




MyRocks是一种经过空间和写性能优化的MySQL数据库,为您业务的数据库选型提供一种靠谱的选择。本文主要介绍什么是MyRocks。
RocksDB是FaceBook基于Google开源的LevelDB实现的,使用LSM(Log-Structure Merge)树来存储数据。Facebook开发工程师对RocksDB进行了大量的开发,使其符合MySQL的插件式存储引擎框架的要求,移植到了MySQL上,并称之为MyRocks。MyRocks支持基于SQL的数据读写、锁机制、MVCC、事务、主从复制等MySQL绝大部分功能特性。从使用习惯考虑,使用MyRocks还是使用MySQL/InnoDB并没有多大区别。

经过4年多的发展,MyRocks已经成熟,开源的MySQL分支版本Percona和MariaDB已将MyRocks迁移到自己的MySQL分支中,InnoSQL作为网易的MySQL分支,目前也已支持MyRocks,具体版本为InnoSQL 5.7.20-v4,在开源的MyRocks代码基础上,我们对其做了功能优化增强、bugfix,并支持对其进行本地和远程在线物理备份。下面先简要介绍MyRocks特性,让大家对其有个基本认识。由于MyRocks只是将InnoDB替换为RocksDB,所以MySQL Server层的逻辑并没有多大变化,包括SQL解析和执行计划,基于Binlog的多线程复制机制等。我们讨论的焦点主要是存储引擎层,也就是RocksDB上。
