




点击上方蓝字关注我们,一起涨姿势!

准备工作
爬取弹幕并生成词云的核心步骤为:
一、获取弹幕
二、生成词云
本案例开发环境为:
操作系统:Windows10
Python版本:3.85
开发环境:jupyterlab 2.2.8
涉及库:re,csv,requests,jieba,wordcloud,imageio
一、获取弹幕
要获取弹幕首先要知道弹幕在哪儿,通过搜索发现研究分析可以发现B站弹幕文件保存在一个地址为:https://api.bilibili.com/x/v1/dm/list.so?oid={视频cid号} 的链接里,那找到视频的cid号就很容易找到对应的弹幕了。
那如何获取视频的oid号呢?我们可以通过Chrome浏览器的开发者工具进行分析。具体步骤为:
1、使用Chrome浏览器访问:https://www.bilibili.com/bangumi/play/ep331056
2、在页面空白处点击查看网页源代码,这个时候就会打开网页源代码,信息很多,通过CTRL+F查找cid,找到第一集的cid号为 “210964832”

3、获得第一集的弹幕链接地址为:
"https://api.bilibili.com/x/v1/dm/list.so?oid=210964832"
得到链接之后就可以进行信息的爬取了,爬取操作的是通过代码让计算机自动获取网络信息,可以是价格,评论,图片,音频等一切信息。
1、导入相关模块
import reimport csvimport requestsimport jiebaimport wordcloudimport imageio
2、使用requests.get()方法获取网页内容,并打印输出查看内容
headers = {"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/85.0.4183.121 Safari/537.36",}r = requests.get("https://api.bilibili.com/x/v1/dm/list.so?oid=210964832", headers=headers)html_text = r.content.decode('utf-8')print(html_text)
输出如下图,但是里面包含了其他的一些内容,需要进一步处理
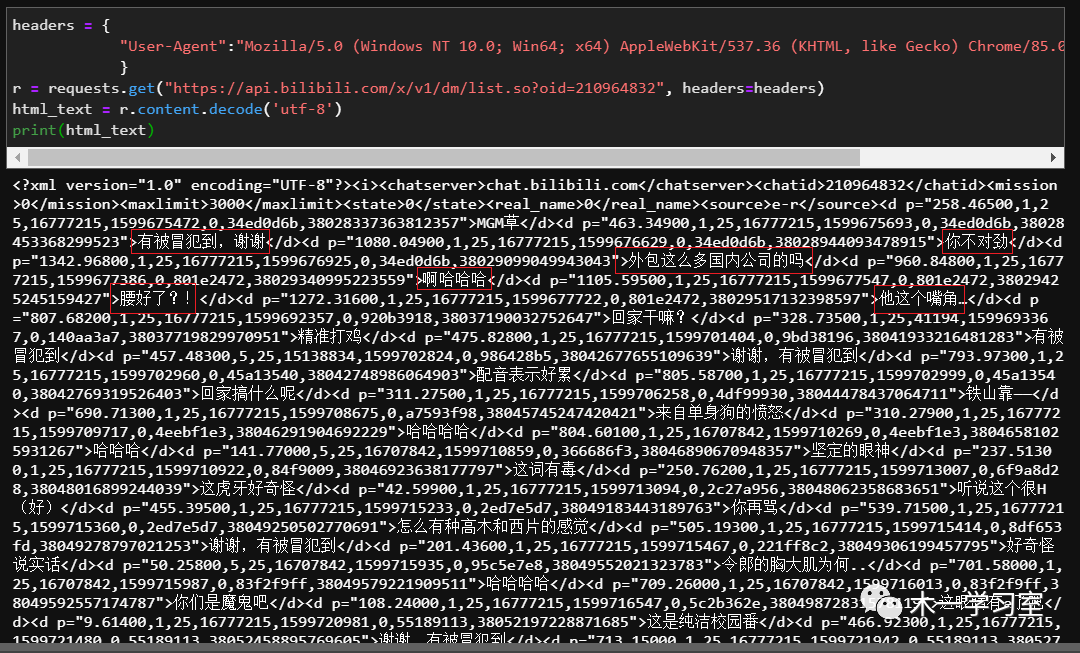
3、使用正则表达式将“<d></d>”之间包含的内容提取出来
DM = re.compile("<d.*?>(.*?)</d>").findall(html_text)print(DM)
输出效果如下,感觉清爽了很多
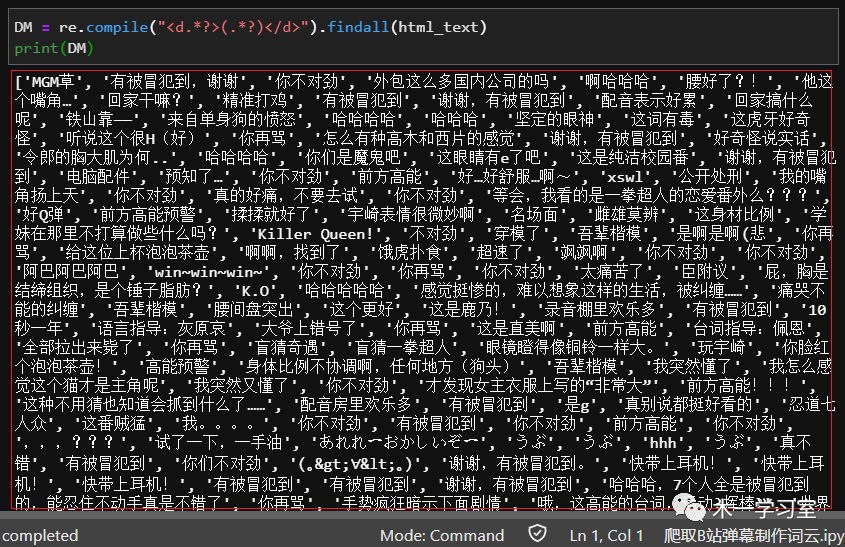
4、为了便于后续操作,我们将获取的代码保存为csv文件,涉及第三方库为csv库,其中使用到了之前学到的for循环进行遍历,代码为:
for i in DM:with open(r'弹幕.csv',"a", newline='',encoding='utf-8-sig') as f:DM = []DM.append(i)writer= csv.writer(f)writer.writerow(DM)
运行完成可以发现当前文件夹下多了一个名为弹幕的csv格式文件,可以用excel打开
查看输出的文件内容跟第3步输出是一致的

