




主要针对一个WordCount的示例来对flink中关键组件如taskManager和jobMaster等服务的启动流程进行一个简要的分析。
示例代码
object WordCount {
def main(args: Array[String]) {
val params: ParameterTool = ParameterTool.fromArgs(args)
// set up execution environment
val env = ExecutionEnvironment.getExecutionEnvironment
// make parameters available in the web interface
env.getConfig.setGlobalJobParameters(params)
val text =
if (params.has("input")) {
env.readTextFile(params.get("input"))
} else {
println("Executing WordCount example with default input data set.")
println("Use --input to specify file input.")
env.fromCollection(WordCountData.WORDS)
}
// text.flatMap(_.toLowerCase.split("\\W+").filter(p => p.nonEmpty)).map(a => (a,1)).groupBy(0).sum(1)
val counts = text.flatMap { _.toLowerCase.split("\\W+") filter { _.nonEmpty } }
.map { (_, 1) }
.groupBy(0)
.sum(1)
if (params.has("output")) {
counts.writeAsCsv(params.get("output"), "\n", " ")
env.execute("Scala WordCount Example")
} else {
println("Printing result to stdout. Use --output to specify output path.")
counts.print()
}
}
}
这是一个执行WordCount的操作,我们以这个demo为入口来对整个执行流程进行分析记录。
生成JobGraph流程
这里就先流水式地记录一下,之后的文章中再详细地进行分析。
org.apache.flink.api.scala.DataSet#print:
def print(): Unit = {
javaSet.print()
}
org.apache.flink.api.java.DataSet#print()
public void print() throws Exception {
List<T> elements = collect();
for (T e: elements) {
System.out.println(e);
}
}
org.apache.flink.api.java.DataSet#collect
public List<T> collect() throws Exception {
final String id = new AbstractID().toString();
final TypeSerializer<T> serializer = getType().createSerializer(getExecutionEnvironment().getConfig());
this.output(new Utils.CollectHelper<>(id, serializer)).name("collect()");
JobExecutionResult res = getExecutionEnvironment().execute();
ArrayList<byte[]> accResult = res.getAccumulatorResult(id);
if (accResult != null) {
执行和结果归集的过程。
org.apache.flink.api.java.ExecutionEnvironment#execute()
public JobExecutionResult execute() throws Exception {
return execute(getDefaultName());
}
org.apache.flink.api.java.ExecutionEnvironment#execute(java.lang.String)
public JobExecutionResult execute(String jobName) throws Exception {
final JobClient jobClient = executeAsync(jobName);
try {
if (configuration.getBoolean(DeploymentOptions.ATTACHED)) {
lastJobExecutionResult = jobClient.getJobExecutionResult(userClassloader).get();
} else {
lastJobExecutionResult = new DetachedJobExecutionResult(jobClient.getJobID());
}
-----------------------------------------------------
job执行的方法。
org.apache.flink.api.java.ExecutionEnvironment#executeAsync(java.lang.String)
@PublicEvolving
public JobClient executeAsync(String jobName) throws Exception {
checkNotNull(configuration.get(DeploymentOptions.TARGET), "No execution.target specified in your configuration file.");
// StreamGraph与Plan都是Pipeline类型的
// 生成执行计划
final Plan plan = createProgramPlan(jobName);
// pipeline执行工厂,
final PipelineExecutorFactory executorFactory =
executorServiceLoader.getExecutorFactory(configuration);
checkNotNull(
executorFactory,
"Cannot find compatible factory for specified execution.target (=%s)",
configuration.get(DeploymentOptions.TARGET));
CompletableFuture<? extends JobClient> jobClientFuture = executorFactory
.getExecutor(configuration)
.execute(plan, configuration);
try {
JobClient jobClient = jobClientFuture.get();
jobListeners.forEach(jobListener -> jobListener.onJobSubmitted(jobClient, null));
return jobClient;
--------------------
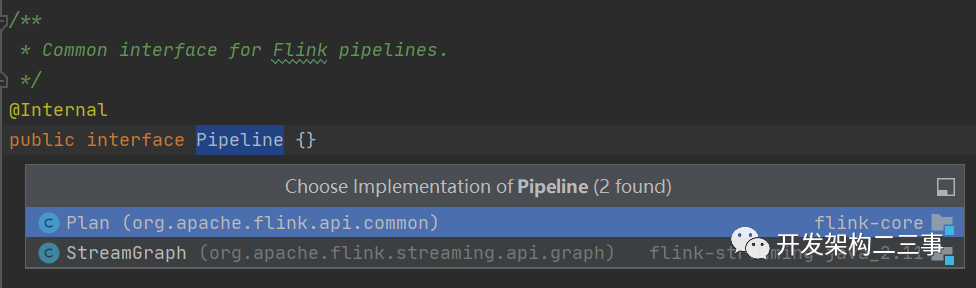
Pipeline有两个实现类:Plan和StreamGraph。当然在这个示例里生成的是Plan,在流式的情况下对应的就是StreamGraph类型。
继续往下看job的执行。
org.apache.flink.client.deployment.executors.LocalExecutor#execute
@Override
public CompletableFuture<? extends JobClient> execute(Pipeline pipeline, Configuration configuration) throws Exception {
checkNotNull(pipeline);
checkNotNull(configuration);
Configuration effectiveConfig = new Configuration();
effectiveConfig.addAll(this.configuration);
effectiveConfig.addAll(configuration);
// we only support attached execution with the local executor.
checkState(configuration.getBoolean(DeploymentOptions.ATTACHED));
final JobGraph jobGraph = getJobGraph(pipeline, effectiveConfig);
return PerJobMiniClusterFactory.createWithFactory(effectiveConfig, miniClusterFactory).submitJob(jobGraph);
}
这里的pipeline会对应Plan或者StreamGraph,在getJobGraph方法中会将对应的Pipeline转换成JobGraph,然后通过submitJob方法提交。
org.apache.flink.client.program.PerJobMiniClusterFactory#submitJob
/**
* Starts a {@link MiniCluster} and submits a job.
*/
public CompletableFuture<? extends JobClient> submitJob(JobGraph jobGraph) throws Exception {
MiniClusterConfiguration miniClusterConfig = getMiniClusterConfig(jobGraph.getMaximumParallelism());
MiniCluster miniCluster = miniClusterFactory.apply(miniClusterConfig);
miniCluster.start();
return miniCluster
.submitJob(jobGraph)
.thenApply(result -> new PerJobMiniClusterJobClient(result.getJobID(), miniCluster))
.whenComplete((ignored, throwable) -> {
if (throwable != null) {
// We failed to create the JobClient and must shutdown to ensure cleanup.
shutDownCluster(miniCluster);
}
});
}
在提交job时会创建一个MiniCluster,然后在miniCluster.start()中执行一些启动相关的操作。
org.apache.flink.runtime.minicluster.MiniCluster#start:
public void start() throws Exception {
synchronized (lock) {
----------------------
miniClusterConfiguration.getConfiguration();
final boolean useSingleRpcService = miniClusterConfiguration.getRpcServiceSharing() == RpcServiceSharing.SHARED;
try {
initializeIOFormatClasses(configuration);
LOG.info("Starting Metrics Registry");
metricRegistry = createMetricRegistry(configuration);
// bring up all the RPC services
LOG.info("Starting RPC Service(s)");
final RpcServiceFactory dispatcherResourceManagreComponentRpcServiceFactory;
if (useSingleRpcService) {
// 如果是single模式
// we always need the 'commonRpcService' for auxiliary calls
commonRpcService = createLocalRpcService(configuration);
final CommonRpcServiceFactory commonRpcServiceFactory = new CommonRpcServiceFactory(commonRpcService);
taskManagerRpcServiceFactory = commonRpcServiceFactory;
dispatcherResourceManagreComponentRpcServiceFactory = commonRpcServiceFactory;
} else {
// 其他模式
// start a new service per component, possibly with custom bind addresses
--------------------------
// we always need the 'commonRpcService' for auxiliary calls
// bind to the JobManager address with port 0
commonRpcService = createRemoteRpcService(configuration, jobManagerBindAddress, 0);
}
//启动metric actor service
RpcService metricQueryServiceRpcService = MetricUtils.startMetricsRpcService(
configuration,
commonRpcService.getAddress());
metricRegistry.startQueryService(metricQueryServiceRpcService, null);
processMetricGroup = MetricUtils.instantiateProcessMetricGroup(
metricRegistry,
RpcUtils.getHostname(commonRpcService),
ConfigurationUtils.getSystemResourceMetricsProbingInterval(configuration));
// 创建 io executor 这里使用的是fixed threadPool
ioExecutor = Executors.newFixedThreadPool(
Hardware.getNumberCPUCores(),
new ExecutorThreadFactory("mini-cluster-io"));
haServices = createHighAvailabilityServices(configuration, ioExecutor);
// 创建blobServer并启动
blobServer = new BlobServer(configuration, haServices.createBlobStore());
blobServer.start();
// 启动心跳service
heartbeatServices = HeartbeatServices.fromConfiguration(configuration);
blobCacheService = new BlobCacheService(
configuration, haServices.createBlobStore(), new InetSocketAddress(InetAddress.getLocalHost(), blobServer.getPort())
);
// 启动taskManager
startTaskManagers();
MetricQueryServiceRetriever metricQueryServiceRetriever = new RpcMetricQueryServiceRetriever(metricRegistry.getMetricQueryServiceRpcService());
setupDispatcherResourceManagerComponents(configuration, dispatcherResourceManagreComponentRpcServiceFactory, metricQueryServiceRetriever);
resourceManagerLeaderRetriever = haServices.getResourceManagerLeaderRetriever();
dispatcherLeaderRetriever = haServices.getDispatcherLeaderRetriever();
clusterRestEndpointLeaderRetrievalService = haServices.getClusterRestEndpointLeaderRetriever();
// dispatcher网关的retriever
dispatcherGatewayRetriever = new RpcGatewayRetriever<>(
commonRpcService,
DispatcherGateway.class,
DispatcherId::fromUuid,
20,
Time.milliseconds(20L));
// 资源管理器网关retriever
resourceManagerGatewayRetriever = new RpcGatewayRetriever<>(
commonRpcService,
ResourceManagerGateway.class,
ResourceManagerId::fromUuid,
20,
Time.milliseconds(20L));
// web monitor
webMonitorLeaderRetriever = new LeaderRetriever();
// 启动几个component
resourceManagerLeaderRetriever.start(resourceManagerGatewayRetriever);
dispatcherLeaderRetriever.start(dispatcherGatewayRetriever);
clusterRestEndpointLeaderRetrievalService.start(webMonitorLeaderRetriever);
----------------------------
这里会调用commonRpcService = createLocalRpcService(configuration)方法创建本地的RpcService,在这里会调用AkkaRpcServiceUtils中的remoteServiceBuilder方法构建本地的actor servcie:
protected RpcService createRemoteRpcService(
Configuration configuration,
String bindAddress,
int bindPort) throws Exception {
return AkkaRpcServiceUtils.remoteServiceBuilder(configuration, bindAddress, String.valueOf(bindPort))
.withBindAddress(bindAddress)
.withBindPort(bindPort)
.withCustomConfig(AkkaUtils.testDispatcherConfig())
.createAndStart();
}
org.apache.flink.runtime.minicluster.MiniCluster#startTaskManagers:
@GuardedBy("lock")
private void startTaskManagers() throws Exception {
final int numTaskManagers = miniClusterConfiguration.getNumTaskManagers();
LOG.info("Starting {} TaskManger(s)", numTaskManagers);
for (int i = 0; i < numTaskManagers; i++) {
startTaskExecutor();
}
}
org.apache.flink.runtime.minicluster.MiniCluster#startTaskExecutor:
@VisibleForTesting
void startTaskExecutor() throws Exception {
synchronized (lock) {
final Configuration configuration = miniClusterConfiguration.getConfiguration();
final TaskExecutor taskExecutor = TaskManagerRunner.startTaskManager(
configuration,
new ResourceID(UUID.randomUUID().toString()),
taskManagerRpcServiceFactory.createRpcService(),
haServices,
heartbeatServices,
metricRegistry,
blobCacheService,
useLocalCommunication(),
taskManagerTerminatingFatalErrorHandlerFactory.create(taskManagers.size()));
taskExecutor.start();
taskManagers.add(taskExecutor);
}
}
org.apache.flink.runtime.taskexecutor.TaskManagerRunner#startTaskManager:
org.apache.flink.runtime.taskexecutor.TaskManagerServices#fromConfiguration:
/**
* Creates and returns the task manager services.
*
* @param taskManagerServicesConfiguration task manager configuration
* @param taskManagerMetricGroup metric group of the task manager
* @param taskIOExecutor executor for async IO operations
* @return task manager components
* @throws Exception
*/
public static TaskManagerServices fromConfiguration(
TaskManagerServicesConfiguration taskManagerServicesConfiguration,
MetricGroup taskManagerMetricGroup,
Executor taskIOExecutor) throws Exception {
// pre-start checks
checkTempDirs(taskManagerServicesConfiguration.getTmpDirPaths());
// 创建 dispatcher
final TaskEventDispatcher taskEventDispatcher = new TaskEventDispatcher();
// start the I/O manager, it will create some temp directories.
final IOManager ioManager = new IOManagerAsync(taskManagerServicesConfiguration.getTmpDirPaths());
final ShuffleEnvironment<?, ?> shuffleEnvironment = createShuffleEnvironment(
taskManagerServicesConfiguration,
taskEventDispatcher,
taskManagerMetricGroup);
final int listeningDataPort = shuffleEnvironment.start();
// 创建并启动KvStateService
final KvStateService kvStateService = KvStateService.fromConfiguration(taskManagerServicesConfiguration);
kvStateService.start();
final UnresolvedTaskManagerLocation unresolvedTaskManagerLocation = new UnresolvedTaskManagerLocation(
taskManagerServicesConfiguration.getResourceID(),
taskManagerServicesConfiguration.getExternalAddress(),
// we expose the task manager location with the listening port
// iff the external data port is not explicitly defined
taskManagerServicesConfiguration.getExternalDataPort() > 0 ?
taskManagerServicesConfiguration.getExternalDataPort() :
listeningDataPort);
// 广播变量管理
final BroadcastVariableManager broadcastVariableManager = new BroadcastVariableManager();
// slot table
final TaskSlotTable<Task> taskSlotTable = createTaskSlotTable(
taskManagerServicesConfiguration.getNumberOfSlots(),
taskManagerServicesConfiguration.getTaskExecutorResourceSpec(),
taskManagerServicesConfiguration.getTimerServiceShutdownTimeout(),
taskManagerServicesConfiguration.getPageSize());
// job manager table
final JobManagerTable jobManagerTable = new JobManagerTable();
// JobLeaderService
final JobLeaderService jobLeaderService = new JobLeaderService(unresolvedTaskManagerLocation, taskManagerServicesConfiguration.getRetryingRegistrationConfiguration());
final String[] stateRootDirectoryStrings = taskManagerServicesConfiguration.getLocalRecoveryStateRootDirectories();
final File[] stateRootDirectoryFiles = new File[stateRootDirectoryStrings.length];
for (int i = 0; i < stateRootDirectoryStrings.length; ++i) {
stateRootDirectoryFiles[i] = new File(stateRootDirectoryStrings[i], LOCAL_STATE_SUB_DIRECTORY_ROOT);
}
// 本地状态管理器
final TaskExecutorLocalStateStoresManager taskStateManager = new TaskExecutorLocalStateStoresManager(
taskManagerServicesConfiguration.isLocalRecoveryEnabled(),
stateRootDirectoryFiles,
taskIOExecutor);
// io执行器
final ExecutorService ioExecutor = Executors.newSingleThreadExecutor(new ExecutorThreadFactory("taskexecutor-io"));
// 几个taskManagerService的集合
return new TaskManagerServices(
unresolvedTaskManagerLocation,
taskManagerServicesConfiguration.getManagedMemorySize().getBytes(),
ioManager,
shuffleEnvironment,
kvStateService,
broadcastVariableManager,
taskSlotTable,
jobManagerTable,
jobLeaderService,
taskStateManager,
taskEventDispatcher,
ioExecutor);
}
这里会创建并启动一系列的taskManager内部的service,这其中也包括org.apache.flink.runtime.taskexecutor.JobLeaderService。
到了这里,taskManager的初始化部分以及启动部分都已经完成,我们再回过头来看org.apache.flink.runtime.minicluster.MiniCluster#submitJob方法:
public CompletableFuture<JobSubmissionResult> submitJob(JobGraph jobGraph) {
final CompletableFuture<DispatcherGateway> dispatcherGatewayFuture = getDispatcherGatewayFuture();
final CompletableFuture<InetSocketAddress> blobServerAddressFuture = createBlobServerAddress(dispatcherGatewayFuture);
final CompletableFuture<Void> jarUploadFuture = uploadAndSetJobFiles(blobServerAddressFuture, jobGraph);
final CompletableFuture<Acknowledge> acknowledgeCompletableFuture = jarUploadFuture
.thenCombine(
dispatcherGatewayFuture,
(Void ack, DispatcherGateway dispatcherGateway) -> dispatcherGateway.submitJob(jobGraph, rpcTimeout))
.thenCompose(Function.identity());
return acknowledgeCompletableFuture.thenApply(
(Acknowledge ignored) -> new JobSubmissionResult(jobGraph.getJobID()));
}
org.apache.flink.runtime.dispatcher.Dispatcher#submitJob:
@Override
public CompletableFuture<Acknowledge> submitJob(JobGraph jobGraph, Time timeout) {
log.info("Received JobGraph submission {} ({}).", jobGraph.getJobID(), jobGraph.getName());
try {
if (isDuplicateJob(jobGraph.getJobID())) {
return FutureUtils.completedExceptionally(
new DuplicateJobSubmissionException(jobGraph.getJobID()));
} else if (isPartialResourceConfigured(jobGraph)) {
return FutureUtils.completedExceptionally(
new JobSubmissionException(jobGraph.getJobID(), "Currently jobs is not supported if parts of the vertices have " +
"resources configured. The limitation will be removed in future versions."));
} else {
return internalSubmitJob(jobGraph);
}
} catch (FlinkException e) {
return FutureUtils.completedExceptionally(e);
}
}
org.apache.flink.runtime.dispatcher.Dispatcher#internalSubmitJob:
private CompletableFuture<Acknowledge> internalSubmitJob(JobGraph jobGraph) {
log.info("Submitting job {} ({}).", jobGraph.getJobID(), jobGraph.getName());
final CompletableFuture<Acknowledge> persistAndRunFuture = waitForTerminatingJobManager(jobGraph.getJobID(), jobGraph, this::persistAndRunJob)
.thenApply(ignored -> Acknowledge.get());
return persistAndRunFuture.handleAsync((acknowledge, throwable) -> {
if (throwable != null) {
cleanUpJobData(jobGraph.getJobID(), true);
-------------------------
进入org.apache.flink.runtime.dispatcher.Dispatcher#persistAndRunJob方法:
private CompletableFuture<Void> persistAndRunJob(JobGraph jobGraph) throws Exception {
jobGraphWriter.putJobGraph(jobGraph);
final CompletableFuture<Void> runJobFuture = runJob(jobGraph);
return runJobFuture.whenComplete(BiConsumerWithException.unchecked((Object ignored, Throwable throwable) -> {
if (throwable != null) {
jobGraphWriter.removeJobGraph(jobGraph.getJobID());
}
}));
}
org.apache.flink.runtime.dispatcher.Dispatcher#runJob:
private CompletableFuture<Void> runJob(JobGraph jobGraph) {
Preconditions.checkState(!jobManagerRunnerFutures.containsKey(jobGraph.getJobID()));
final CompletableFuture<JobManagerRunner> jobManagerRunnerFuture = createJobManagerRunner(jobGraph);
jobManagerRunnerFutures.put(jobGraph.getJobID(), jobManagerRunnerFuture);
return jobManagerRunnerFuture
.thenApply(FunctionUtils.uncheckedFunction(this::startJobManagerRunner))
.thenApply(FunctionUtils.nullFn())
.whenCompleteAsync(
(ignored, throwable) -> {
if (throwable != null) {
jobManagerRunnerFutures.remove(jobGraph.getJobID());
}
},
getMainThreadExecutor());
}
org.apache.flink.runtime.dispatcher.Dispatcher#createJobManagerRunner:
private CompletableFuture<JobManagerRunner> createJobManagerRunner(JobGraph jobGraph) {
final RpcService rpcService = getRpcService();
return CompletableFuture.supplyAsync(
CheckedSupplier.unchecked(() ->
jobManagerRunnerFactory.createJobManagerRunner(
jobGraph,
configuration,