本文主要包括3个部分:首先是通过RocksDB读写流程来介绍其整体框架、存储后端和功能特性;接着分多维度分析其与InnoDB的不同点,这些差别所带来的的好处;最后分析RocksDB的这些优势能够用在哪些业务场景上。文章较长,大家可以调自己感兴趣的部分食用。
RocksDB读写流程
写流程
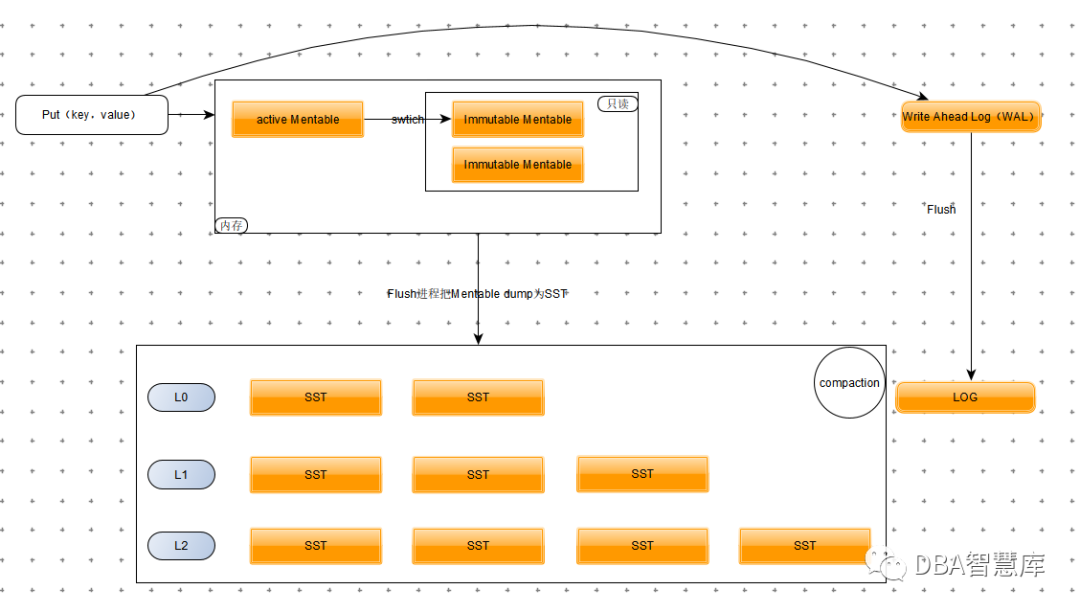
上图所示为RocksDB的写请求示意图,一个事务的修改在提交前先写入事务线程自身的WriteBatch中(在上图示例中事务仅执行一个Put操作,那么WriteBatch中仅有该Put),在提交时被写入RocksDB位于内存中的MemTable中,MemTable本质上是一个SkipList,里面缓存的记录是有序的。和InnoDB一样,事务更改的数据(WriteBatch)在提交前也会先写Write Ahead Log(WAL),事务提交后,只需保证WAL已经持久化即可,MemTable中数据不需要写入磁盘上的数据文件中。当MemTable大小达到阈值后(比如32MB),RocksDB会产生新的MemTable,原来的MemTable会变为只读状态(Immutable),不再接收新的写入操作。Immutable MemTable会被后台的Flush线程dump成一个sst文件。在磁盘上,RocksDB通过一个个sst文件来保存数据,一个个log文件保存WAL日志。在磁盘上,sst文件是分层的,每层多有一到多个sst文件,文件大小基本固定,层级越大,该层的文件数量越多,意味着该层允许的总大小越大,如下图所示。
