




首先,B树是一种平衡的多路查找树,相较于二叉树结构更加扁平;B+树是应文件系统而生的一种B树的变形。在B树中,每一个元素在该树中只出现一次,有可能在叶子节点上,也有可能在分支节点上。而在B+树中,出现在分支节点上的元素会被当成它们在分支节点位置的中序后继者中再次被列出。叶子节点包含所有元素的信息,且依照元素的大小自小而大顺序链接,所有分支节点可以堪称是索引。B+树的结构特别适合带有范围的查找,比如查找一个学校18-22岁的学生,可以从根节点出发找到第一个18岁的学生,然后在叶子节点按照顺序查找到符合范围的所有记录,但是B树因为其分支结点同样存储着数据,我们要找到具体的数据,需要进行一次中序遍历按序来扫。而且B+树的查找效率更加稳定,非叶子节点并不是表示最终元素信息的节点,只是叶子节点中元素的索引,所以对于任意元素的查找都是从根节点出发到叶子节点,查询轮径的长度相当,查询效率也就更加稳定。
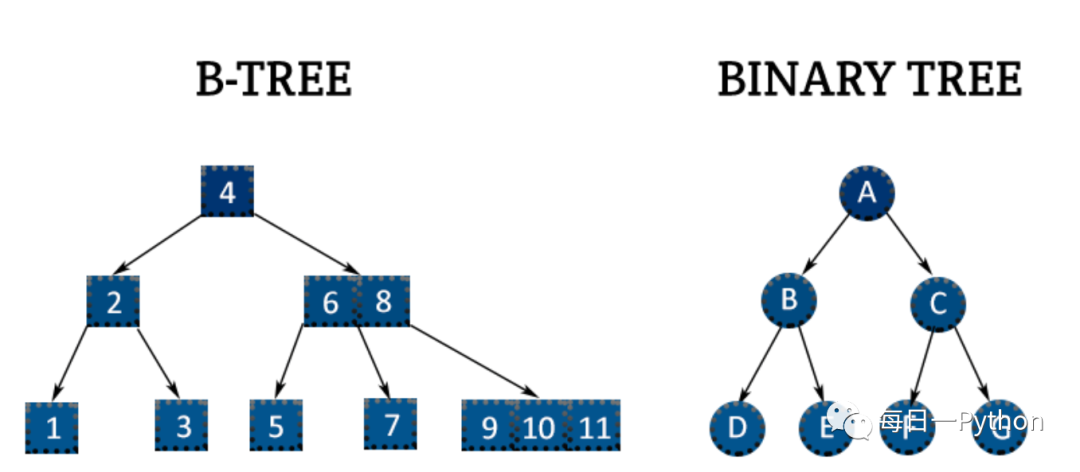
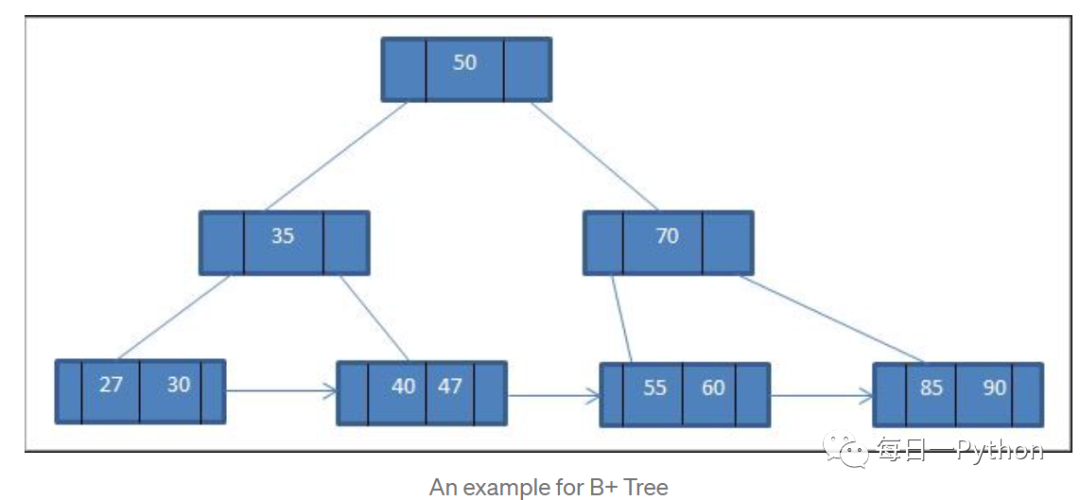
另外,文件一般很大不能全部存储在内存中,需要存到磁盘上,所以索引的组织结构要尽量减少查找过程中磁盘I/O的存取次数。为了减少磁盘I/O操作,操作系统利用了磁盘预读原理,当访问一个地址数据的时候,与其相邻的位置的数据也会被访问到,每次磁盘IO读取的数据我们称之为一页(page)。有了磁盘IO预读机制后,通过一次磁盘IO操作,可以查找到物理存储中相邻的一大片数据。如果查询的索引数据都集中在这个相邻的一片数据中,通过一次IO就可以得到要查找的数据。调整B树的节点元素个数于磁盘存储的页面大小相匹配,例如一个1001阶的B树(节点保存1000),高度为2就可以储存超过10亿个关键词,只需要将将这棵树的根节点持久的保留在内存中,寻找某一个关键词至多需要两次硬盘的读取就可以了。
总之,相较于二叉树,B/B+树可以利用磁盘IO预读机制来减少查找过程中磁盘IO的存取次数,而B+树相较于B树更加适合范围查找,查找效率也更加稳定。
