今天进入了第二十一天,也就是最后一天的学习了。学习了行存储是指将表按行存储到硬盘分区上,列存储是指将表按列存储到硬盘分区上。默认情况下,创建的表为行存储。行、列存储模型各有优劣,通常用于TP场景的数据库,默认使用行存储,仅对执行复杂查询且数据量大的AP场景时,才使用列存储。
通过这么些天的学习,我掌握了openGauss数据库的理念,基本操作和常见的语法。
以下是我今天的作业打卡情况,请老师批阅:
1.创建行存表和列存表,并批量插入10万条数据(行存表和列存表数据相同)
进入数据库:
su - omm
gsql -r
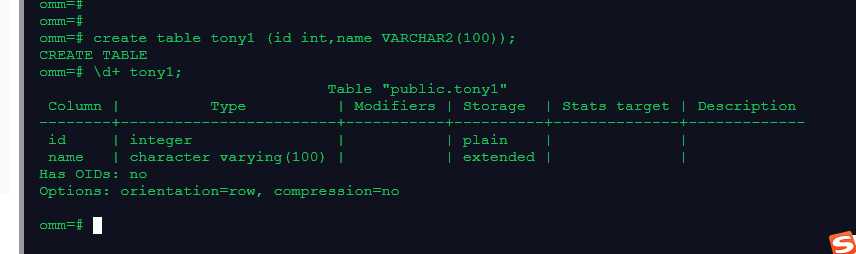
create table tony1 (id int,name VARCHAR2(100)); ---创建行存表
\d+ tony1;
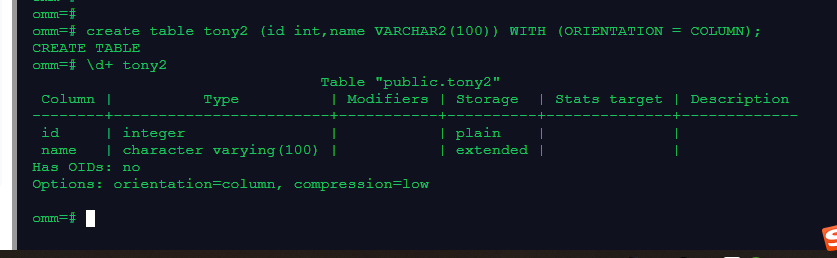
create table tony2 (id int,name VARCHAR2(100)) WITH (ORIENTATION = COLUMN);---创建列存表
\d+ tony2
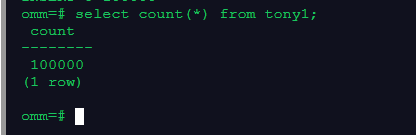
insert into tony1 select id, name from (select generate_series(1, 100000) as id, repeat(chr(int4(random() * 26) + 65), 2) as name);---批量插入10万数据

