




第二十一天学习openGauss存储模型-行存和列存。
连接openGauss
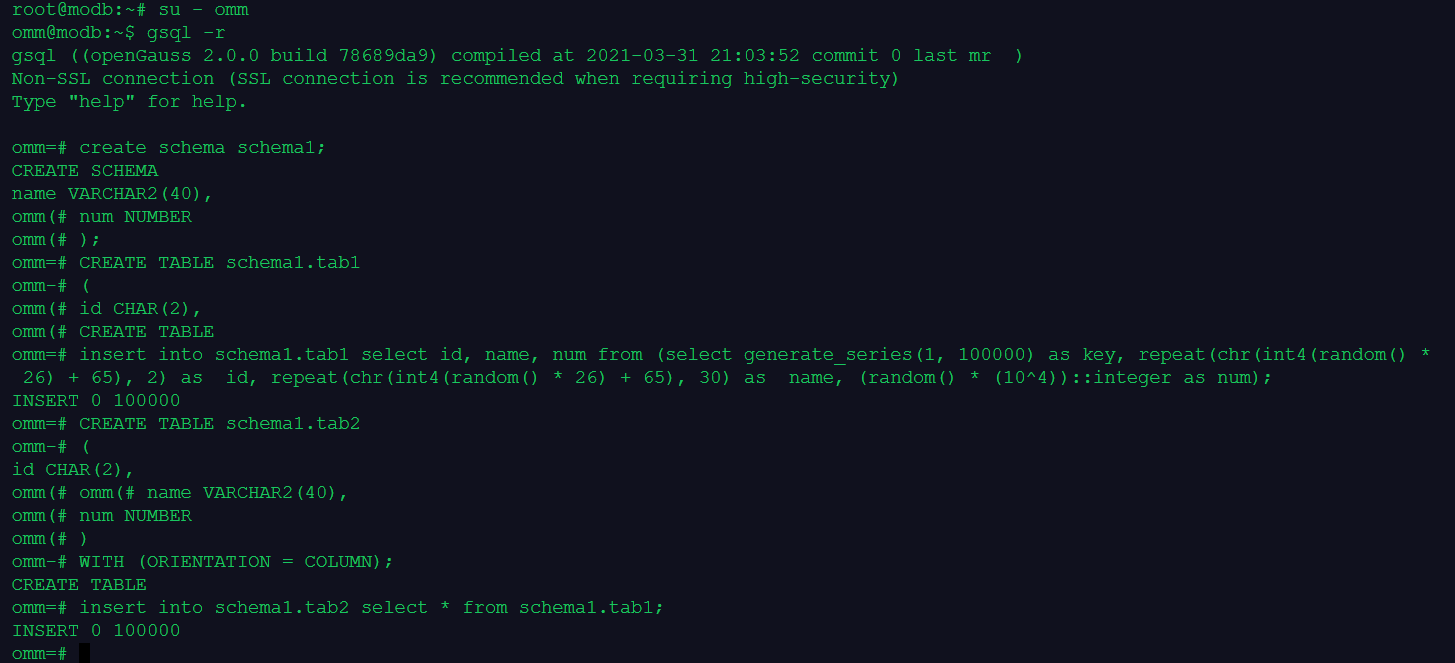
su - omm gsql -r
1.创建行存表和列存表,并批量插入10万条数据(行存表和列存表数据相同)
--创建行存表
create schema schema1;
CREATE TABLE schema1.tab1
(
id CHAR(2),
name VARCHAR2(40),
num NUMBER
);
insert into schema1.tab1 select id, name, num from (select generate_series(1, 100000) as key, repeat(chr(int4(random() * 26) + 65), 2) as id, repeat(chr(int4(random() * 26) + 65), 30) as name, (random() * (10^4))::integer as num);
--创建列存表
CREATE TABLE schema1.tab2
(
id CHAR(2),
name VARCHAR2(40),
num NUMBER
)
WITH (ORIENTATION = COLUMN);
insert into schema1.tab2 select * from schema1.tab1;
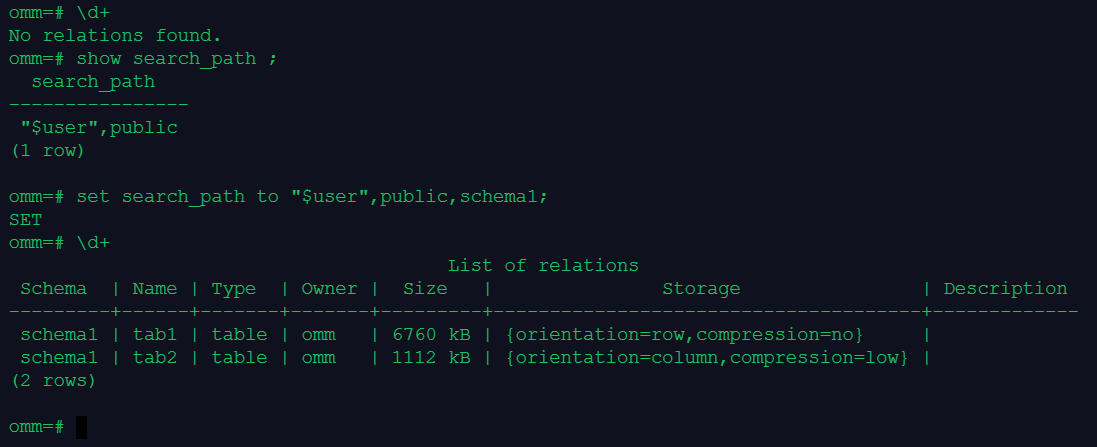
2.对比行存表和列存表空间大小
\d+
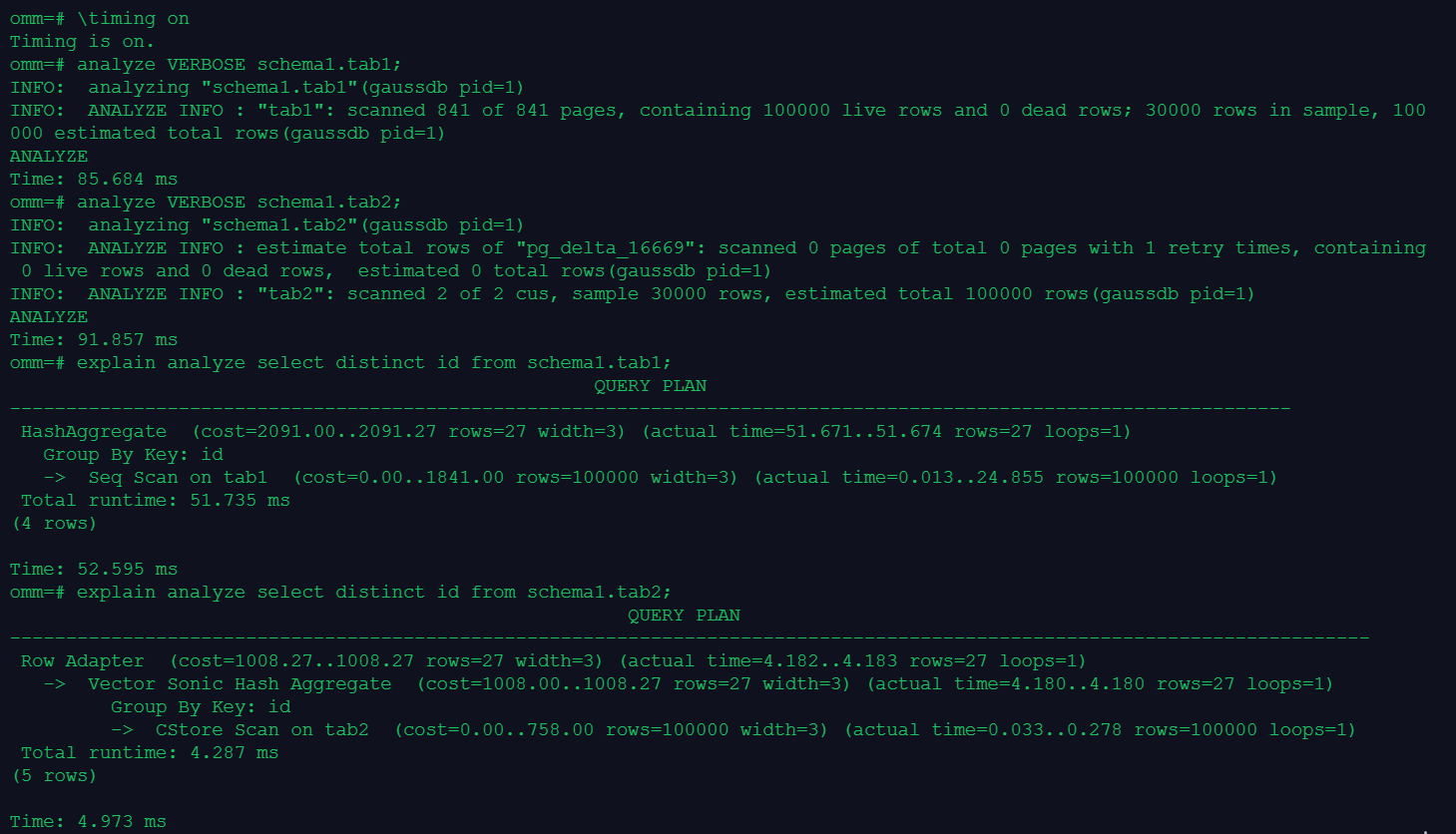
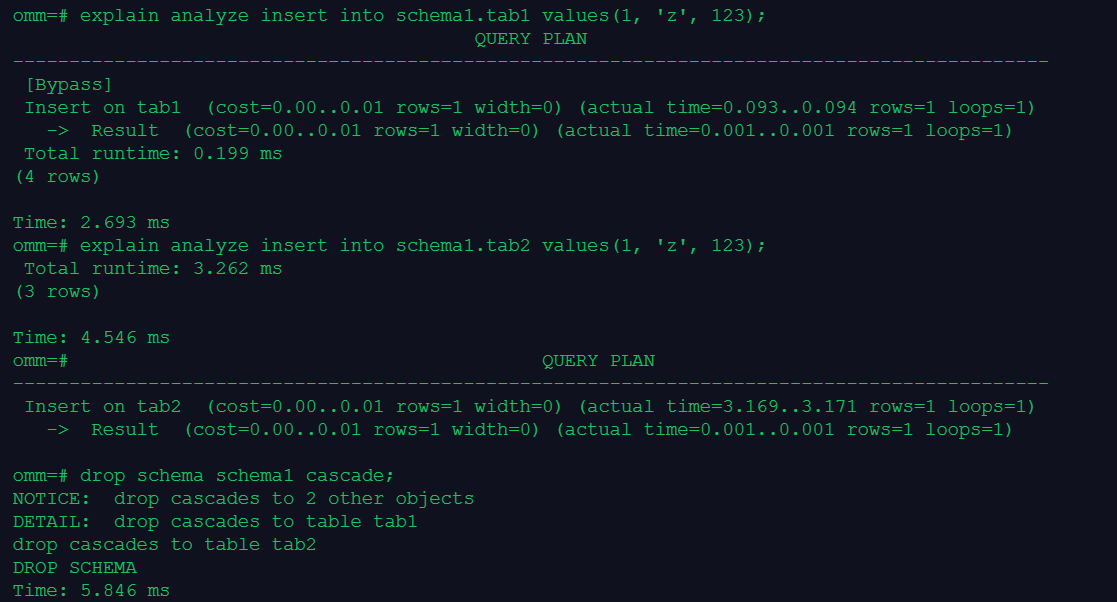
3.对比查询一列和插入一行的速度
\timing on
analyze VERBOSE schema1.tab1;
analyze VERBOSE schema1.tab2;
explain analyze select distinct id from schema1.tab1;
explain analyze select distinct id from schema1.tab2;
explain analyze insert into schema1.tab1 values(1, 'z', 123);
explain analyze insert into schema1.tab2 values(1, 'z', 123);
4.清理数据
drop schema schema1 cascade;
上面实际操作截图如下:
通过以上实操,学习到openGauss存储模型-行存和列存,了解到行存储是指将表按行存储到硬盘分区上,列存储是指将表按列存储到硬盘分区上。默认情况下,创建的表为行存储。行、列存储模型各有优劣,通常用于TP场景的数据库,默认使用行存储,仅对执行复杂查询且数据量大的AP场景时,才使用列存储。
「喜欢这篇文章,您的关注和赞赏是给作者最好的鼓励」
关注作者
【版权声明】本文为墨天轮用户原创内容,转载时必须标注文章的来源(墨天轮),文章链接,文章作者等基本信息,否则作者和墨天轮有权追究责任。如果您发现墨天轮中有涉嫌抄袭或者侵权的内容,欢迎发送邮件至:contact@modb.pro进行举报,并提供相关证据,一经查实,墨天轮将立刻删除相关内容。
