




上几篇文章中我们分析了一个flink wordcount任务生成streamGraph和jobGraph的过程。接下来,我们继续从jobGraph生成后开始来分析executionGraph的生成过程及任务的提交过程,本文主要分析任务提交过程中各组件的执行逻辑,如TaskManager、ResourceManager、JobManager等。本文只涉及到本地运行wordcount时各组件的内部运行逻辑分析,不包括其他资源管理模式如yarn或Kubernetes模式下任务的提交流程(后续会专门行文来分析)。文章较长,代码较多,不喜慎入。
接前几篇文章,分析到了org.apache.flink.client.deployment.executors.LocalExecutor#execute方法:
@Overridepublic CompletableFuture<JobClient> execute(Pipeline pipeline, Configuration configuration, ClassLoader userCodeClassloader) throws Exception {checkNotNull(pipeline);checkNotNull(configuration);// 有效的配置Configuration effectiveConfig = new Configuration();effectiveConfig.addAll(this.configuration);effectiveConfig.addAll(configuration);// we only support attached execution with the local executor.checkState(configuration.getBoolean(DeploymentOptions.ATTACHED));// 获取了jobGraphfinal JobGraph jobGraph = getJobGraph(pipeline, effectiveConfig);return PerJobMiniClusterFactory.createWithFactory(effectiveConfig, miniClusterFactory).submitJob(jobGraph, userCodeClassloader);}
在上面的方法中一方面对配置进行了有效性校验,另一方面生成了jobGraph,然后提交jobGraph。我们来看org.apache.flink.client.program.PerJobMiniClusterFactory#submitJob方法:
public CompletableFuture<JobClient> submitJob(JobGraph jobGraph, ClassLoader userCodeClassloader) throws Exception {MiniClusterConfiguration miniClusterConfig = getMiniClusterConfig(jobGraph.getMaximumParallelism());MiniCluster miniCluster = miniClusterFactory.apply(miniClusterConfig);miniCluster.start();return miniCluster.submitJob(jobGraph).thenApplyAsync(FunctionUtils.uncheckedFunction(submissionResult -> {org.apache.flink.client.ClientUtils.waitUntilJobInitializationFinished(() -> miniCluster.getJobStatus(submissionResult.getJobID()).get(),() -> miniCluster.requestJobResult(submissionResult.getJobID()).get(),userCodeClassloader);return submissionResult;})).thenApply(result -> new MiniClusterJobClient(result.getJobID(),miniCluster,userCodeClassloader,MiniClusterJobClient.JobFinalizationBehavior.SHUTDOWN_CLUSTER)).whenComplete((ignored, throwable) -> {if (throwable != null) {// We failed to create the JobClient and must shutdown to ensure cleanup.shutDownCluster(miniCluster);}}).thenApply(Function.identity());}
这个方法主要执行内容有以下几步:
1.启动miniCluster;2.向mini cluster提交jobGraph;3.jobGraph提交成功后返回submissionResult;4.将结果包装成MiniClusterJobClient并返回;5.如果有异常产生则关闭mini cluster;6.如果5没有异常产生则反之返回4产生的结果。
从上面我们也能看出CompletableFuture流式编程的魅力,在这里我们主要关注下taskmanager、jobmanager、resourcemanager这些核心组件的执行动作。在MiniCluster#start方法内部会处理taskmanager和resourcemanager的逻辑,而jobmanager的逻辑主要在提交任务的流程里。
taskManager
MiniCluster#start方法内部会调用startTaskManagers方法,关于这个方法之前有写过一篇文章进行分析,可以看下之前写过的一篇文章flink taskmanager启动篇。
这里主要来挼一下整体的流程:
startTaskManagers() => startTaskExecutor() => taskExecutor.start() => TaskExecutor#onStart =>startTaskExecutorServices() => resourceManagerLeaderRetriever.start(new ResourceManagerLeaderListener()) => StandaloneLeaderRetrievalService#start => listener.notifyLeaderAddress(leaderAddress, leaderId) =>
在resourceManager选主成功后会进行回调通知,紧接着会进入到org.apache.flink.runtime.taskexecutor.TaskExecutor.ResourceManagerLeaderListener#notifyLeaderAddress方法中,我们来看下具体的代码逻辑:
@Overridepublic void notifyLeaderAddress(final String leaderAddress, final UUID leaderSessionID) {// 异步执行,rpc触发runAsync(() -> notifyOfNewResourceManagerLeader(leaderAddress,ResourceManagerId.fromUuidOrNull(leaderSessionID)));}
继续来看org.apache.flink.runtime.taskexecutor.TaskExecutor#notifyOfNewResourceManagerLeader方法:
private void notifyOfNewResourceManagerLeader(String newLeaderAddress, ResourceManagerId newResourceManagerId) {resourceManagerAddress = createResourceManagerAddress(newLeaderAddress, newResourceManagerId);// 重新连接resourceManagerreconnectToResourceManager(new FlinkException(String.format("ResourceManager leader changed to new address %s", resourceManagerAddress)));}
在这里会去建立和resourceManager的连接,具体代码如下:
private void reconnectToResourceManager(Exception cause) {// 关闭之前的resourceManager的连接closeResourceManagerConnection(cause);startRegistrationTimeout();tryConnectToResourceManager();}private void tryConnectToResourceManager() {if (resourceManagerAddress != null) {connectToResourceManager();}}private void connectToResourceManager() {assert(resourceManagerAddress != null);assert(establishedResourceManagerConnection == null);assert(resourceManagerConnection == null);log.info("Connecting to ResourceManager {}.", resourceManagerAddress);final TaskExecutorRegistration taskExecutorRegistration = new TaskExecutorRegistration(getAddress(),getResourceID(),unresolvedTaskManagerLocation.getDataPort(),JMXService.getPort().orElse(-1),hardwareDescription,memoryConfiguration,taskManagerConfiguration.getDefaultSlotResourceProfile(),taskManagerConfiguration.getTotalResourceProfile());resourceManagerConnection =new TaskExecutorToResourceManagerConnection(log,getRpcService(),taskManagerConfiguration.getRetryingRegistrationConfiguration(),resourceManagerAddress.getAddress(),resourceManagerAddress.getResourceManagerId(),getMainThreadExecutor(),new ResourceManagerRegistrationListener(),taskExecutorRegistration);resourceManagerConnection.start();}
在这里会调用resourceManagerConnection.start方法,这个方法其实是内有乾坤的,我们来看一下:
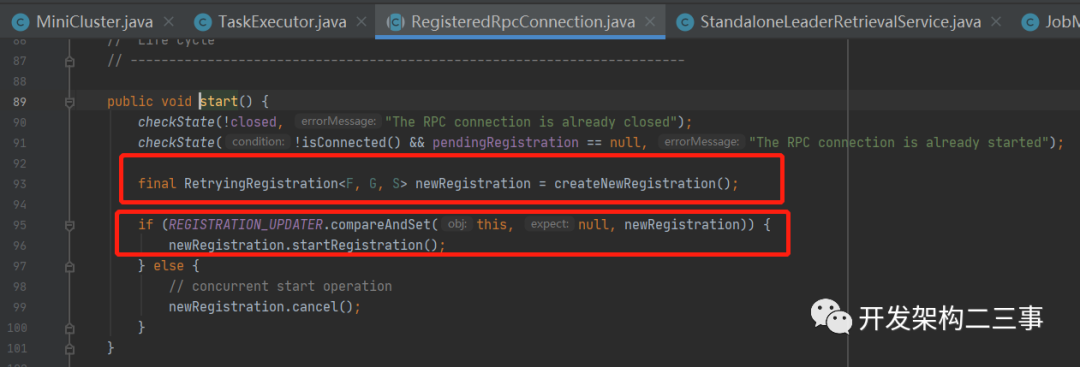
这里我们主要关注下createNewRegistration方法:
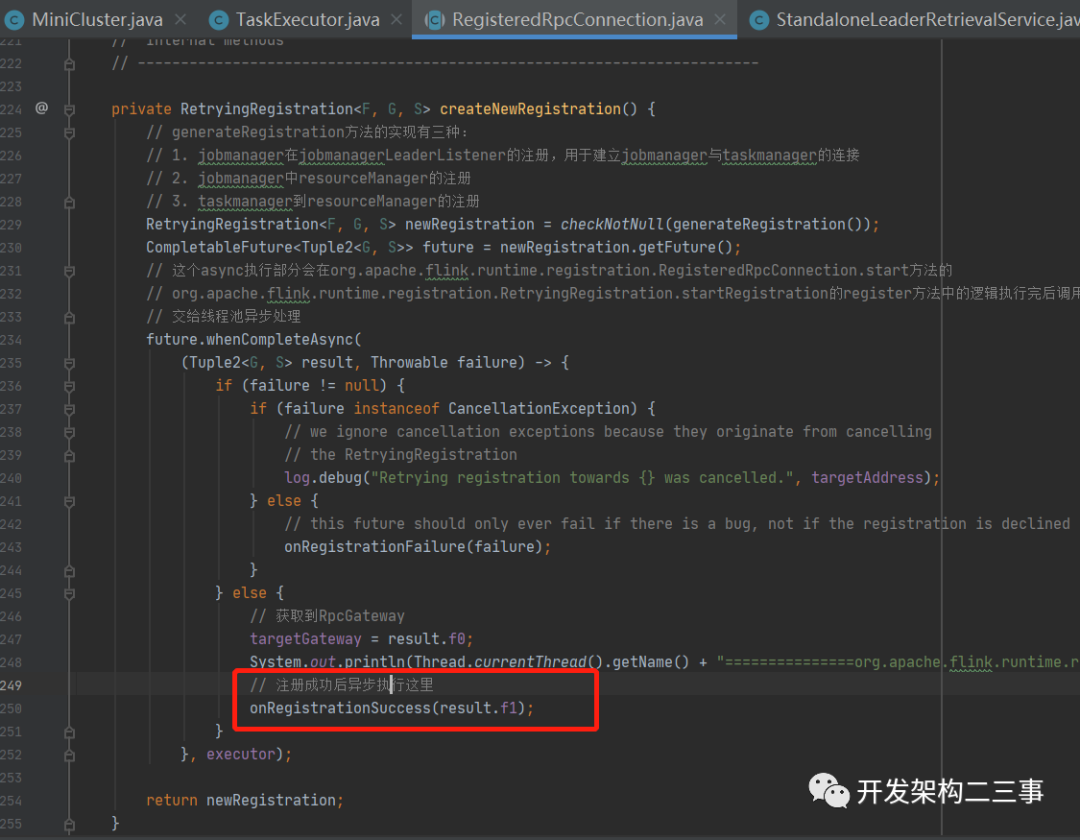
这里会在和resourceManager连接成功后回调onRegistrationSuccess方法,它在org.apache.flink.runtime.taskexecutor.TaskExecutorToResourceManagerConnection中的实现为:
@Overrideprotected void onRegistrationSuccess(TaskExecutorRegistrationSuccess success) {log.info("Successful registration at resource manager {} under registration id {}.",getTargetAddress(), success.getRegistrationId());registrationListener.onRegistrationSuccess(this, success);}
然后进入到TaskExecutor.ResourceManagerRegistrationListener#onRegistrationSuccess方法中:
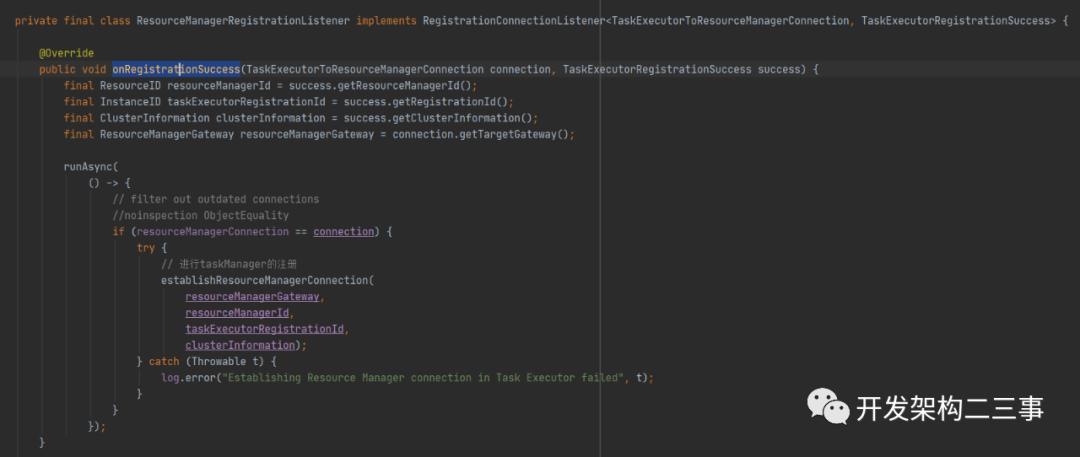
接着进入到org.apache.flink.runtime.taskexecutor.TaskExecutor#establishResourceManagerConnection方法:
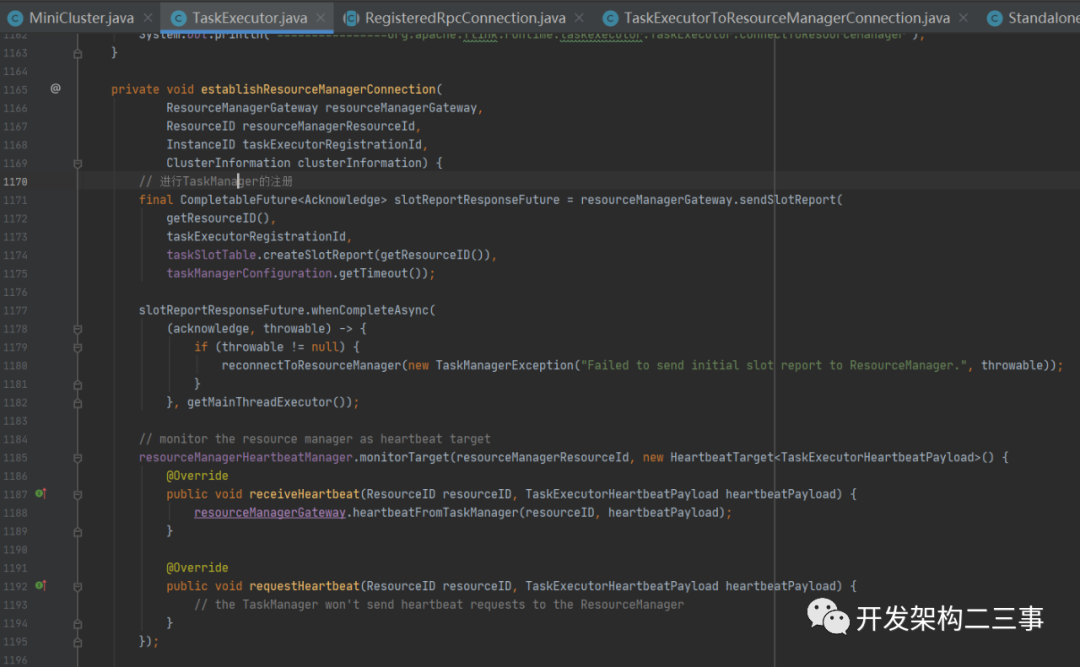
这里主要有两个工作:1. 向ResourceManager注册,上报slot信息;2. 设置与ResourceManager之间的心跳监测。
ResourceManager
在MiniCluster#start方法内部有一段代码片段:
setupDispatcherResourceManagerComponents(configuration, dispatcherResourceManagerComponentRpcServiceFactory, metricQueryServiceRetriever);
在org.apache.flink.runtime.minicluster.MiniCluster#setupDispatcherResourceManagerComponents方法内部有一段执行逻辑为:
dispatcherResourceManagerComponents.addAll(createDispatcherResourceManagerComponents(configuration,dispatcherResourceManagreComponentRpcServiceFactory,haServices,blobServer,heartbeatServices,metricRegistry,metricQueryServiceRetriever,new ShutDownFatalErrorHandler()));
而createDispatcherResourceManagerComponents方法的执行逻辑为:
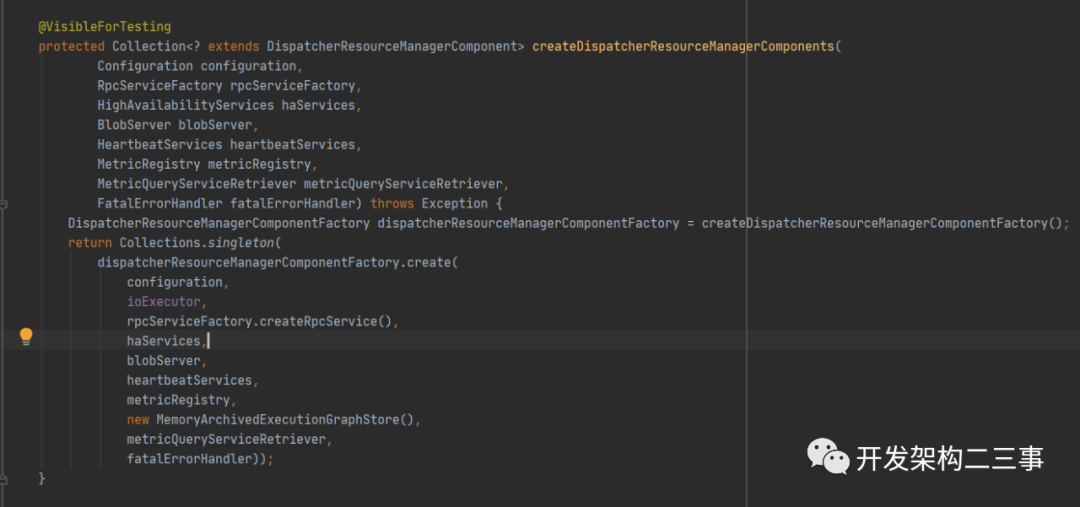
在org.apache.flink.runtime.entrypoint.component.DefaultDispatcherResourceManagerComponentFactory#create方法中会根据resourceManagerFactory执行resourceManager的执行逻辑并启动resourceManager。
整体方法的执行逻辑为:
resourceManager#start => ResourceManager#onStart => ResourceManager#startResourceManagerServices => leaderElectionService.start(this) => EmbeddedLeaderElectionService#start =>
我们来看下org.apache.flink.runtime.highavailability.nonha.embedded.EmbeddedLeaderService.EmbeddedLeaderElectionService#start方法:
@Overridepublic void start(LeaderContender contender) throws Exception {checkNotNull(contender);// 添加contenderaddContender(this, contender);}private void addContender(EmbeddedLeaderElectionService service, LeaderContender contender) {synchronized (lock) {checkState(!shutdown, "leader election service is shut down");checkState(!service.running, "leader election service is already started");try {// 如果已经存在抛出异常if (!allLeaderContenders.add(service)) {throw new IllegalStateException("leader election service was added to this service multiple times");}service.contender = contender;service.running = true;updateLeader().whenComplete((aVoid, throwable) -> {if (throwable != null) {fatalError(throwable);}});}catch (Throwable t) {fatalError(t);}}}
紧接着进入到org.apache.flink.runtime.highavailability.nonha.embedded.EmbeddedLeaderService#updateLeader方法:
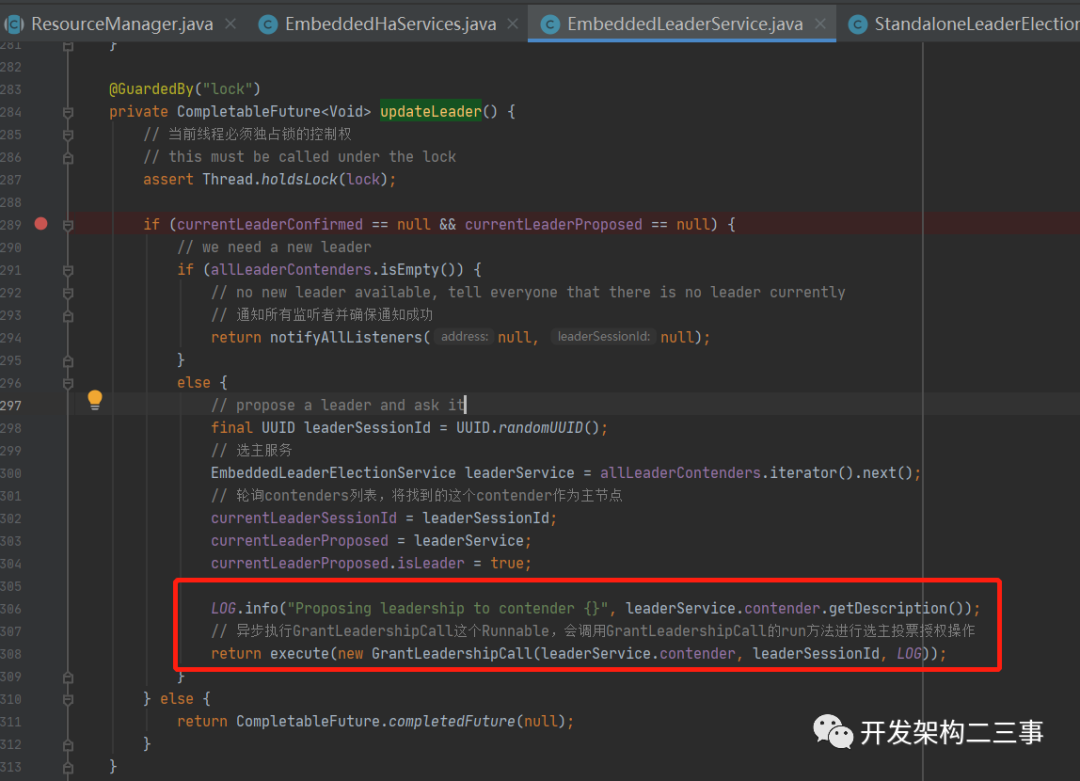
在org.apache.flink.runtime.highavailability.nonha.embedded.EmbeddedLeaderService.GrantLeadershipCall#run方法中:
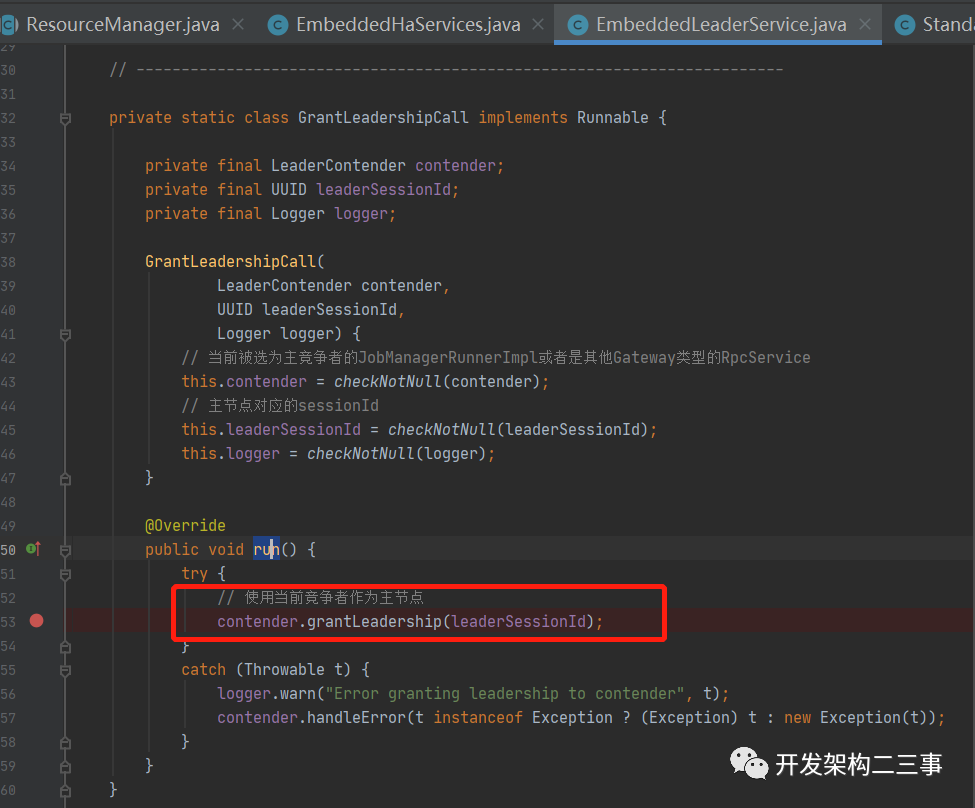
紧接着进入到org.apache.flink.runtime.resourcemanager.ResourceManager#grantLeadership方法:
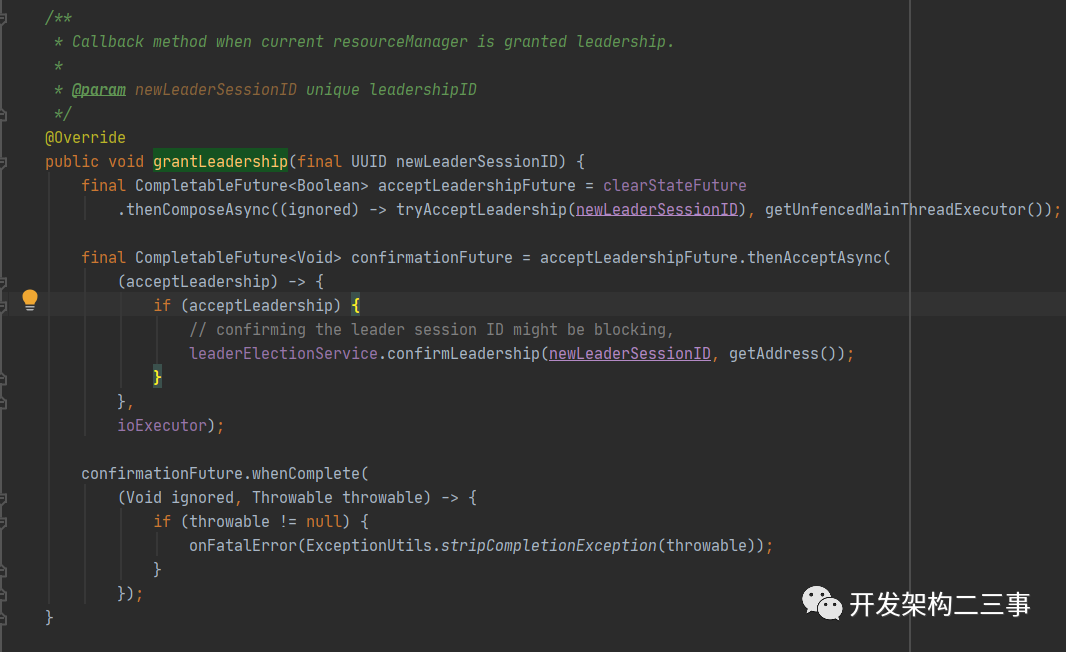
这个方法是用来做确定了ResourceManager的主节点后的回调方法。
JobManager
我们来看org.apache.flink.runtime.minicluster.MiniCluster#submitJob方法:
public CompletableFuture<JobSubmissionResult> submitJob(JobGraph jobGraph) {final CompletableFuture<DispatcherGateway> dispatcherGatewayFuture = getDispatcherGatewayFuture();final CompletableFuture<InetSocketAddress> blobServerAddressFuture = createBlobServerAddress(dispatcherGatewayFuture);final CompletableFuture<Void> jarUploadFuture = uploadAndSetJobFiles(blobServerAddressFuture, jobGraph);final CompletableFuture<Acknowledge> acknowledgeCompletableFuture = jarUploadFuture.thenCombine(dispatcherGatewayFuture,(Void ack, DispatcherGateway dispatcherGateway) -> dispatcherGateway.submitJob(jobGraph, rpcTimeout)).thenCompose(Function.identity());return acknowledgeCompletableFuture.thenApply((Acknowledge ignored) -> new JobSubmissionResult(jobGraph.getJobID()));}
上面这个方法的整个执行步骤为:
1.通过dispatcherGatewayRetriever去获取DispatcherGateway,返回的是dispatcherGatewayFuture;2.通过dispatcherGateway获取blobServerAddress;3.利用blobServer和jobGraph去执行jar的上传;4.利用dispatcherGatewayFuture返回的dispatcherGateway执行jobGraph的提交。
接下来进入到org.apache.flink.runtime.dispatcher.Dispatcher#submitJob方法:
@Overridepublic CompletableFuture<Acknowledge> submitJob(JobGraph jobGraph, Time timeout) {log.info("Received JobGraph submission {} ({}).", jobGraph.getJobID(), jobGraph.getName());try {if (isDuplicateJob(jobGraph.getJobID())) {return FutureUtils.completedExceptionally(new DuplicateJobSubmissionException(jobGraph.getJobID()));} else if (isPartialResourceConfigured(jobGraph)) {return FutureUtils.completedExceptionally(new JobSubmissionException(jobGraph.getJobID(),"Currently jobs is not supported if parts of the vertices have " +"resources configured. The limitation will be removed in future versions."));} else {return internalSubmitJob(jobGraph);}} catch (FlinkException e) {return FutureUtils.completedExceptionally(e);}}
•这里会根据jobId去判断一下这个job是不是已经被提交或执行;•紧接着进入到internalSubmitJob方法,执行真正的提交任务的逻辑。
我们来看org.apache.flink.runtime.dispatcher.Dispatcher#internalSubmitJob方法的代码:
private CompletableFuture<Acknowledge> internalSubmitJob(JobGraph jobGraph) {log.info("Submitting job {} ({}).", jobGraph.getJobID(), jobGraph.getName());final CompletableFuture<Acknowledge> persistAndRunFuture = waitForTerminatingJob(jobGraph.getJobID(),jobGraph,this::persistAndRunJob).thenApply(ignored -> Acknowledge.get());// 获取结果return persistAndRunFuture.handleAsync((acknowledge, throwable) -> {if (throwable != null) {cleanUpJobData(jobGraph.getJobID(), true);ClusterEntryPointExceptionUtils.tryEnrichClusterEntryPointError(throwable);final Throwable strippedThrowable = ExceptionUtils.stripCompletionException(throwable);log.error("Failed to submit job {}.", jobGraph.getJobID(), strippedThrowable);throw new CompletionException(new JobSubmissionException(jobGraph.getJobID(),"Failed to submit job.",strippedThrowable));} else {return acknowledge;}}, ioExecutor);}
在这个方法里会调用persistAndRunJob进行job的提交。注意这步操作是异步处理的,执行器为fencedMainThreadExecutor。
我们继续进入到org.apache.flink.runtime.dispatcher.Dispatcher#persistAndRunJob方法中:
private void persistAndRunJob(JobGraph jobGraph) throws Exception {jobGraphWriter.putJobGraph(jobGraph);runJob(jobGraph, ExecutionType.SUBMISSION);}
jobGraphWriter的主要作用是用于将jobGraph持久化在zk或者Kubernetes的leader节点。我们当前是在standalone模式下,不会进行这步处理。直接来看runJob方法:
private void runJob(JobGraph jobGraph, ExecutionType executionType) {Preconditions.checkState(!runningJobs.containsKey(jobGraph.getJobID()));long initializationTimestamp = System.currentTimeMillis();// 创建JobManagerRunnerCompletableFuture<JobManagerRunner> jobManagerRunnerFuture = createJobManagerRunner(jobGraph,initializationTimestamp);DispatcherJob dispatcherJob = DispatcherJob.createFor(jobManagerRunnerFuture,jobGraph.getJobID(),jobGraph.getName(),initializationTimestamp);runningJobs.put(jobGraph.getJobID(), dispatcherJob);---------------省略部分处理future返回结果的代码----------------}
这里的核心逻辑在createJobManagerRunner方法中,dispatcherJob与下面的逻辑主要用于处理jobManagerRunnerFuture的结果。我们主要来看下createJobManagerRunner方法:
CompletableFuture<JobManagerRunner> createJobManagerRunner(JobGraph jobGraph,long initializationTimestamp) {final RpcService rpcService = getRpcService();return CompletableFuture.supplyAsync(() -> {try {// 创建jobManagerRunnerJobManagerRunner runner = jobManagerRunnerFactory.createJobManagerRunner(jobGraph,configuration,rpcService,highAvailabilityServices,heartbeatServices,jobManagerSharedServices,new DefaultJobManagerJobMetricGroupFactory(jobManagerMetricGroup),fatalErrorHandler,initializationTimestamp);// 启动runnerrunner.start();return runner;} catch (Exception e) {throw new CompletionException(new JobInitializationException(jobGraph.getJobID(),"Could not instantiate JobManager.",e));}},ioExecutor); // do not use main thread executor. Otherwise, Dispatcher is blocked on JobManager creation}
我们来看下org.apache.flink.runtime.dispatcher.DefaultJobManagerRunnerFactory#createJobManagerRunner方法内部的逻辑,这里就直接无脑贴代码了:
@Overridepublic JobManagerRunner createJobManagerRunner(JobGraph jobGraph,Configuration configuration,RpcService rpcService,HighAvailabilityServices highAvailabilityServices,HeartbeatServices heartbeatServices,JobManagerSharedServices jobManagerServices,JobManagerJobMetricGroupFactory jobManagerJobMetricGroupFactory,FatalErrorHandler fatalErrorHandler,long initializationTimestamp) throws Exception {// 获取配置final JobMasterConfiguration jobMasterConfiguration = JobMasterConfiguration.fromConfiguration(configuration);// 获取slotPoolFactory,处理slot的管理逻辑final SlotPoolFactory slotPoolFactory = SlotPoolFactory.fromConfiguration(configuration);// 获取调度工厂final SchedulerNGFactory schedulerNGFactory = SchedulerNGFactoryFactory.createSchedulerNGFactory(configuration);// 创建处理shuffle操作的shuffleMasterfinal ShuffleMaster<?> shuffleMaster = ShuffleServiceLoader.loadShuffleServiceFactory(configuration).createShuffleMaster(configuration);// 创建jobMasterServiceFactoryfinal JobMasterServiceFactory jobMasterFactory = new DefaultJobMasterServiceFactory(jobMasterConfiguration,slotPoolFactory,rpcService,highAvailabilityServices,jobManagerServices,heartbeatServices,jobManagerJobMetricGroupFactory,fatalErrorHandler,schedulerNGFactory,shuffleMaster);// 创建JobManagerRunnerImpl实例return new JobManagerRunnerImpl(jobGraph,jobMasterFactory,highAvailabilityServices, jobManagerServices.getLibraryCacheManager().registerClassLoaderLease(jobGraph.getJobID()),jobManagerServices.getScheduledExecutorService(),fatalErrorHandler,initializationTimestamp);}
这个方法里的操作主要有:
1.获取jobmaster的配置信息,构建JobMasterConfiguration对象;2.通过配置信息创建SlotPoolFactory;3.创建处理shuffle操作的shuffleMaster;4.创建jobMasterServiceFactory;5.创建JobManagerRunnerImpl实例。
接下来就进入到JobManagerRunnerImpl的构造方法了,继续无脑贴代码:
public JobManagerRunnerImpl(final JobGraph jobGraph,final JobMasterServiceFactory jobMasterFactory,final HighAvailabilityServices haServices,final LibraryCacheManager.ClassLoaderLease classLoaderLease,final Executor executor,final FatalErrorHandler fatalErrorHandler,long initializationTimestamp) throws Exception {this.resultFuture = new CompletableFuture<>();this.terminationFuture = new CompletableFuture<>();this.leadershipOperation = CompletableFuture.completedFuture(null);this.jobGraph = checkNotNull(jobGraph);this.classLoaderLease = checkNotNull(classLoaderLease);this.executor = checkNotNull(executor);this.fatalErrorHandler = checkNotNull(fatalErrorHandler);checkArgument(jobGraph.getNumberOfVertices() > 0, "The given job is empty");// libraries and class loader firstfinal ClassLoader userCodeLoader;try {userCodeLoader = classLoaderLease.getOrResolveClassLoader(jobGraph.getUserJarBlobKeys(),jobGraph.getClasspaths()).asClassLoader();} catch (IOException e) {throw new Exception("Cannot set up the user code libraries: " + e.getMessage(), e);}// high availability services nextthis.runningJobsRegistry = haServices.getRunningJobsRegistry();this.leaderElectionService = haServices.getJobManagerLeaderElectionService(jobGraph.getJobID());this.leaderGatewayFuture = new CompletableFuture<>();// now start the JobManagerthis.jobMasterService = jobMasterFactory.createJobMasterService(jobGraph, this, userCodeLoader, initializationTimestamp);}
除了相关类加载器、执行器、选主服务的准备工作外,这里会创建jobMasterService,其核心逻辑在jobMasterFactory.createJobMasterService方法中,默认使用的jobMasterFactory是DefaultJobMasterServiceFactory,在org.apache.flink.runtime.jobmaster.factories.DefaultJobMasterServiceFactory#createJobMasterService方法内部会创建一个JobMaster对象。在具体来看JobMaster的内部创建逻辑之前,我们先来看下JobManagerRunnerImpl#start方法:
@Overridepublic void start() throws Exception {try {// 这里传入的contender是JobManagerRunnerImpl类型的,会在选举完成时进行contender的回调逻辑leaderElectionService.start(this);} catch (Exception e) {log.error("Could not start the JobManager because the leader election service did not start.", e);throw new Exception("Could not start the leader election service.", e);}}
我们的场景中使用的leaderElectionService是StandaloneLeaderElectionService,StandaloneLeaderElectionService#start方法代码如下:
@Overridepublic void start(LeaderContender newContender) throws Exception {if (contender != null) {// Service was already startedthrow new IllegalArgumentException("Leader election service cannot be started multiple times.");}contender = Preconditions.checkNotNull(newContender);// directly grant leadership to the given contendercontender.grantLeadership(HighAvailabilityServices.DEFAULT_LEADER_ID);}
在我们的场景中传入的LeaderContender对象为JobManagerRunnerImpl实例,根据代码的执行流程会执行到JobManagerRunnerImpl的grantLeadership方法,也是确定了jobManager主节点之后的回调方法,代码如下:
@Overridepublic void grantLeadership(final UUID leaderSessionID) {synchronized (lock) {if (shutdown) {log.debug("JobManagerRunner cannot be granted leadership because it is already shut down.");return;}leadershipOperation = leadershipOperation.thenCompose((ignored) -> {synchronized (lock) {return verifyJobSchedulingStatusAndStartJobManager(leaderSessionID);}});handleException(leadershipOperation, "Could not start the job manager.");}}
那么紧接着我们来看下verifyJobSchedulingStatusAndStartJobManager方法:
private CompletableFuture<Void> verifyJobSchedulingStatusAndStartJobManager(UUID leaderSessionId) {final CompletableFuture<JobSchedulingStatus> jobSchedulingStatusFuture = getJobSchedulingStatus();return jobSchedulingStatusFuture.thenCompose(jobSchedulingStatus -> {if (jobSchedulingStatus == JobSchedulingStatus.DONE) {return jobAlreadyDone();} else {// 启动jobMasterreturn startJobMaster(leaderSessionId);}});}
可以看到在该方法内部会调用startJobMaster方法来启动JobMaster,具体流程来看下代码:
private CompletionStage<Void> startJobMaster(UUID leaderSessionId) {log.info("JobManager runner for job {} ({}) was granted leadership with session id {} at {}.",jobGraph.getName(), jobGraph.getJobID(), leaderSessionId, jobMasterService.getAddress());try {runningJobsRegistry.setJobRunning(jobGraph.getJobID());} catch (IOException e) {return FutureUtils.completedExceptionally(new FlinkException(String.format("Failed to set the job %s to running in the running jobs registry.", jobGraph.getJobID()),e));}final CompletableFuture<Acknowledge> startFuture;try {startFuture = jobMasterService.start(new JobMasterId(leaderSessionId));} catch (Exception e) {return FutureUtils.completedExceptionally(new FlinkException("Failed to start the JobMaster.", e));}final CompletableFuture<JobMasterGateway> currentLeaderGatewayFuture = leaderGatewayFuture;return startFuture.thenAcceptAsync((Acknowledge ack) -> confirmLeaderSessionIdIfStillLeader(leaderSessionId,jobMasterService.getAddress(),currentLeaderGatewayFuture),executor);}
上面这些代码里,我们主要关注下org.apache.flink.runtime.jobmaster.JobMaster#start方法:
public CompletableFuture<Acknowledge> start(final JobMasterId newJobMasterId) throws Exception {// make sure we receive RPC and async callsstart();return callAsyncWithoutFencing(() -> startJobExecution(newJobMasterId), RpcUtils.INF_TIMEOUT);}
这里会回调它的onStart()方法,具体为什么会回调onStart方法,可以看下之前写过的一篇文章flink taskmanager启动篇。JobMaster的onStart方法使用的是RpcEndpoint中的空实现。我们主要来看下org.apache.flink.runtime.jobmaster.JobMaster#startJobExecution方法:
//-- job starting and stopping -----------------------------------------------------------------private Acknowledge startJobExecution(JobMasterId newJobMasterId) throws Exception {validateRunsInMainThread();checkNotNull(newJobMasterId, "The new JobMasterId must not be null.");if (Objects.equals(getFencingToken(), newJobMasterId)) {log.info("Already started the job execution with JobMasterId {}.", newJobMasterId);return Acknowledge.get();}setNewFencingToken(newJobMasterId);startJobMasterServices();log.info("Starting execution of job {} ({}) under job master id {}.", jobGraph.getName(), jobGraph.getJobID(), newJobMasterId);resetAndStartScheduler();return Acknowledge.get();}
这里我们主要关注两个方法startJobMasterServices与resetAndStartScheduler。
先来看startJobMasterServices方法:
private void startJobMasterServices() throws Exception {startHeartbeatServices();// 启动slotPool// start the slot pool make sure the slot pool now accepts messages for this leaderslotPool.start(getFencingToken(), getAddress(), getMainThreadExecutor());//TODO: Remove once the ZooKeeperLeaderRetrieval returns the stored address upon start// try to reconnect to previously known leaderreconnectToResourceManager(new FlinkException("Starting JobMaster component."));// job is ready to go, try to establish connection with resource manager// - activate leader retrieval for the resource manager// - on notification of the leader, the connection will be established and// the slot pool will start requesting slots// 当资源管理器有了新的主节点时会回调监听器来通知resourceManagerLeaderRetriever.start(new ResourceManagerLeaderListener());}
这里会做一些初始化操作:
•启动心跳服务,维持与taskmanager和resourcemanager的心跳:

•对slotPool增加一些连接池的定时检测调度手段,如调度检查slot是否空闲,批量检查slot是否超时并根据实际日志级别输出调度日志等,slotPool.start方法:

•reconnectToResourceManager方法,如果之前已经知道了resourceManager的leader地址,这里会去连接resourceManager,在连接成功后slotpool可以进行申请slot的操作。•resourceManagerLeaderRetriever.start方法,来看下它的代码:
@Overridepublic void start(LeaderRetrievalListener listener) {checkNotNull(listener, "Listener must not be null.");synchronized (startStopLock) {checkState(!started, "StandaloneLeaderRetrievalService can only be started once.");started = true;// directly notify the listener, because we already know the leading JobManager's address// 在TaskExecutor启动时这里会直接触发org.apache.flink.runtime.taskexecutor.TaskExecutor.ResourceManagerLeaderListener的notifyLeaderAddress方法,因为这时候已经知道了jobManager的地址// 在JobMaster启动时,这里会触发org.apache.flink.runtime.jobmaster.JobMaster.ResourceManagerLeaderListener.notifyLeaderAddresslistener.notifyLeaderAddress(leaderAddress, leaderId);}}
我们进入到org.apache.flink.runtime.jobmaster.JobMaster.ResourceManagerLeaderListener#notifyLeaderAddress方法内部:
@Overridepublic void notifyLeaderAddress(final String leaderAddress, final UUID leaderSessionID) {runAsync(() -> notifyOfNewResourceManagerLeader(leaderAddress,ResourceManagerId.fromUuidOrNull(leaderSessionID)));}
再进入到org.apache.flink.runtime.jobmaster.JobMaster#notifyOfNewResourceManagerLeader方法内部:
private void notifyOfNewResourceManagerLeader(final String newResourceManagerAddress, final ResourceManagerId resourceManagerId) {resourceManagerAddress = createResourceManagerAddress(newResourceManagerAddress, resourceManagerId);reconnectToResourceManager(new FlinkException(String.format("ResourceManager leader changed to new address %s", resourceManagerAddress)));}
可以看到,这里会去连接新的resourceManager leader,然后进行相应的操作,我们继续来看它会进行哪些操作:
private void reconnectToResourceManager(Exception cause) {closeResourceManagerConnection(cause);tryConnectToResourceManager();}private void tryConnectToResourceManager() {if (resourceManagerAddress != null) {connectToResourceManager();}}private void connectToResourceManager() {assert(resourceManagerAddress != null);assert(resourceManagerConnection == null);assert(establishedResourceManagerConnection == null);log.info("Connecting to ResourceManager {}", resourceManagerAddress);resourceManagerConnection = new ResourceManagerConnection(log,jobGraph.getJobID(),resourceId,getAddress(),getFencingToken(),resourceManagerAddress.getAddress(),resourceManagerAddress.getResourceManagerId(),scheduledExecutorService);// 在与resourceManager连接失败时会进行重试resourceManagerConnection.start();}
我们接着来看resourceManagerConnection的start方法:
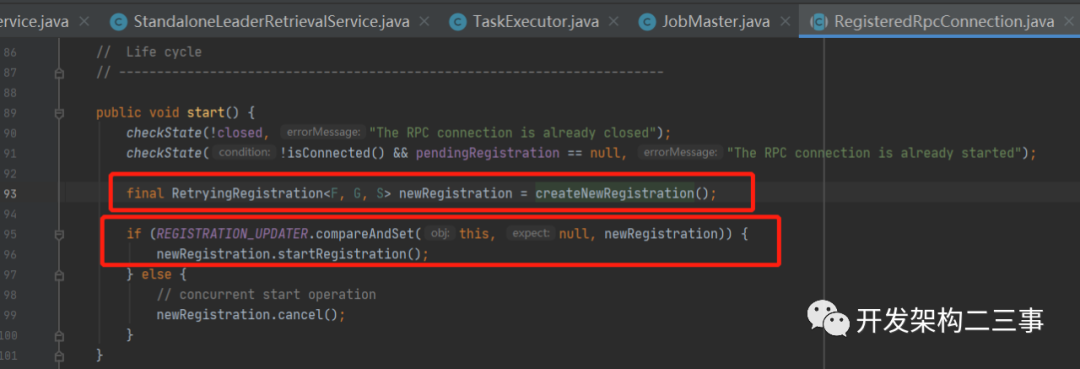
这里主要有两步操作,创建新的Registration和启动这个registration,我们分别来看一下:
•createNewRegistration方法:
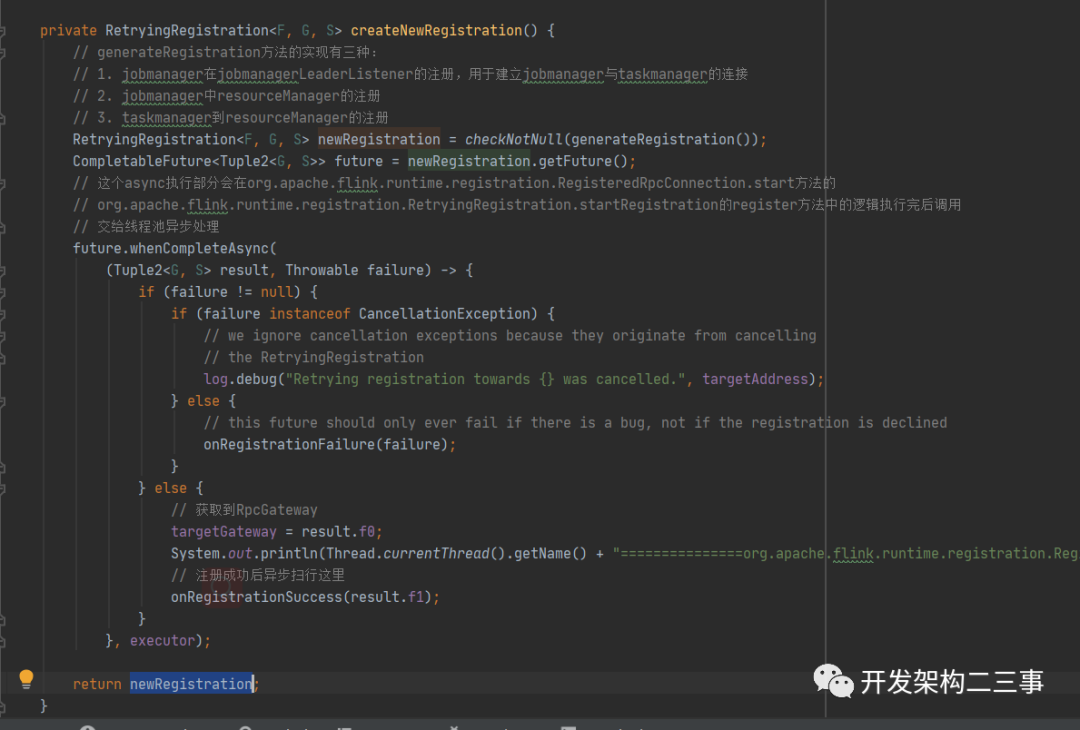
在RetryingRegistration内部维护着一个CompletableFuture,在future内部有一个注册成功的执行逻辑,即回调onRegistrationSuccess方法。
我们来看下org.apache.flink.runtime.jobmaster.JobMaster.ResourceManagerConnection#onRegistrationSuccess方法中的执行逻辑:
@Overrideprotected void onRegistrationSuccess(final JobMasterRegistrationSuccess success) {runAsync(() -> {// filter out outdated connections//noinspection ObjectEqualityif (this == resourceManagerConnection) {establishResourceManagerConnection(success);}});}
继续来分析org.apache.flink.runtime.jobmaster.JobMaster#establishResourceManagerConnection方法,这里先无脑贴代码:
private void establishResourceManagerConnection(final JobMasterRegistrationSuccess success) {final ResourceManagerId resourceManagerId = success.getResourceManagerId();// verify the response with current connectionif (resourceManagerConnection != null&& Objects.equals(resourceManagerConnection.getTargetLeaderId(), resourceManagerId)) {log.info("JobManager successfully registered at ResourceManager, leader id: {}.", resourceManagerId);final ResourceManagerGateway resourceManagerGateway = resourceManagerConnection.getTargetGateway();final ResourceID resourceManagerResourceId = success.getResourceManagerResourceId();establishedResourceManagerConnection = new EstablishedResourceManagerConnection(resourceManagerGateway,resourceManagerResourceId);slotPool.connectToResourceManager(resourceManagerGateway);resourceManagerHeartbeatManager.monitorTarget(resourceManagerResourceId, new HeartbeatTarget<Void>() {@Overridepublic void receiveHeartbeat(ResourceID resourceID, Void payload) {resourceManagerGateway.heartbeatFromJobManager(resourceID);}@Overridepublic void requestHeartbeat(ResourceID resourceID, Void payload) {// request heartbeat will never be called on the job manager side}});} else {log.debug("Ignoring resource manager connection to {} because it's duplicated or outdated.", resourceManagerId);}}
