





温馨提示:要看高清无码套图,请使用手机打开并单击图片放大查看。
在前面的博文里,我已经介绍了
原创 | 大数据入门基础系列之浅谈Hive和HBase的区别
原创 | 大数据入门基础系列之详谈Hive的数据定义语言(DDL)
原创 | 大数据入门基础系列之详谈Hive的数据操作语言(DML)
原创 | 大数据躺过的坑内部收徒201801期(目前仅面向在校学生)(少量名额)
原创 | 大数据入门基础系列之Hive的驱动器(包括解释器、编译器、优化器、执行器)
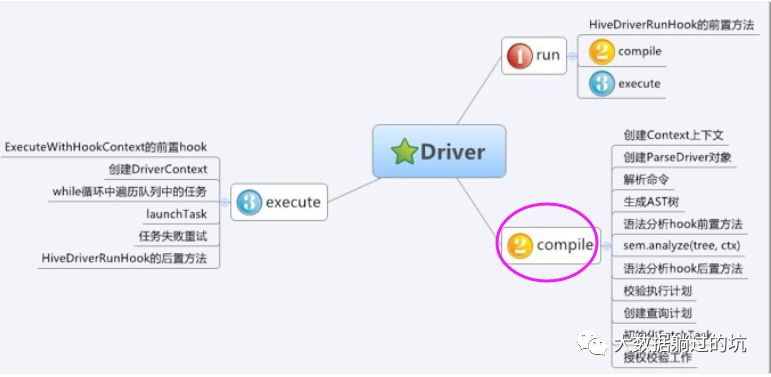
可以看得出,对于Hive的Driver其实是有3种途径的。
即(1)CLI (2)JDBC/ODBC (3)Web GUI
对于
Hive源码分析:CLI入口类
推荐博文
http://blog.javachen.com/2013/08/21/hive-CliDriver.html
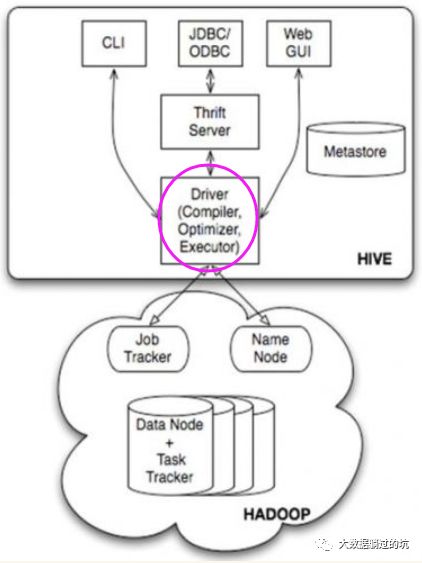
无论使用CLI、Thrift Server、JDBC还是自定义的提交工具,最终的HQL都会传给Driver实例,执行Driver.run()方法。从这种设计也可以看出,如果您要开发一套自定义的Hive作业提交工具,最好的方式是引用Driver实例,调用相关方法进行开发。
而Driver.run()方法,获得了这样一个HQL,则会执行两个重要的步骤:编译和执行,即Driver.complie()和Driver.execute()。
对于Driver.comile()来说,其实就是调用parse和optimizer包中的相关模块,执行语法解析、语义分析、优化(回想一下大学时的编译原理,编译的过程是不是语法分析、语法解析、语义分析);
对于Driver.run()来说,其实就是调用exec包中的相关模块,将解析后的执行计划执行,如果解析后的结果是一个查询计划,那么通常的作法就是提交一系列的MapReduce作业。
对于
Hive Driver源码执行流程分析
推荐博文
https://segmentfault.com/a/1190000002774731
hive其实做的就是解析一条sql然后形成到mapreduce任务,就是一个代码解释器。hive源代码本身就可以分为ql/metasotre/service/serde 这几块;其中
对于Hive来说,ql是整个Hive最最核心的一个模块,Hive主要的功能都集中在这样一个模块中,即org.apache.hadoop.hive.ql.*,其中最重要的几个模块:
parser:语法解析器和语义分析器,将SQL转化为执行计划。
optimizer:优化器,包括执行计划Operator图的改写(逻辑优化)和Task图的改写(物理优化)。
exec:执行器,作业提交和执行相关。
udf:Hive内置的用户自定义函数,包括操作符加、减、乘、除、与、或、非,常用数学操作(sin、cos等)、字符串操作(substr、instr)、聚合操作(count、sum、avg等)等。
