们使用 Lambda 表达式来修改 Demo 类:
public class Demo { public static void main (String ...s ){ Subject subject = new Subject (); subject .addObserver ( num -> System .out .println ( "Binary String: " + Integer .toBinaryString ( num ))); subject .addObserver ( num -> System .out .println ( "Hex String: " + Integer .toHexString (num ))); System .out .println ("first input is:11" ); subject .setNum (11 ); System .out .println ("second input is:15" ); subject .setNum (15 ); } } 在这个例子中,我们实际上是省去了 BinaryObserver 和 HexObserver 两个类的定义,直接使用 Lambda 表达式来描述二进制和十六进制转化的逻辑。
4. 模板方法模式 模板方法模式是定义一个操作中的算法的骨架,从而将一些步骤延迟到子类中。模板方法使得子类可以不改变一个算法的结构即可重定义该算法的某些特定步骤。
通常对于一些重要的复杂方法和多个子类共有的方法且逻辑相同的情况下会使用模板方法模式。比如用户第三方用户认证的时候就比较适合使用模板方法。
我们来看一个例子:假设我们现在需要用到微信、微博的第三方用户授权来获取用户的信息。
//使用模板方法模式描述获取第三方用户信息的过程 public abstract class Authentication { public void checkUserAuthentication (){ checkIdentity (); fetchInfo (); } protected abstract void checkIdentity (); protected abstract void fetchInfo (); } //微信用户 public class WechatAuthenication extends Authentication { @Override protected void checkIdentity () { System .out .println ("获得微信用户授权" ); } @Override protected void fetchInfo () { System .out .println ("获取微信用信息" ); } } //微信用户 public class WeiboAuthenication extends Authentication { @Override protected void checkIdentity () { System .out .println ("获得微博用户授权" ); } @Override protected void fetchInfo () { System .out .println ("获取微博用信息" ); } } //调用模板方法 public class Demo { public static void main (String ...s ){ Authentication auth = new WechatAuthenication (); auth .checkUserAuthentication (); auth = new WeiboAuthenication (); auth .checkUserAuthentication (); } } 输出结果: 获得微信用户授权 获取微信用信信息 获得微博用户授权 获取微博用信信息 代码块123456 现在我们使用 Lambda 表达式换个角度来思考模板方法模式。如果我们用函数式接口来组织模板方法中的调用过程,相比使用继承来构建要显得灵活的多。
//定义一个处理接口,用来处理一项事务,如授权或者获取信息。 public interface Processer { public void process (); } //封装调用过程 public class Authentication { private final Processer identity ; private final Processer userinfo ; public Authentication (Criteria identity ,Criteria userinfo ){ this .identity = identity ; this .userinfo = userinfo ; } public void checkUserAuthentication (){ identity .process (); userinfo .process (); } } //使用模板方法 public class Demo { Authentication auth = new Authentication (()-> System .out .println ("获得微信用户授权" ), ()-> System .out .println ("获取微信用户信息" )); auth .checkUserAuthentication (); auth = new Authentication (()-> System .out .println ("获得微博用户授权" ), ()-> System .out .println ("获取微博用户信息" )); auth .checkUserAuthentication (); } 输出结果: 获得微信用户授权 获取微信用信信息 获得微博用户授权 获取微博用信信息 代码块123456 此时,我们的模板方法得到了大幅的简化,同时通过函数接口让模板方法获得了极大的灵活性。
5. 小结
本节我们讨论如何使用 Lambda 表达式让我们的设计模式变得更简单、更好用。这里我们使用了四个例子从不同的角度来。
命令者模式 :我们使用 Lamabda 表达式的方法引用来进行改造;
策略模式 :我们使用了 Lambda 表达式的构造器引用来进行改造;
观察者模式 :我们使用了标准的 Lambda 表达式来进行改造;
模板方法模式 :我们使用了函数式接口来进行改造。
目的是希望给大家一点启发,在平常的编码过程中去思考如何使用 Lambda 表达式来设计我们的程序。对于其他的设计模式如果感兴趣的话可以自己尝试下去修改它们。
8、Lambda 程序中的应用 通过前面的内容我们对于 Lambda 表达式以及函数式编程已经有了一定的了解,对于集合方面的使用也有了概念,那么,在本节我们将从一个日志改造的例子出发,探讨下如何在我们的程序中更好地使用 Lambda 表达式。