rpcService,
highAvailabilityServices,
heartbeatServices,
jobManagerSharedServices,
new DefaultJobManagerJobMetricGroupFactory(jobManagerMetricGroup),
fatalErrorHandler)),
rpcService.getExecutor());
}
通过org.apache.flink.runtime.dispatcher.DefaultJobManagerRunnerFactory#createJobManagerRunner创建JobManagerRunnerImpl实例:
public JobManagerRunnerImpl(
final JobGraph jobGraph,
final JobMasterServiceFactory jobMasterFactory,
final HighAvailabilityServices haServices,
final LibraryCacheManager libraryCacheManager,
final Executor executor,
final FatalErrorHandler fatalErrorHandler) throws Exception {
this.resultFuture = new CompletableFuture<>();
this.terminationFuture = new CompletableFuture<>();
this.leadershipOperation = CompletableFuture.completedFuture(null);
// make sure we cleanly shut down out JobManager services if initialization fails
try {
this.jobGraph = checkNotNull(jobGraph);
this.libraryCacheManager = checkNotNull(libraryCacheManager);
this.executor = checkNotNull(executor);
this.fatalErrorHandler = checkNotNull(fatalErrorHandler);
checkArgument(jobGraph.getNumberOfVertices() > 0, "The given job is empty");
// libraries and class loader first
try {
libraryCacheManager.registerJob(
jobGraph.getJobID(), jobGraph.getUserJarBlobKeys(), jobGraph.getClasspaths());
} catch (IOException e) {
throw new Exception("Cannot set up the user code libraries: " + e.getMessage(), e);
}
final ClassLoader userCodeLoader = libraryCacheManager.getClassLoader(jobGraph.getJobID());
if (userCodeLoader == null) {
throw new Exception("The user code class loader could not be initialized.");
}
// high availability services next
this.runningJobsRegistry = haServices.getRunningJobsRegistry();
this.leaderElectionService = haServices.getJobManagerLeaderElectionService(jobGraph.getJobID());
this.leaderGatewayFuture = new CompletableFuture<>();
// org.apache.flink.runtime.jobmaster.JobMasterService这个和taskManager中的jobMasterService是不同的
// now start the JobManager
this.jobMasterService = jobMasterFactory.createJobMasterService(jobGraph, this, userCodeLoader);
}
----------------------
jobMasterFactory.createJobMasterService(jobGraph, this, userCodeLoader):
@Override
public JobMaster createJobMasterService(
JobGraph jobGraph,
OnCompletionActions jobCompletionActions,
ClassLoader userCodeClassloader) throws Exception {
return new JobMaster(
rpcService,
jobMasterConfiguration,
ResourceID.generate(),
jobGraph,
haServices,
slotPoolFactory,
schedulerFactory,
jobManagerSharedServices,
heartbeatServices,
jobManagerJobMetricGroupFactory,
jobCompletionActions,
fatalErrorHandler,
userCodeClassloader,
schedulerNGFactory,
shuffleMaster,
lookup -> new JobMasterPartitionTrackerImpl(
jobGraph.getJobID(),
shuffleMaster,
lookup
));
}
这里创建了JobMaster。
org.apache.flink.runtime.dispatcher.Dispatcher#startJobManagerRunner:
private JobManagerRunner startJobManagerRunner(JobManagerRunner jobManagerRunner) throws Exception {
final JobID jobId = jobManagerRunner.getJobID();
FutureUtils.assertNoException(
jobManagerRunner.getResultFuture().handleAsync(
(ArchivedExecutionGraph archivedExecutionGraph, Throwable throwable) -> {
// check if we are still the active JobManagerRunner by checking the identity
final JobManagerRunner currentJobManagerRunner = Optional.ofNullable(jobManagerRunnerFutures.get(jobId))
.map(future -> future.getNow(null))
.orElse(null);
//noinspection ObjectEquality
------------------------
}, getMainThreadExecutor()));
jobManagerRunner.start();
return jobManagerRunner;
}
在这里启动jobMaster。
在Local client、taskManager、jobMaster中都会启动对应的一个actor service,然后相互之间会进行通信,如心跳和任务分配等。