以查询的执行为例,整个Hive的流程是非常简单的一条直线,由上到下进行。

本博文的重心是Hive驱动器之解释器
解析器(parser):将查询字符串转化为解析树表达式。
解释器(parser):分析翻译HQL的组件。
所以,这里是包含两个步骤:第一先是分析,第二再是翻译。
首先来普及下一些概念。
关于antlr的使用
Hive使用的是antlr来做词法、语法的解析工作,最终生成一棵有语义的ast数。
关于antlr
1、ANTLR
是ANother Tool for Language Recognition的缩写“又一个语言识别工具”,读[ 'æntlə ]。从名字上可以看出在ANTLR出现之前已经存在其它语言识别工具了(如LEX1,GCC ,YACC2 )。Antlr通过自己的语法来定义此法规则和语法规则,然后将这些语法规则生成相应的Java/C++代码,分别是一个EELexer.java(词法解析器)和EEParser.java(语法解析器),其中EE是EE.g文件的文件名,这两个文件可以直接拿来使用,具体的demo如下 。
2、Antlr的词法规则
词法是一些正则表达式的东东,可以根据规则将一篇文章切分成一个个的“单词”,又叫token,such as :
Identifier : ('a'..'z' | 'A'..'Z' | '_') ('a'..'z' | 'A'..'Z' | '_' | '0'..'9')*;
STRING : '\'' (~'\'')* '\'';
INT : '0'..'9'+;
WS : ( ' ' | '\t' | '\r' | '\n' )+ { Skip(); } ;
其中WS也是一个词法规则,但是会被过滤掉,可以看作是词之间的分隔符 。
词法规则使用大写来表示,一般写在antlr **.g文件的末尾 。
3、Antlr的语法规则
语法规则是将一系列词法规则组合起来用的,语法规则可以嵌套语法规则,但是有个最顶层的语法规则,最终对于输入要生成这个语法规则,不然会报错 。
语法树重写:
insertStatement : insertClause selectClause fromClause whereClause?
-> ^(INSERT_STATEMENT insertClause selectClause fromClause whereClause?);
这种叫做语法重写,是根据相应的识别相应的语法规则,然后重写这个规则的语法树,主要是为了使得结果的语法树更清晰 。
^(*)表示需要有根节点、叶子节点的语法树,如果不加这个标志的,则解析后的每个token都是一个叶子节点。
其中的第一个token是这棵树的根节点 。
Hive中整词法语法解析(未用antlr的)的步骤
整个sql语句编译、执行的步骤,执行的入口方法是在Driver.run(String command)方法中,执行的参数也就是一个sql字符串 ,主要的方法是:
int ret = compile(command); //编译,主要是将sql字符串翻译成ast树,然后翻译成可执行的task树 ,然后再优化执行树。
