文章大概翻译自https://www.machinelearningplus.com/plots/top-50-matplotlib-visualizations-the-master-plots-python,主要是在数据分析和数据可视化过程中非最有用的matplotlib 图的top 50示例的总结。这个列表让你利用matplotlib和seaborn选择在什么样的情形下选择什么样的可视化。
根据可视化目标的7种不同的目的将这些图标分类。例如,如果你想画出两个变量之间的关系,就在“correlation”部分中查看;如果你想显示随着值是怎样随着时间的变化而变化,可以在“change”部分中查看。
7个图表类包括“correlation(关联)”、“Deviation(偏差)”、"Ranking(排位)"、“Distribution(分布)”、"Composition(组成)"、“change(变化)”和“Group(群):
correlation包括scatter plot 散点图、bubble plot with encircling带边界的冒泡图、scatter plot with line of best fit 带线性最佳拟合线的散点图、jittering with stripplot抖动图、counts plot 计数图、marginal histogram 边缘直方图、marginal boxplot 边缘箱线图、correlogram 相关图和pairwise plot 成对图;
散点图:散点图是研究两个变量之间关系的经典基础图。如果数据中有多个组,而且你想用不同的颜色展示每个组,在matplotlib中可以很方便的利用plt.scatterplot()实现。
带边界的冒泡图:在边界内显示一组图来显示某组数据的重要性。
带线性最佳拟合线的散点图:如果你想理解两个变量之间是如何相对变化的,一个方法是做最佳拟合线。
抖动图:经常会出现多个点有相同的x和y值。结果就是多个点相互绘制并隐藏。为了避免这种情况,稍微地抖动一下点,以便在视觉上可以看到它们。利用snsborn中的stripplot()可以很容易地做到。
计数图:另一个避免点堆叠的方法是根据在那个位置的点的数量来增加点的尺寸。因此,这个点越大,点的浓度越大。
边缘直方图:边缘直方图沿着x轴和y轴变量有一个直方图,用来可视化x和y之间的关系以及x和y各自的单变量分布。这种图在数据探索(EDA)中经常被用到。
边缘箱线图:边缘箱线图和边缘直方图的目的相似。但是,箱线图有助于确定x和y的中位数、四分之一位数和四分之三位数。
相关图:相关图可以直观地看到在所给的dataframe或2D array中所有可能的成对的数值型变量的相关性矩阵。
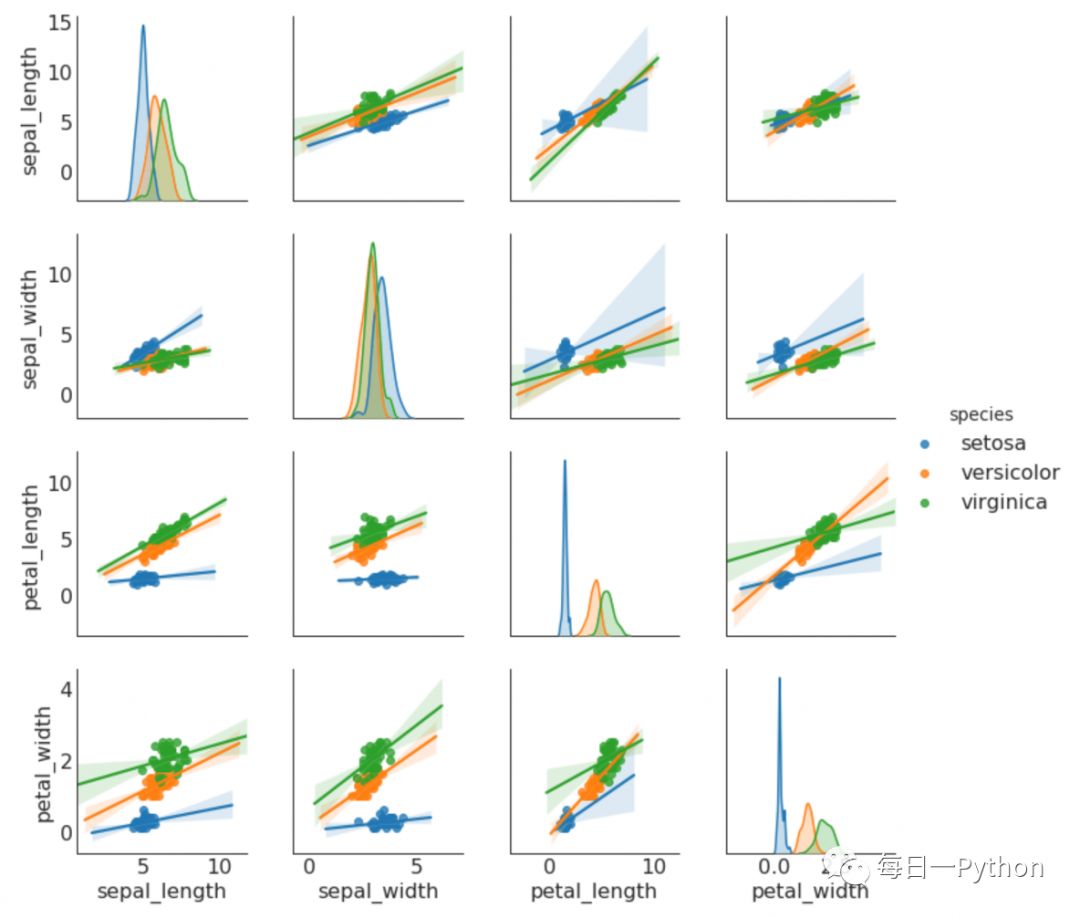
成对图:成对图在数据探索过程中最常用,用来理解数值变量中所有可能的成对的变量之间的关系,是双变量分析的必备工具:
贴一个成对图的代码:
# Load Data
setdf = sns.load_dataset('iris')
# Plot
plt.figure(figsize=(10,8), dpi= 80)
sns.pairplot(df, kind="scatter", hue="species",
plot_kws=dict(s=80, edgecolor="white", linewidth=2.5))
plt.show()
偏差包含diverging bars 发散型直方图、diverging texts 发散型文本、diverging dot plot 发散型点图、diverging lollipop chart with markers带标记的发散型棒棒糖图和area chart 面积图。