select count(*) from tony1;
insert into tony2 select * from tony1;
select count(*) from tony2;
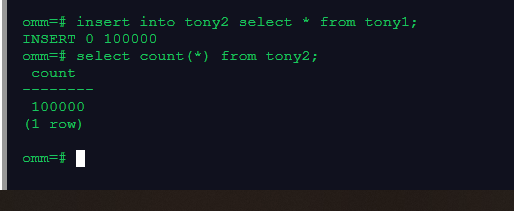
2.对比行存表和列存表空间大小
\d+

3.对比查询一列和插入一行的速度
-- 收集统计信息
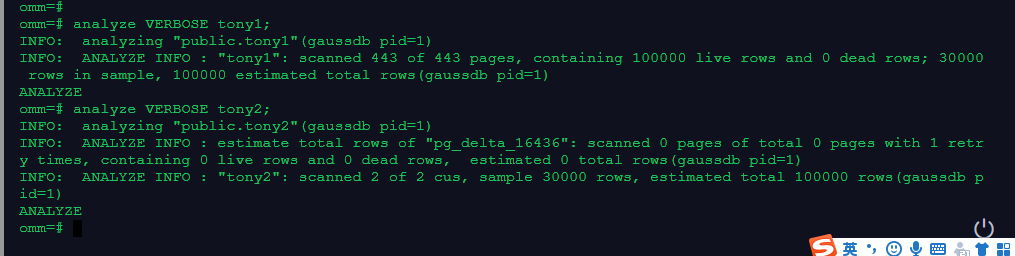
analyze VERBOSE tony1;
analyze VERBOSE tony2;
-- 对比查询一列的速度
explain analyze select distinct id from tony1;
explain analyze select distinct id from tony2;
-- 对比插入一行的速度
explain analyze insert into tony1 values(10000, 'name_tony1');
explain analyze insert into tony2 values(20000, 'name_tony2');
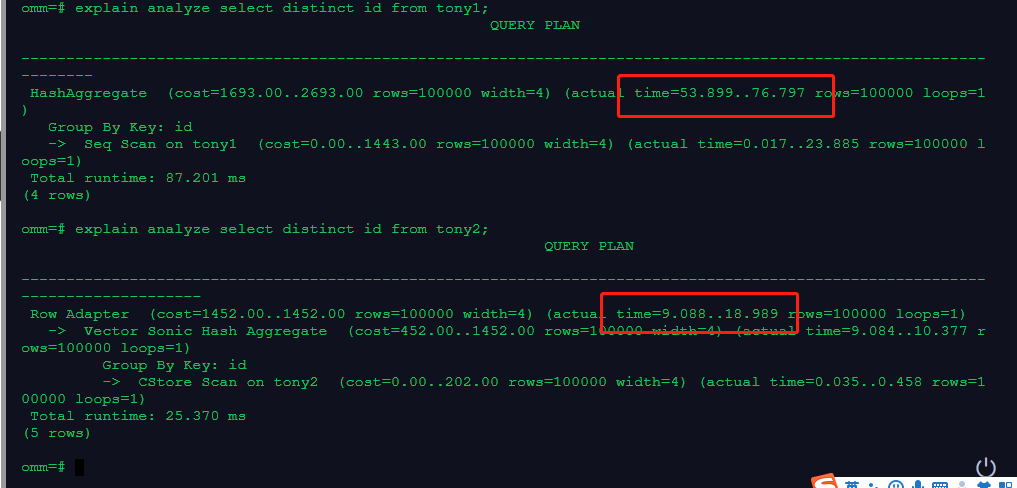
以上截图说明列存查询速度快。
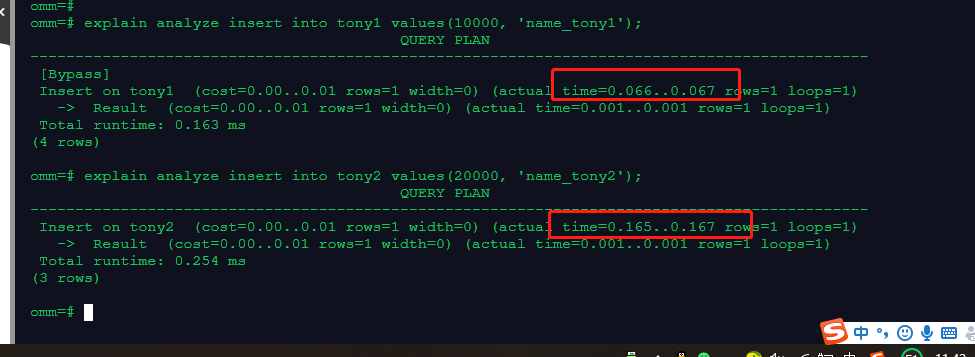
以上截图说明行存表时间少于列存表
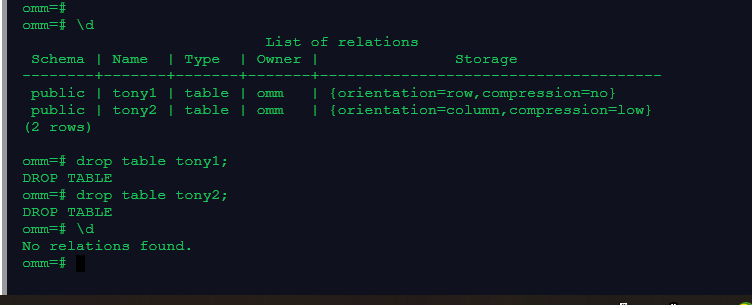
4.清理数据
\d
drop table tony1;
drop table tony2;
\d