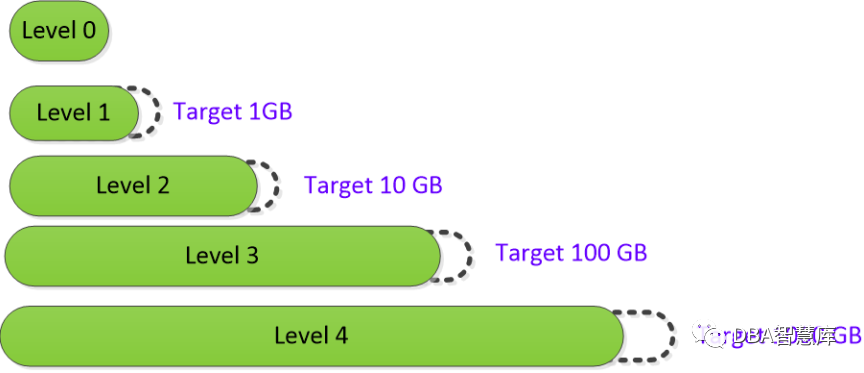
一般情况下,从内存中dump出来的文件放在Level0,Level0层的各个sst文件其保存的记录区间是可能重合的,比如sst1保存了1.4.6.9,sst2保存了5.6.10.20。由于采用LSM树技术存储数据,所以一条记录会有多个版本,比如sst1和sst2都有记录6,只不过sst2中的版本更新。同样的,不同层级间也会存在相同记录的不同版本。跟Level0不同,Level1及更高层级的sst文件,同层的sst文件相互间不会有相同的记录。
Compaction机制
既然存在多个不同的记录版本,那么就需要有个机制进行版本合并,这个机制就是Compaction。
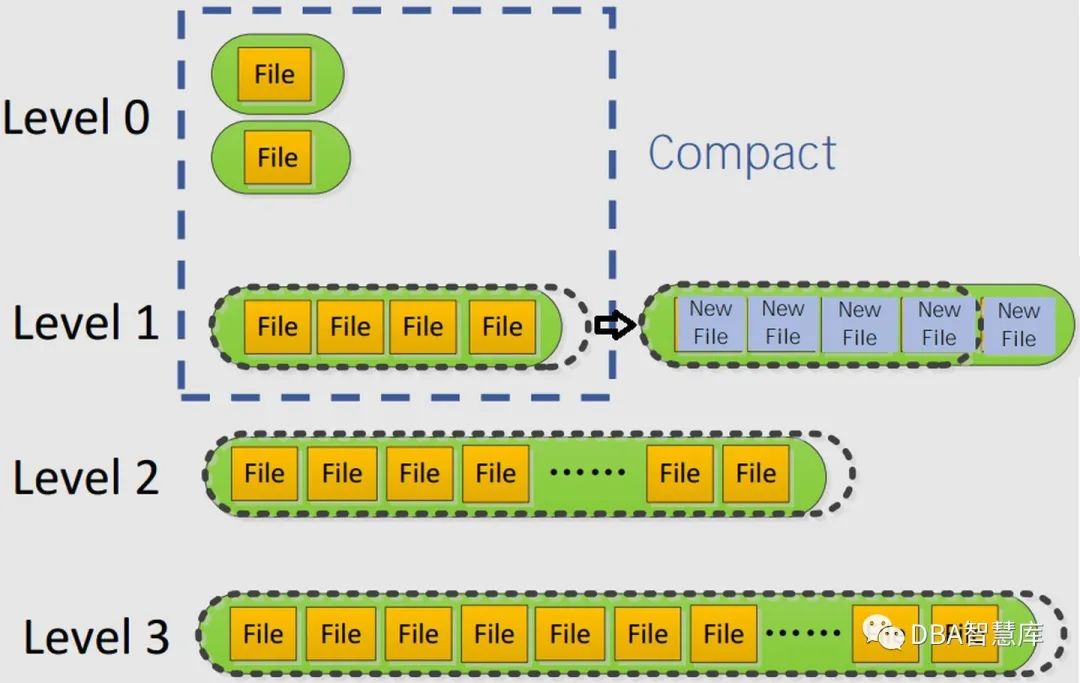
上图就是一个Level0的Compaction,将一到多个Level0的文件跟Level1的文件进行compaction的过程。不管是将内存的MemTable dump到sst文件,还是sst文件之间的Compaction,从IO角度都是顺序读写,这不管在SSD还是HDD上都是有利的,对于HDD可以发挥顺序性能远高于随机性能的特点,对于SSD,可以避免随机写带来的Flash介质写放大效应。
读流程
聊完了RocksDB写流程,我们再来看下跟读相关的组件。如下所示:
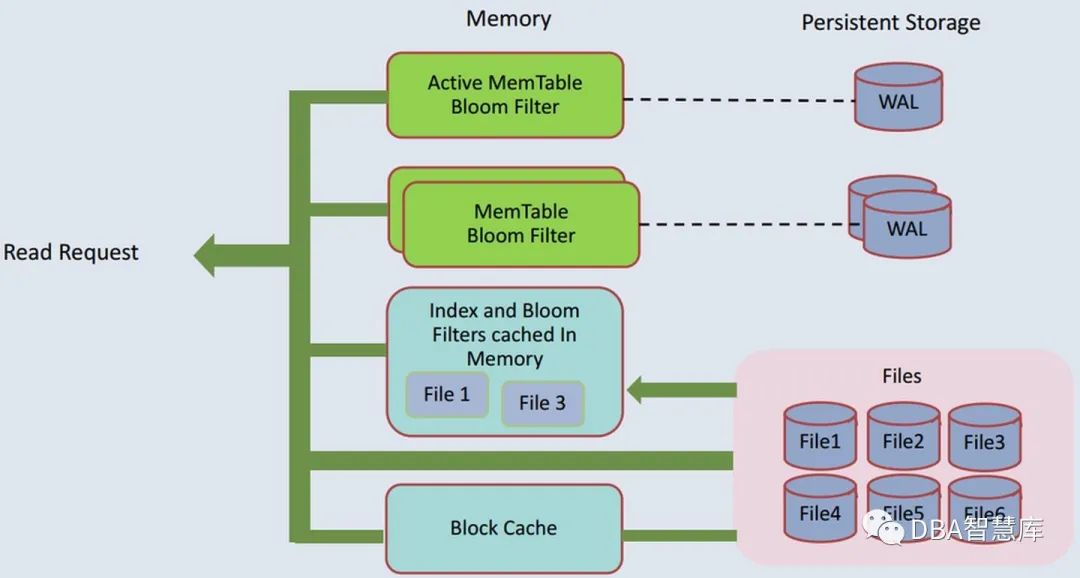