Tips: 本节内容有点分散,主要是启发大家的思路
1. 让我们的类支持 Lambda 表达式 日志记录工具是我们平时用的最多的一个工具,比如 SLF4J、Log4j 等,可以帮助我们快速查看程序的信息、定位问题,也在一定程度上增加了系统开销,通常我们在写 debug 日志的时候为了降低会进行日志级别的判定 (在本例中我们使用的是 Log4j 2)
public class DemoLogger { public static void main (String [] args ) { Logger logger = LogManager .getLogger (DemoLogger .class ); if (logger .isDebugEnabled ()){ logger .debug ("这是一个debug日志" ); } } } 想必上面的代码应该都非常熟悉,在 Log4j 2 中提供了 Lambda 表达式实现的日志记录方法,对于上述代码我们可以简化为:
public class DemoLogger { public static void main (String [] args ) { Logger logger = LogManager .getLogger (DemoLogger .class ); logger .debug (()-> "这是一个debug日志" ); } } 通过查看源代码我们可以发现 Logger 对象提供了一个 Supplier 的 debug 方法:
@Override public void debug (final Supplier <?> msgSupplier ) { logIfEnabled (FQCN , Level .DEBUG , null , msgSupplier , (Throwable ) null ); } @Override public void logIfEnabled (final String fqcn , final Level level , final Marker marker , final Supplier <?> msgSupplier , final Throwable t ) { if (isEnabled (level , marker , msgSupplier , t )) { logMessage (fqcn , level , marker , msgSupplier , t ); } } 在这个方法中,它通过 logIfEnabled 判断是否为 debug 进而决定是否调用 supplier 对象的内容。这给了我们一个启发,那就是:
我们可以运用 java.util.funciton 中的接口来重新封装我们原有的类来支持 Lambda 表达式,进而简化我们的代码。
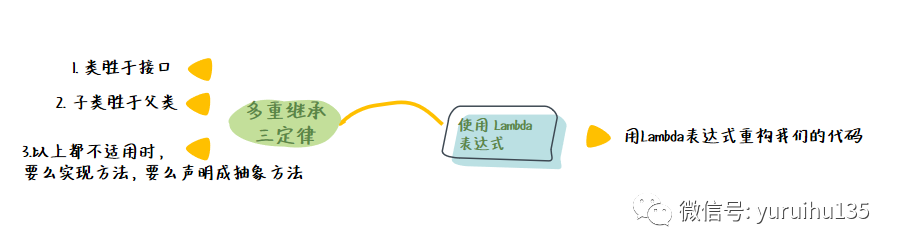
2. 多重继承 在 Java 中接口是允许多重继承的,那么如果多个接口有着相同的默认方法的情况下会怎么样呢?
public class MultipleInterface { public interface RedBox { public default String color (){ return "red" ; } } public interface BlueBox { public default String color (){ return "blue" ; } } public class CombineBox implements RedBox ,BlueBox { } } 在上面的代码中,我们定义了两个接口 RedBox 和 BlueBox 都有相同的默认方法 color,类 CombineBox 同时实现 RedBox 和 BlueBox,此时,由于编译器不清楚应该继承哪个接口,所以报错:
MultipleInterface.CombineBox inherits unrelated defaults for color() from types MultipleInterface.RedBox and MultipleInterface.BlueBox 代码块1 此时,我们可以使用同方法重载来明确方法内容,当然我们可以通过 super 语法来给编译器明确使用哪一个默认接口:
public class CombineBox implements RedBox ,BlueBox { public String color (){ return RedBox .super .color (); } } 上述的内容我们主要是对默认方法的工作原理做了一个简单的介绍,对于默认方法通常有三条定律来帮助我们使用默认方法:
类胜于接口:如果在继承链中有声明的方法,那么就可以忽略接口中定义的方法 (这样可以让我们的代码向后兼容);
子类胜于父类:如果一个接口继承了另外一个接口,而且两个接口都定义了一个默认方法,那么子类中定义的方法将生效;
如果上述两条都不适用,那么子类要么需要实现该方法,要么将该方法声明成抽象方法 ( abstract )。
小结
本节从类的重新和接口继承两方面介绍了我们如何重新封装我们的类来支持 Lambda 表达式,以及在函数接口在多继承的情况下出现默认方法冲突时如何去编写我们的代码。大家可以在平时的编码过程中按照上述的思路逐步练习封装自己原来的代码,自然就会有自己的心得体会。
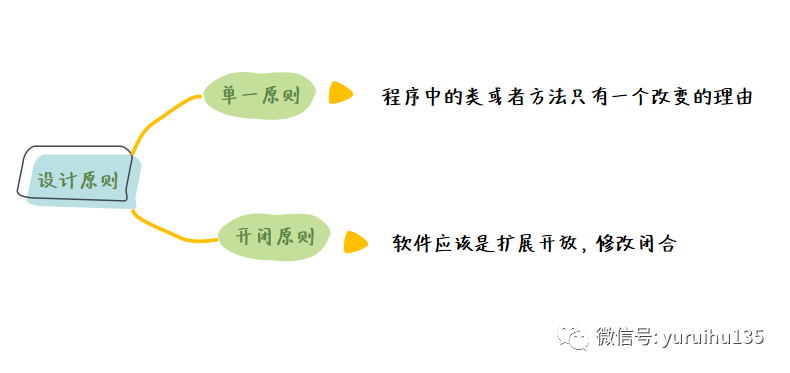
Lambda 表达式的设计原则 Java 编程最基本的原则就是要追求高内聚和低耦合的解决方案和代码模块设计,这里我们主要讨论在 Lambda 表达式的环境下来设计我们程序时的两点原则: 单一原则 和 开放闭合原则 。
1. 单一原则 程序中的类或者方法只有一个改变的理由
当需要修改某个类的时候原因有且只有一个。换句话说就是让一个类只做一种类型责任,当这个类需要承当其他类型的责任的时候,就需要分解这个类。类被修改的几率很大,因此应该专注于单一的功能。如果你把多个功能放在同一个类中,功能之间就形成了关联,改变其中一个功能,有可能中止另一个功能,这时就需要新一轮的测试来避免可能出现的问题,非常耗时耗力。
我们来看一个质数统计的例子:
//这是一个违反单一原则的例子 public SRPDemo { public static long countPrimes (int maxNum ){ long total = 0 ; for (int i = 1 ; i < maxNum ;i ++ ){ boolean isPrime = true ; for ( int j = 2 ; j < i ;j ++ ){ if (i % j == 0 ){ isPrime = false ; } } if (isPrime ){ total = total + 1 ; } } return total ; } public static void main (String ...s ){ System .out .println (countPrimes (100 )); } } 输出结果: 26 上面的例子违反了单一原则,一个方法包含了两重职责:
我们把上面的代码重构,将两种职责拆分到两个方法中:
//符合单一原则的例子 public SRPDemo { //计数 public static long countPrimes (int maxNum ){ long total = 0 ; for (int i = 1 ;i < maxNum ;i ++ ){ if (isPrime (i )) total = total + 1 ; } return total ; } //判断是否为一个质数 public static boolean isPrime (int num ){ for (int i = 2 ;i < num ; i ++ ){ if (num % i == 0 ){ return false ; } } return true ; } public static void main (String ...s ){ System .out .println (countPrimes (100 )); } } 代码块12345678910111213141516171819202122232425 我们现在使用集合流来重构上面代码:
public SRPDemo { public static long countPrimes (int maxNum ){ return IntStream .range (1 ,maxNum ).filter (MultipleInterface ::isPrime ).count (); } public static boolean isPrime (int num ){ return IntStream .range (2 ,num ).allMatch (x -> num % x != 0 ); } public static void main (String ...s ){ System .out .println (countPrimes (100 )); } } 可见,我们使用集合流在一定程度上可以轻松地帮我们实现单一原则。
2. 开放闭合原则 软件应该是扩展开放,修改闭合
我们来看一个发送消息的例子,假设我们现在有一个消息通知模块用来发送邮件和短信:
//这是一个违反开放闭合原则的例子 public class OCPDemo { //发送邮件 public boolean sendByEmail (String addr , String title , String content ) { System .out .println ("Send Email" ); return true ; } //发送短信 public boolean sendBySMS (String addr , String content ) { System .out .println ("Send sms" ); return true ; } } 想必很多人都会这么写,这么写有一个问题,如果哪一天需求变更要求增消息通知,这个时候不仅需要增加一个 sendWechat的方法,还需要在调用它的地方进行修改,所以违反了 OCP 原则。现在我们来做一下修改:
//一个满足开放闭合原则的例子 public class OCPDemo { @Data public static class Message { private String addr ; private String title ; private String content ; private int type ; } public boolean send (Message message ){ switch (message .getType ()){ case 0 : { System .out .println ("Send Email" ); return true ; } case 1 :{ System .out .println ("Send sms" ); return true ; } case 2 :{ System .out .println ("Send QQ" ); return true ; } default :return false ; } } } 代码块123456789101112131415161718192021222324252627 我们创建了一个 Message 对象来描述发送消息的所有信息,并增加了一个 type 字段用来区分发送渠道。在遇到类似的情况窝子需要在 send 方法中增加一个对应 渠道类型 type 的处理逻辑就可以了,对存量代码无需求改。满足了 OCP 原则。
现在我们再来看下使用函数式接口怎么来优化我们的程序:
@Data public class OCPDemo { @Data public static class Message { private String addr ; private String title ; private String content ; } private Message message ; public boolean send (Function < Message , Boolean > function ){ return function .apply (message ); } public static void main (String ...s ){ Message message = new Message (); message .setTitle ("this is a qq msg" ); OCPDemo demo = new OCPDemo (); demo .setMessage (message ); demo .send ((msg )-> { System .out .println ("send qq:\t" + msg .getTitle ()); return true ; }); } } 此时,我们运用函数接口 Function 来处理 Message,省去了消息类型的判断,仅当调用的时候决定使用哪种渠道发送,当然我们可以把发送逻辑都写在一个工具类里面,利用 Lambda 引用来调用。
3. 小结
本节主要讨论的是我们如何在我们的程序设计中来使用 Lambda 表达式时所涉及的两条原则 —— 单一原则 和 开放闭合原则 。
这里关注的是程序整体,而不是具体的某一个方法。其前提是对于 Lambda 表达式的深度理解和熟练运用,为了说明问题,例子大多相对简单,想了解更详细的设计原则还是需要阅读相关的专著(比如 S.O.L.I.D 原则),并在日常的编码过程中不断实践和思考。






 本节主要介绍了:
本节主要介绍了: