




前言
我们在梳理flink sql 执行流程时以sql解析、sql校验、sql转化及sql优化的顺序来展开,本篇主要是对过程的梳理,不会涉及过多的代码部分,后面会针对各环节进行逐一分析。
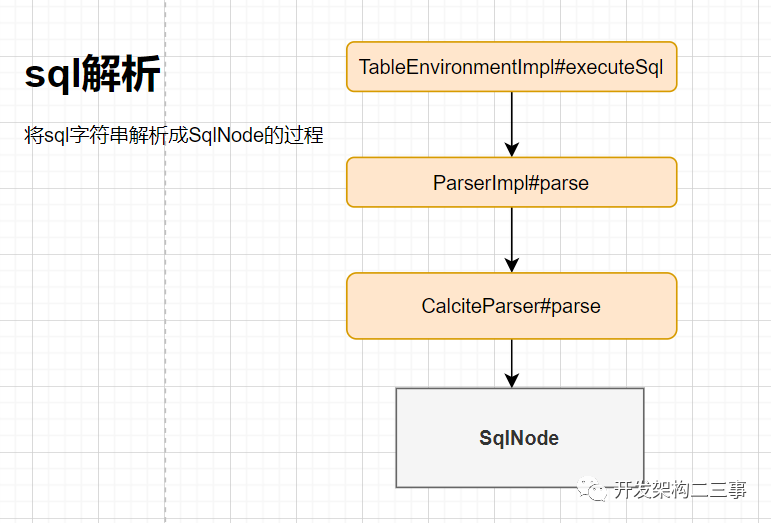
Parser
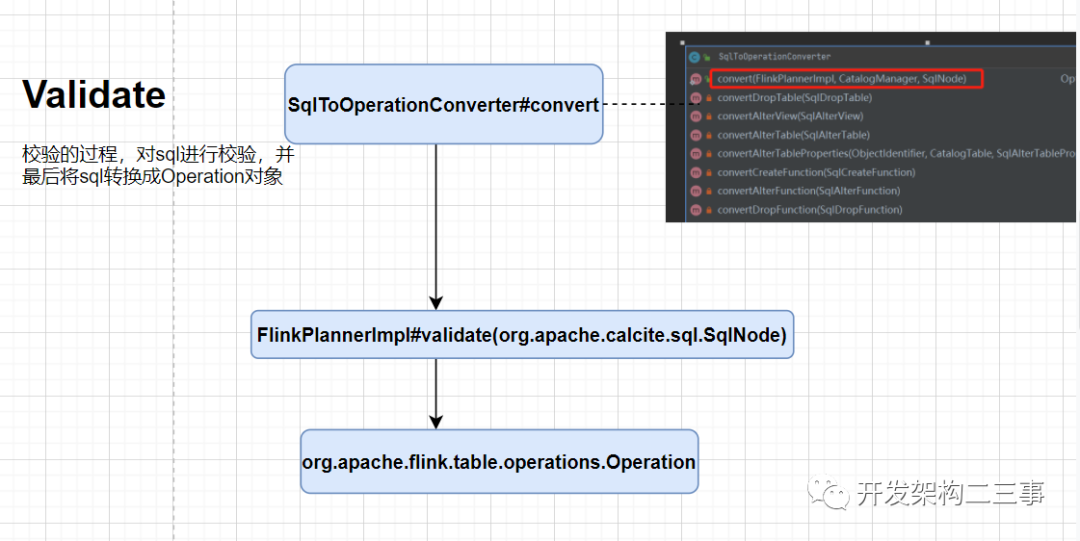
Validate
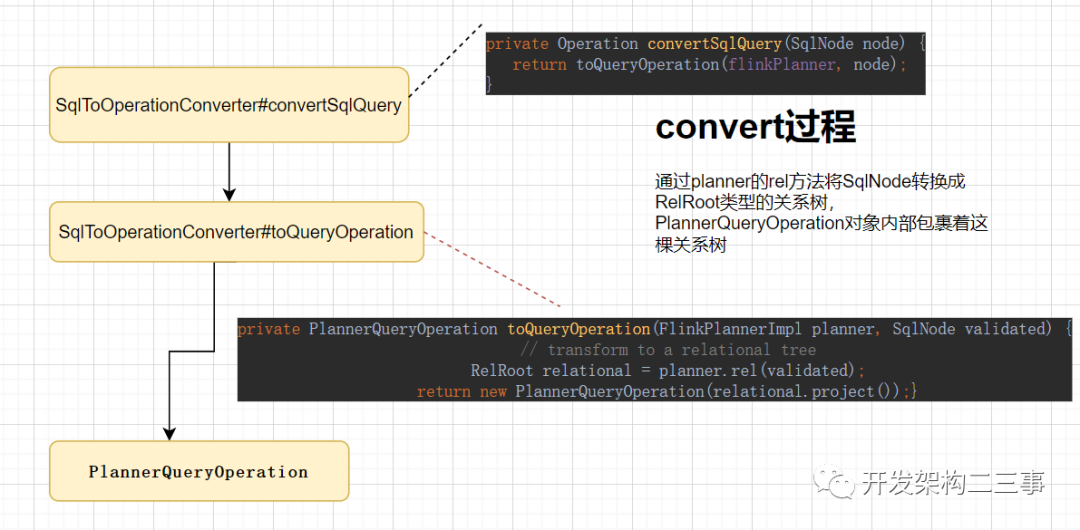
这里以SqlQuery操作的convert过程为例:
转换过程
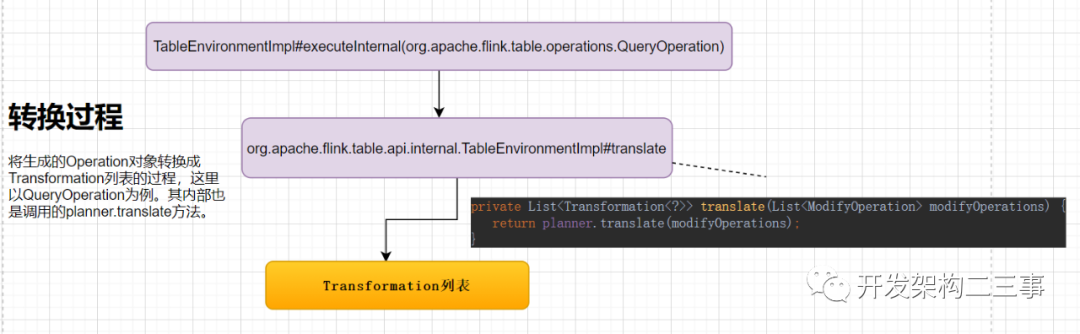
上面是TableEnvironmentImpl中的translate方法入口,我们来具体分析下planner.translate方法在PlannerBase转换过程如下:
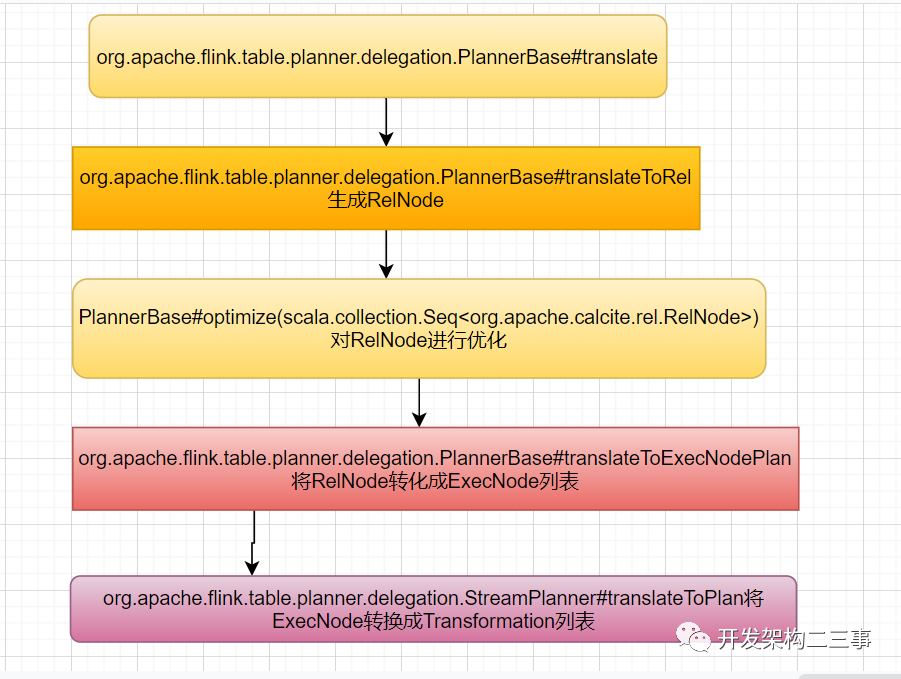
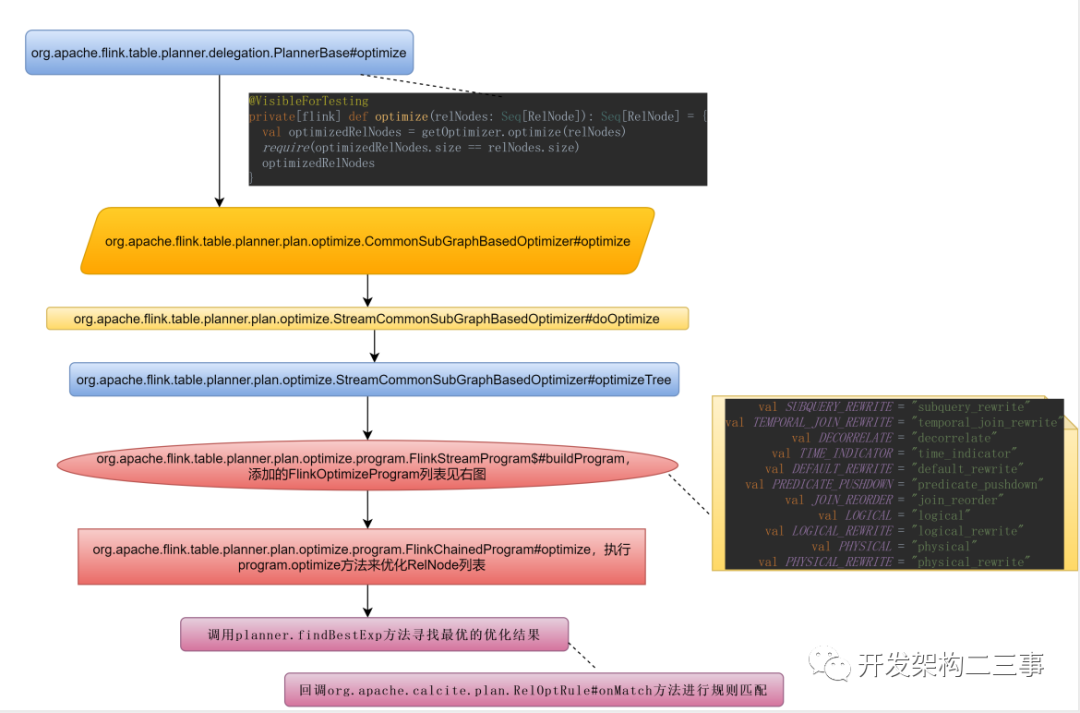
我们来看一下具体的optimize过程:
将FlinkPhysicalRel DAG转换成ExecNode DAG
@VisibleForTestingprivate[flink] def translateToExecNodePlan(optimizedRelNodes: Seq[RelNode]): util.List[ExecNode[_, _]] = {require(optimizedRelNodes.forall(_.isInstanceOf[FlinkPhysicalRel]))// Rewrite same rel object to different rel objects// in order to get the correct dag (dag reuse is based on object not digest)val shuttle = new SameRelObjectShuttle()val relsWithoutSameObj = optimizedRelNodes.map(_.accept(shuttle))// reuse subplanval reusedPlan = SubplanReuser.reuseDuplicatedSubplan(relsWithoutSameObj, config)// convert FlinkPhysicalRel DAG to ExecNode DAGreusedPlan.map(_.asInstanceOf[ExecNode[_, _]])}
在translateToExecNodePlan方法中将FlinkPhysicalRel DAG转换成ExecNode DAG并尝试复用重复的子计划。
ExecNode转换成Transformation
下面代码是将ExecNode列表转成Transformation列表的入口:
override protected def translateToPlan(execNodes: util.List[ExecNode[_, _]]): util.List[Transformation[_]] = {val planner = createDummyPlanner()planner.overrideEnvParallelism()execNodes.map {// 将execNode转成Transformationcase node: StreamExecNode[_] => node.translateToPlan(planner)case _ =>throw new TableException("Cannot generate DataStream due to an invalid logical plan. " +"This is a bug and should not happen. Please file an issue.")}}
结语
本篇主要梳理sql执行的流程中涉及到的各个步骤,针对内部调用apache calcite的api进行flink sql的优化及使用javacc 进行代码生成的部分在后续的篇幅中会逐一进行分析。
文章转载自开发架构二三事,如果涉嫌侵权,请发送邮件至:contact@modb.pro进行举报,并提供相关证据,一经查实,墨天轮将立刻删除相关内容。
