




学习目标
学习openGauss存储模型
- 行存和列存
行存储是指将表按行存储到硬盘分区上,列存储是指将表按列存储到硬盘分区上。默认情况下,创建的表为行存储。
行、列存储模型各有优劣,通常用于TP场景的数据库,默认使用行存储,仅对执行复杂查询且数据量大的AP场景时,才使用列存储
课程学习
连接数据库
#第一次进入等待15秒
#数据库启动中...
su - omm
gsql -r
- 创建行存表
CREATE TABLE test_t1
(
col1 CHAR(2),
col2 VARCHAR2(40),
col3 NUMBER
);
- 压缩属性为no
\d+ test_t1
insert into test_t1 select col1, col2, col3 from (select generate_series(1, 100000) as key, repeat(chr(int4(random() * 26) + 65), 2) as col1, repeat(chr(int4(random() * 26) + 65), 30) as col2, (random() * (10^4))::integer as col3);
- 创建列存表
CREATE TABLE test_t2
(
col1 CHAR(2),
col2 VARCHAR2(40),
col3 NUMBER
)
WITH (ORIENTATION = COLUMN);
- 压缩属性为low
\d+ test_t2;
- 插入和行存表相同的数据
insert into test_t2 select * from test_t1;
- 占用空间对比
\d+
- 对比读取一列的速度
analyze VERBOSE test_t1;
analyze VERBOSE test_t2;
- 列存表时间少于行存表
explain analyze select distinct col1 from test_t1;
explain analyze select distinct col1 from test_t2;
- 对比插入一行的速度
- 行存表时间少于列存表
explain analyze insert into test_t1 values('x', 'xxxx', '123');
explain analyze insert into test_t2 values('x', 'xxxx', '123');
- 清理数据
drop table test_t1;
drop table test_t2;
课程作业
- 创建行存表和列存表,并批量插入10万条数据(行存表和列存表数据相同)
需要自己建表!! - 对比行存表和列存表空间大小
- 对比查询一列和插入一行的速度
- 清理数据
-- 1.1.
create table tbl_1
(
col1 char(2),
col2 varchar2(40),
col3 number
);
insert into tbl_1 select col1, col2, col3 from (select generate_series(1, 100000) as key, repeat(chr(int4(random() * 26) + 65), 2) as col1, repeat(chr(int4(random() * 26) + 65), 30) as col2, (random() * (10^4))::integer as col3);
-- 1.2.
create table tbl_2
(
col1 char(2),
col2 varchar2(40),
col3 number
)
with (orientation = column);
insert into tbl_2 select * from tbl_1;
-- 2.
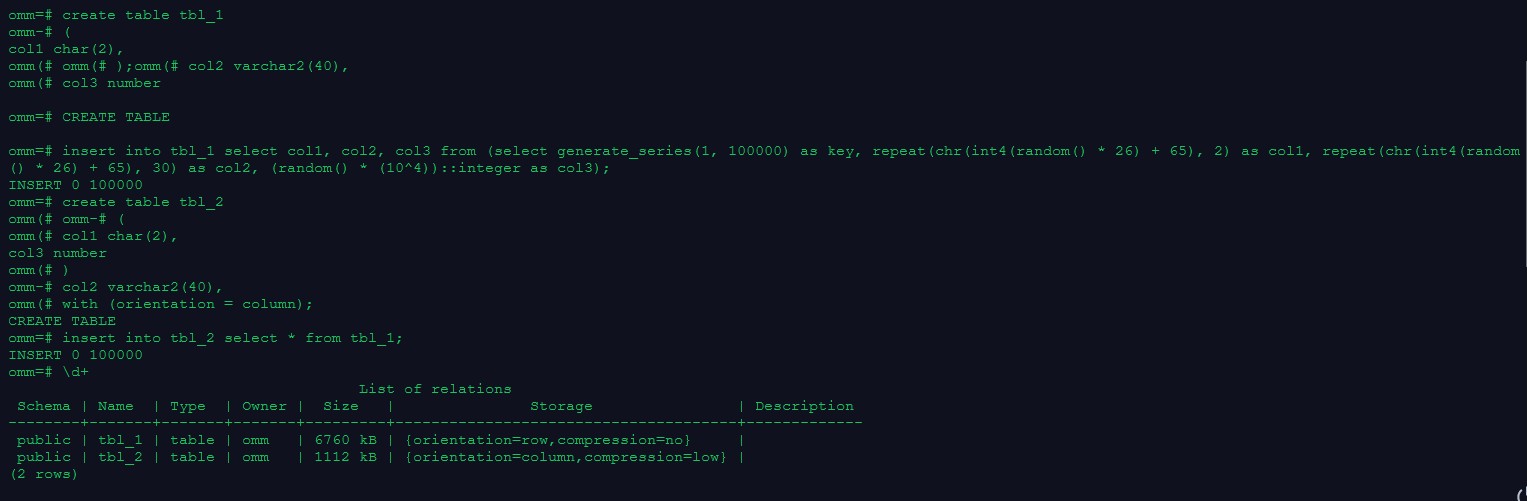
\d+
omm=# \d+
List of relations
Schema | Name | Type | Owner | Size | Storage
| Description
--------+-------+-------+-------+---------+-------------------------------------
-+-------------
public | tbl_1 | table | omm | 6760 kB | {orientation=row,compression=no} |
public | tbl_2 | table | omm | 1112 kB | {orientation=column,compression=low} |
(2 rows)
-- 3.