发散型直方图:如果你想看一下项目是怎样随着单个指标变化,并可视化此变化的顺序和数量,那么发散型直方图是一个很好的工具。它有助于快速区分数组中群组的性能,非常直观和快速地传达重点。
发散型文本:和发散型直方图类似,不过如果是想以一种漂亮和可展示性的图表来展示每一条目的值,使用它比较好。
发散型点图:也和发散型直方图类似,不过因为矩形条的缺失减少了各个组间的数量上的对比和差异。
带标记的发散型棒棒糖图:带标记的棒棒糖图通过强调任何你想要注意的重要数据点,并在图表中进行适当的推理,提供了一种灵活的方式来可视化这种分歧。
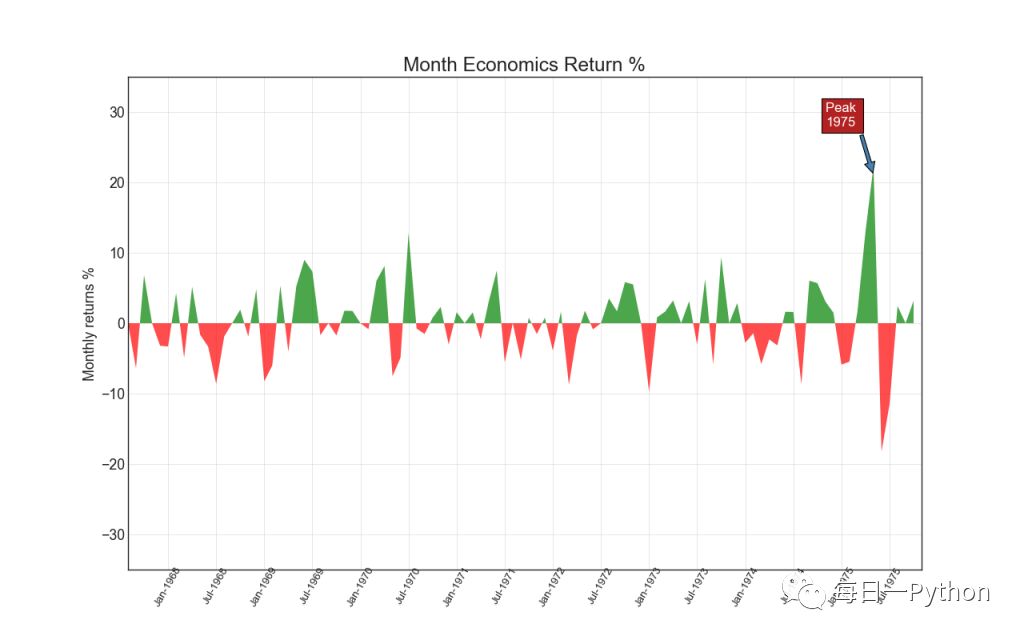
面积图:通过对轴和线之间的区域进行着色,区域图不仅强调峰值和低谷,而且还强调高值和低值持续的时间。高值持续的时间越长,线以下的面积越大。
贴一个面积图的代码:
import numpy as np
import pandas as pd
# Prepare Data
df = pd.read_csv("https://github.com/selva86/datasets/raw/master/economics.csv", parse_dates=['date']).head(100)
x = np.arange(df.shape[0])
y_returns = (df.psavert.diff().fillna(0)/df.psavert.shift(1)).fillna(0) * 100
# Plot
plt.figure(figsize=(16,10), dpi= 80)
plt.fill_between(x[1:], y_returns[1:], 0, where=y_returns[1:] >= 0, facecolor='green', interpolate=True, alpha=0.7)
plt.fill_between(x[1:], y_returns[1:], 0, where=y_returns[1:] <= 0, facecolor='red', interpolate=True, alpha=0.7)
# Annotate
plt.annotate('Peak \n1975', xy=(94.0, 21.0), xytext=(88.0, 28),
bbox=dict(boxstyle='square', fc='firebrick'),
arrowprops=dict(facecolor='steelblue', shrink=0.05), fontsize=15, color='white')
# Decorations
xtickvals = [str(m)[:3].upper()+"-"+str(y) for y,m in zip(df.date.dt.year, df.date.dt.month_name())]
plt.gca().set_xticks(x[::6])
plt.gca().set_xticklabels(xtickvals[::6], rotation=90, fontdict={'horizontalalignment': 'center', 'verticalalignment': 'center_baseline'})
plt.ylim(-35,35)
plt.xlim(1,100)
plt.title("Month Economics Return %", fontsize=22)
plt.ylabel('Monthly returns %')
plt.grid(alpha=0.5)
plt.show()