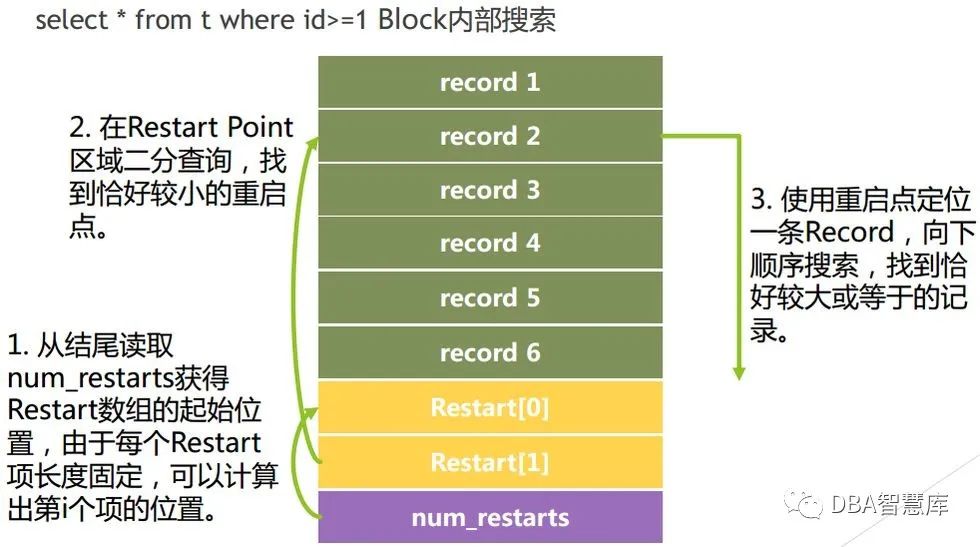
数据库中的读可分为当前读和快照读,所谓当前读,就是读取记录的最新版本数据,而快照读就是读指定版本的数据。在此我们仅讨论当前读,快照读可做类似的分析。由于采用LSM树存储结构,所以RocksDB的读操作跟InnoDB有较大的不同,这是由于LSM可能存在多个记录的版本(且不像InnoDB那样前后版本有指针相连),且无法通过(严格意义上)的二分查找。因此,在RocksDB中引入Bloom Filter(布隆过滤器)来进行读路径优化,在RocksDB中Bloom Filter可以选择三种不同的方式,分别是基于data block的、基于partition的和基于sst文件的,Bloom Filter可以用来判断所需查找的key一定不在某个block/partition/sst中。RocksDB默认基于data block,其粒度最小。
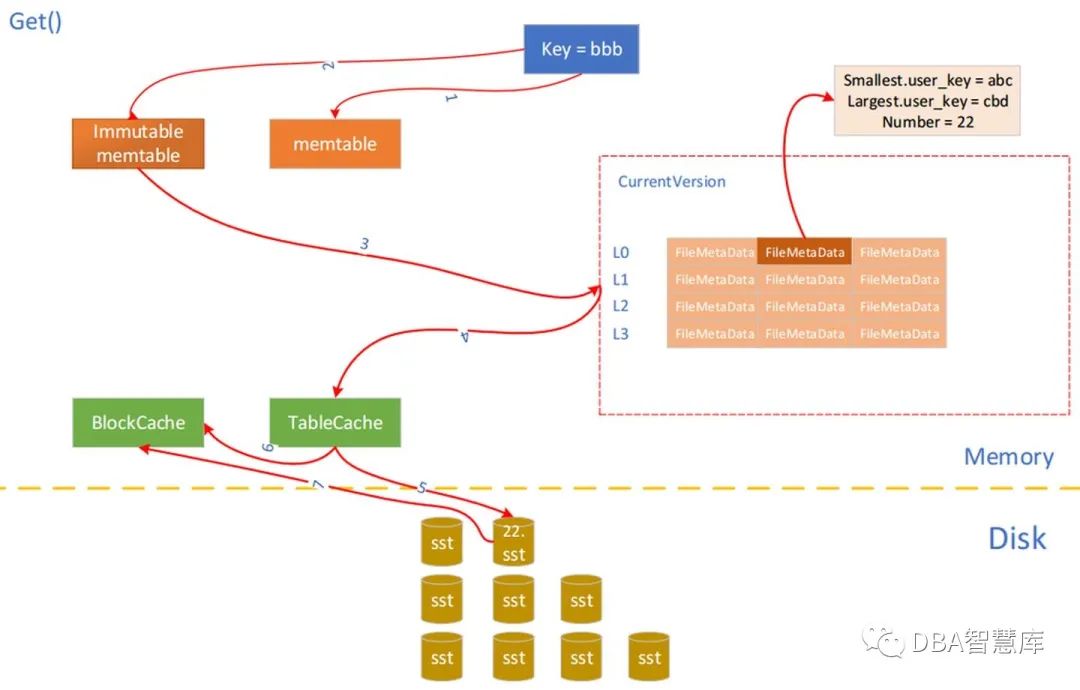
接下来结合上面2张图简要分析RocksDB读流程。一个Get(key=bbb)请求首先在当前MemTable中通过Bloom Filter查找,若未命中,在进一步到只读MemTable,如果还未命中,说明该key-vaule或者在磁盘sst文件中,或者不存在。所以需要搜索每个sst文件的元数据信息,找出所有key区间包含所请求key值的sst文件。并根据层级从小到大进行查询。