-- select
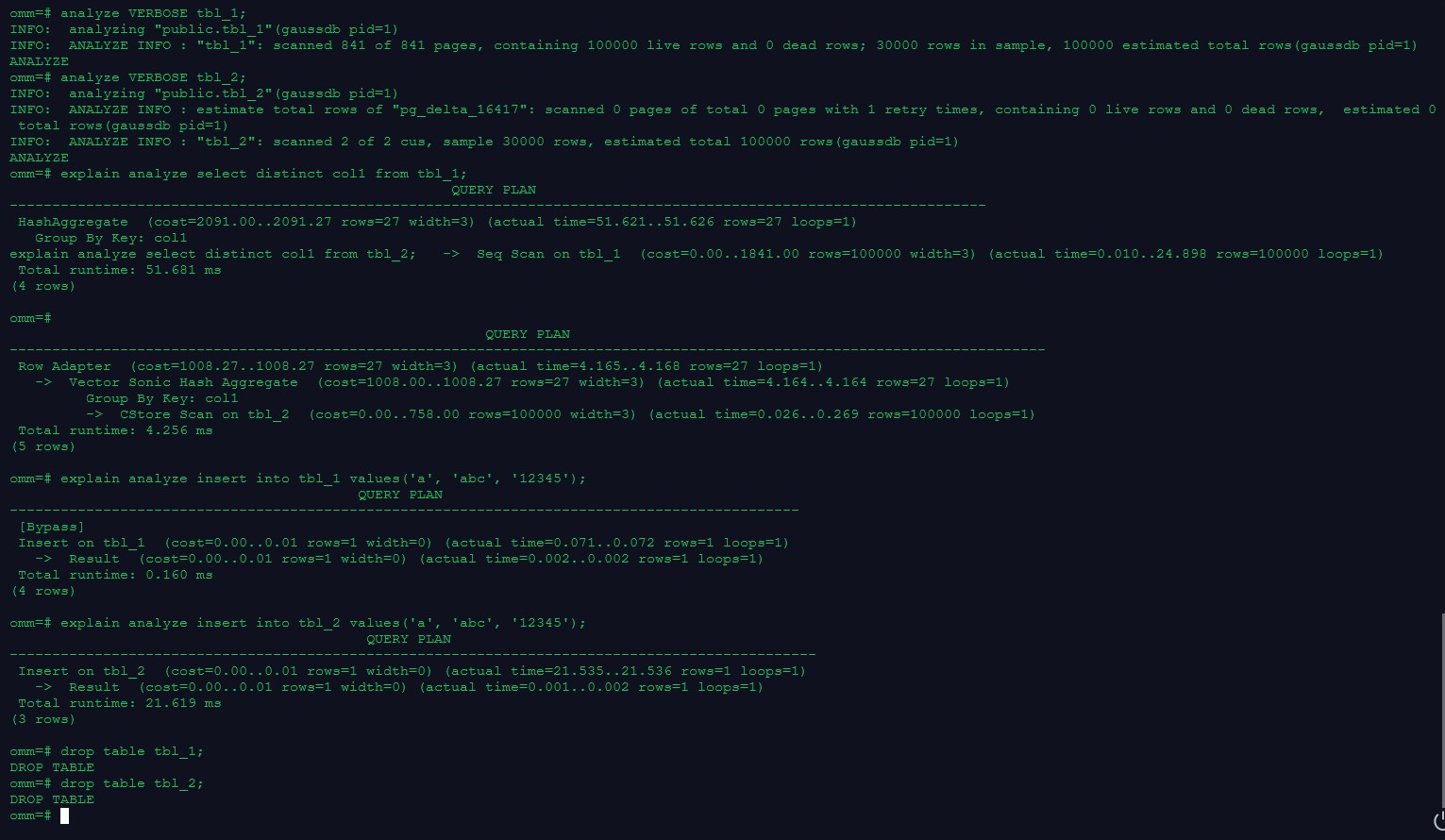
analyze VERBOSE tbl_1;
analyze VERBOSE tbl_2;
explain analyze select distinct col1 from tbl_1;
explain analyze select distinct col1 from tbl_2;
omm=# analyze VERBOSE tbl_1;
INFO: analyzing "public.tbl_1"(gaussdb pid=1)
INFO: ANALYZE INFO : "tbl_1": scanned 841 of 841 pages, containing 100000 live rows and 0 dead rows; 30000 rows in sample, 100000 estimated total rows(gaussdb pid=1)
ANALYZE
omm=# analyze VERBOSE tbl_2;
INFO: analyzing "public.tbl_2"(gaussdb pid=1)
INFO: ANALYZE INFO : estimate total rows of "pg_delta_16417": scanned 0 pages of total 0 pages with 1 retry times, containing 0 live rows and 0 dead rows, estimated 0 total rows(gaussdb pid=1)
INFO: ANALYZE INFO : "tbl_2": scanned 2 of 2 cus, sample 30000 rows, estimated total 100000 rows(gaussdb pid=1)
ANALYZE
omm=#
omm=# explain analyze select distinct col1 from tbl_1;
QUERY PLAN
--------------------------------------------------------------------------------
-----------------------------------
HashAggregate (cost=2091.00..2091.27 rows=27 width=3) (actual time=46.958..46.961 rows=27 loops=1)
Group By Key: col1
-> Seq Scan on tbl_1 (cost=0.00..1841.00 rows=100000 width=3) (actual time=0.010..21.116 rows=100000 loops=1)
Total runtime: 47.018 ms
(4 rows)
omm=#
omm=# explain analyze select distinct col1 from tbl_2;
QUERY PLAN
--------------------------------------------------------------------------------
------------------------------------------
Row Adapter (cost=1008.27..1008.27 rows=27 width=3) (actual time=10.205..10.20