接下来开始准备制作词云了。
二、生成词云
我们使用jieba中文分词进行分词操作,将句子转换为词组
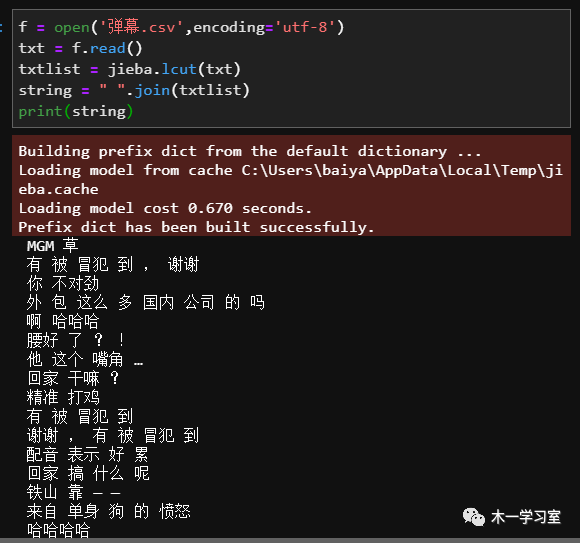
f = open('弹幕.csv',encoding='utf-8')txt = f.read()txtlist = jieba.lcut(txt)string = " ".join(txtlist)print(string)
输出如下图,原本的句子被拆分成了词组
我们使用wordcloud来制作词云,语句为w= wordcloud.WordCloud(<参数>),各参数含义如下:
| 参数 | 描述 |
| width | 指定词云对象生成图片的宽度,默认400像素 |
| height | 指定词云对象生成图片的高度,默认200像素 |
| min_font_size | 指定词云中字体的最小字号,默认4号 |
| max_font_size | 指定词云中字体的最大字号,根据高度自动调节 |
| font_step | 指定词云中字体字号的步进间隔,默认为1 |
| font_path | 指定文体文件的路径,默认None |
| max_words | 指定词云显示的最大单词数量,默认200 |
| stop_words | 指定词云的排除词列表,即不显示的单词列表 |
| mask | 指定词云形状,默认为长方形,需要引用imread()函数 |
| background_color | 指定词云图片的背景颜色,默认为黑色 |
mk = imageio.imread("YUQI.png")w = wordcloud.WordCloud(width=800,height=600,background_color='white',font_path='msyh.ttc',mask=mk,scale=15,stopwords={' '},contour_width=5,contour_color='red')
然后使用w.generate(string)将上一步的分词结果输入词云,最后使用w.to_file('弹幕_词云.png')输出词云到“弹幕_词云.png”文件
终输出效果为:

我们可以看出,“不对劲”,“谢谢“,”冒犯”,“吾辈楷模”成为出现频次最高的弹幕,为什么会这样呢?你去看看就知道了鸭

好了,本期案例实践就这么多,有一些是我们之前讲过的内容,暂时没讲到的将会在后面讲到,希望对你有所帮助。
- End -

扫码二维码
获取更多精彩
木一学习室




如果喜欢,欢迎分享-点赞-在看