对于每个sst文件,通过Bloom Filter进一步查找,若命中,则将sst文件中的data block读入BlockCache,通过二分法在block内部进行遍历查找,最后返回对应key或NotFound,如下图所示。
RocksDB列族
在RocksDB中列族(Column Family)就是在逻辑上独立的一棵LSM树,每个列族都有自己独立的MemTable,所有列族共享一份WAL日志。sst文件的Compaction是以列族为粒度进行的。
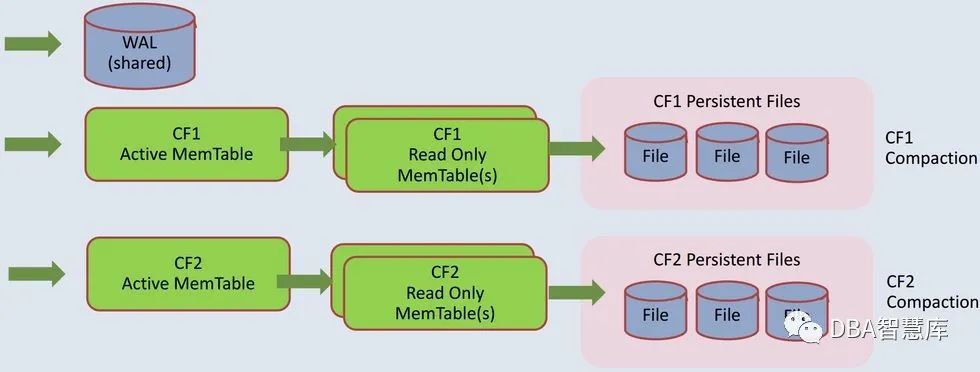
默认情况下一个MyRocks实例包括2个列族,分别为用于存放系统元数据的_system_和用于存放所有用户创建的表数据的default。当然,用户在定义表的时候,可以通过在索引后面加备注(comment)来声明该索引使用的列族名,下面的例子即将rdbtable的主键和唯一索引都放在独立的列族cf_pk和cf_uid上。
CREATE TABLE `rdbtable` (
`id` bigint(11) NOT NULL COMMENT '主键',
`userId` bigint(20) NOT NULL DEFAULT '0' COMMENT '用户ID',
PRIMARY KEY (`id`) COMMENT 'cf_pk',
UNIQUE KEY `uid` (`userId`) COMMENT 'cf_uid',
) ENGINE=ROCKSDB DEFAULT CHARSET=utf8