8 rows=27 loops=1)
-> Vector Sonic Hash Aggregate (cost=1008.00..1008.27 rows=27 width=3) (actual time=10.201..10.201 rows=27 loops=1)
Group By Key: col1
-> CStore Scan on tbl_2 (cost=0.00..758.00 rows=100000 width=3) (actual time=0.080..0.713 ows=100000 loops=1)
Total runtime: 10.318 ms
(5 rows)
-- insert
explain analyze insert into tbl_1 values('a', 'abc', '12345');
explain analyze insert into tbl_2 values('a', 'abc', '12345');
omm=# explain analyze insert into tbl_1 values('a', 'abc', '12345');
QUERY PLAN
--------------------------------------------------------------------------------
-------------
[Bypass]
Insert on tbl_1 (cost=0.00..0.01 rows=1 width=0) (actual time=0.073..0.074 rows=1 loops=1)
-> Result (cost=0.00..0.01 rows=1 width=0) (actual time=0.001..0.001 rows=1 loops=1)
Total runtime: 0.265 ms
(4 rows)
omm=# explain analyze insert into tbl_2 values('a', 'abc', '12345');
QUERY PLAN
--------------------------------------------------------------------------------
---------------
Insert on tbl_2 (cost=0.00..0.01 rows=1 width=0) (actual time=19.645..19.648 rows=1 loops=1)
-> Result (cost=0.00..0.01 rows=1 width=0) (actual time=0.001..0.002 rows=1 loops=1)
Total runtime: 20.271 ms
(3 rows)
-- 4.
drop table tbl_1;
drop table tbl_2;
学习心得
本节重点知识点:
规划存储模型
行存表
列存表
参考文档
松鼠镇楼,按时打卡

最后修改时间:2022-05-18 09:07:12
「喜欢这篇文章,您的关注和赞赏是给作者最好的鼓励」
关注作者
【版权声明】本文为墨天轮用户原创内容,转载时必须标注文章的来源(墨天轮),文章链接,文章作者等基本信息,否则作者和墨天轮有权追究责任。如果您发现墨天轮中有涉嫌抄袭或者侵权的内容,欢迎发送邮件至:contact@modb.pro进行举报,并提供相关证据,一经查实,墨天轮将立刻删除相关内容。
