




很多时候需要对一篇文章统计其中多次出现词语,进而分析文章的内容,这就需要用到词频统计。词频统计就是累加问题,即对文档中每个词设置一个计数器,词语每出现一次,相关计数器就加一次。
def gettext(): text = open('ceshi.txt','r').read() text = text.lower() for ch in '!''#*()+-:;,?></@[\\]^_’{|}~': text =text.replace(ch," ") return text text = gettext() words = text.split() counts={} for word in words: counts[word] = counts.get(word,0)+1 items = list(counts.items()) items.sort(key=lambda x:x[1],reverse=True) for i in range(10): word,count=items[i] print("{0:10} {1:>5}".format(word,count))
结果如下:
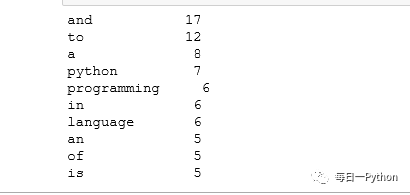
文章转载自每日一Python,如果涉嫌侵权,请发送邮件至:contact@modb.pro进行举报,并提供相关证据,一经查实,墨天轮将立刻删除相关内容。