这里主要有两个操作:1. 建立slotPool与resourceManager的连接;2. 建立与resourceManager的心跳监测机制。我们主要来看下前者,直接来看org.apache.flink.runtime.jobmaster.slotpool.SlotPoolImpl#connectToResourceManager方法:
@Overridepublic void connectToResourceManager(@Nonnull ResourceManagerGateway resourceManagerGateway) {this.resourceManagerGateway = checkNotNull(resourceManagerGateway);// work on all slots waiting for this connectionfor (PendingRequest pendingRequest : waitingForResourceManager.values()) {requestSlotFromResourceManager(resourceManagerGateway, pendingRequest);}// all sent offwaitingForResourceManager.clear();}
该方法主要用于获取waitingForResourceManager中的pendingRequest,然后向resourceManager申请slot。
•newRegistration.startRegistration()方法,是具体的与resourceManager建立连接的方法,不是本文重点,这里就不过多去分析了。
再来看JobMaster#resetAndStartScheduler方法
在分析JobMaster#resetAndStartScheduler方法之前,我们先来看一下JobMaster的构造方法。由于JobMaster的构造方法比较长,这里我们主要关注下schedulerNG的实例化过程,代码片段如下:
// 创建DefaultSchedulerthis.schedulerNG = createScheduler(executionDeploymentTracker, jobManagerJobMetricGroup);
其中JobMaster#createScheduler方法代码如下:
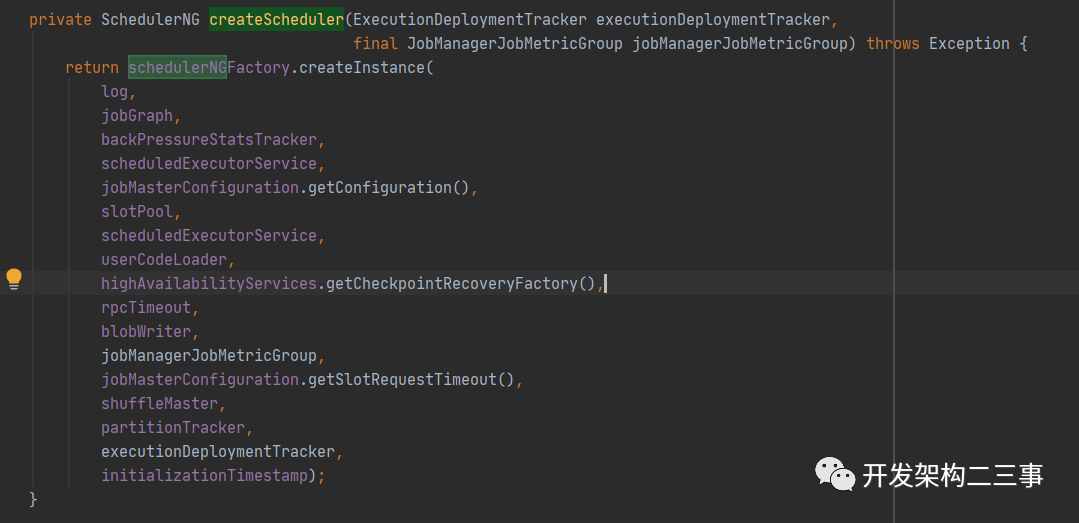
在这里是创建SchedulerNG对象的逻辑,这里我们主要关注下SchedulerBase#SchedulerBase构造方法中关于executionGraph的生成逻辑,部分代码片段如下:
// 创建和恢复ExecutionGraphthis.executionGraph = createAndRestoreExecutionGraph(jobManagerJobMetricGroup, checkNotNull(shuffleMaster), checkNotNull(partitionTracker), checkNotNull(executionDeploymentTracker), initializationTimestamp);// 调度拓朴里有partition信息和pipelineRegion信息this.schedulingTopology = executionGraph.getSchedulingTopology();
这里是从jobGraph生成executionGraph的逻辑,具体内容后面我们专门用一篇文章来进行分析。
这里我们继续来看JobMaster#resetAndStartScheduler方法,代码如下:
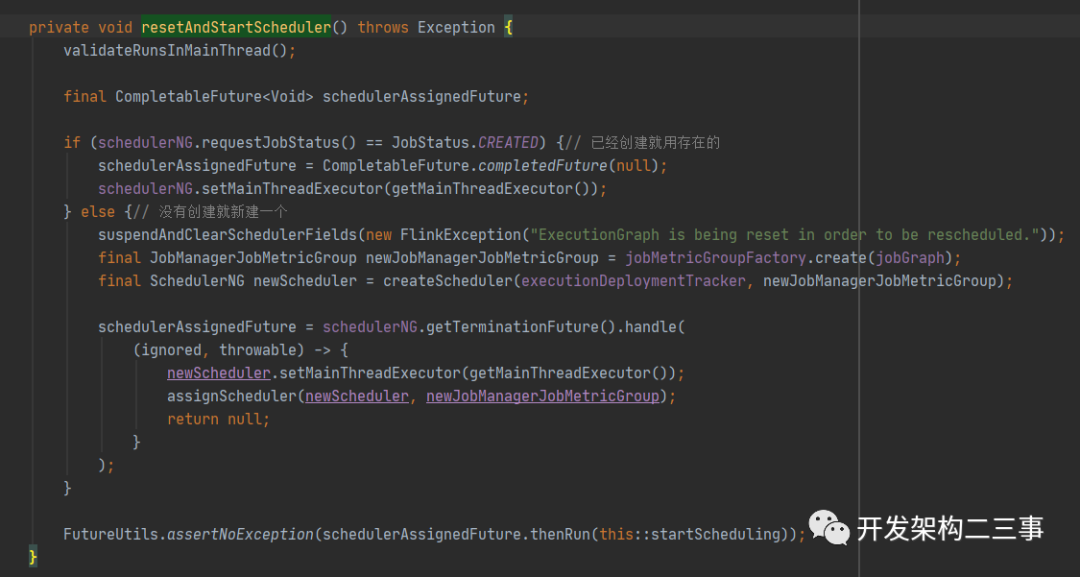
如果schedulerNG的requestJobStatus为JobStatus.CREATED,则指定schedulerNG的mainThreadExecutor为当前的mainThreadExecutor;否则,创建新的SchedulerNG实例并在创建完成后设置mainThreadExecutor;在schedulerAssignedFuture中的逻辑处理完成后,执行startScheduling方法,逻辑如下:
private void startScheduling() {checkState(jobStatusListener == null);// register self as job status change listenerjobStatusListener = new JobManagerJobStatusListener();schedulerNG.registerJobStatusListener(jobStatusListener);schedulerNG.startScheduling();}@Overridepublic final void startScheduling() {mainThreadExecutor.assertRunningInMainThread();registerJobMetrics();startAllOperatorCoordinators();startSchedulingInternal();}@Overrideprotected void startSchedulingInternal() {log.info("Starting scheduling with scheduling strategy [{}]",schedulingStrategy.getClass().getName());prepareExecutionGraphForNgScheduling();schedulingStrategy.startScheduling();}
在startScheduling方法内部是真正执行调度的部分,以我们这里使用到PipelinedRegionSchedulingStrategy#startScheduling方法为例:
@Overridepublic void startScheduling() {final Set<SchedulingPipelinedRegion> sourceRegions = IterableUtils.toStream(schedulingTopology.getAllPipelinedRegions()).filter(region -> !region.getConsumedResults().iterator().hasNext()).collect(Collectors.toSet());maybeScheduleRegions(sourceRegions);}private void maybeScheduleRegions(final Set<SchedulingPipelinedRegion> regions) {final List<SchedulingPipelinedRegion> regionsSorted =SchedulingStrategyUtils.sortPipelinedRegionsInTopologicalOrder(schedulingTopology, regions);for (SchedulingPipelinedRegion region : regionsSorted) {// 处理regionmaybeScheduleRegion(region);}}private void maybeScheduleRegion(final SchedulingPipelinedRegion region) {if (!areRegionInputsAllConsumable(region)) {return;}checkState(areRegionVerticesAllInCreatedState(region), "BUG: trying to schedule a region which is not in CREATED state");final List<ExecutionVertexDeploymentOption> vertexDeploymentOptions =SchedulingStrategyUtils.createExecutionVertexDeploymentOptions(regionVerticesSorted.get(region),id -> deploymentOption);// 申请slot并进行deployschedulerOperations.allocateSlotsAndDeploy(vertexDeploymentOptions);}
在内部会以region为单位进行各subTask的调度布署,篇幅问题这里就不再过多分析任务提交布署的部分了,后面用专门的文章来分析。