ret = execute(); //执行所有的task
1 ) Hive中调用antlr类的代org.apache.hadoop.hive.ql.parse.ParseDriver类返回的HiveParser.statement_return和上面一样,是棵ast的语法树,具体语法树的接口可以参见相应的HiveParse.g文件 。
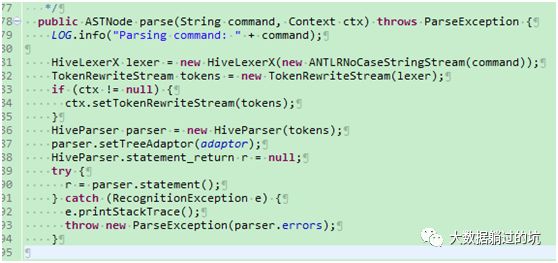
即词法分析,生成AST树,ParseDriver完成。
2 ) 得到语法树之后,会根据语法树根节点的类型来选择相应的SemanticAnalyzer。

主要是根据根节点的语法树类型来选择相应的analyzer,具体的选择analyzer代码如下:
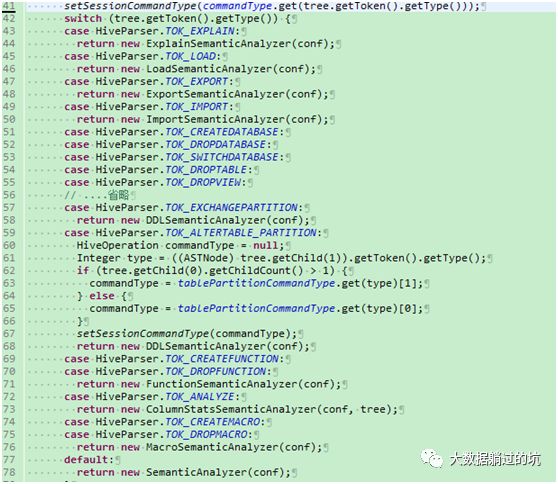
对于DDL操所,得到的就是DDLSemanticAnalyzer ,对于一般的insert(hive中存select语句会被翻译成一个insert tmpDirectory的语句)得到的就是SemanticAnalyzer 。
3 ) 然后调用SemanticAnalyzer.analyze(tree,ctx)来将语法树翻译成可执行的执行计划。
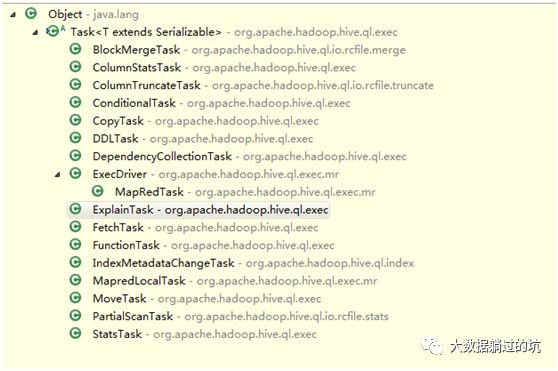
可执行的计划存储在 protected List<Task<? extends Serializable>> rootTasks 属性中,Task的executeTask()方法是可以直接执行的,最终实际的执行也是调用每个task的executeTask方法,依赖以及调度是在上层控制的,Task的继承关系如下:
Task是一个树形结构,每个task有一堆child task ,这些child是在执行顺序上依赖于自己的task ,rootTasks中存储的就是整个执行计划中需要最开始执行的task list ,一棵”倒着的执行依赖树” 。
下一篇是
见明天的
原创 | 大数据入门基础系列之Hive驱动器Driver之编译器Compiler
同时,大可以关注我的个人博客:
http://www.cnblogs.com/zlslch/ 和 http://www.cnblogs.com/lchzls/
http://www.cnblogs.com/sunnyDream/
以及对应本平台的QQ群:161156071(大数据躺过的坑)

本文版权归(大数据躺过的坑)作者和微信公众平台共有,欢迎转载,但未经作者同意必须保留此段声明,且在文章页面明显位置给出原文链接,否则保留追究法律责任的权利。 如果您认为这篇文章还不错或者有所收获,您可以通过下边的“打赏”功能 打赏我一杯咖啡【物质支持】,也可以点击右下角的【点赞】按钮【精神支持】,因为这两种支持都是我继续写作,分享的最大动力!
看完本文有收获?请转发分享给更多人
关注「大数据躺过的坑」,提升大神技能
觉得不错,请点赞和留言↓↓↓
