





作者:Moez Ali
本文约2500字,建议阅读8分钟

https://www.pycaret.org
conda create --name yourenvname python=3.6
conda activate yourenvname
pip install pycaret
python -m ipykernel install --user --name yourenvname --display-name "display-name"
pip install --upgrade pycaret

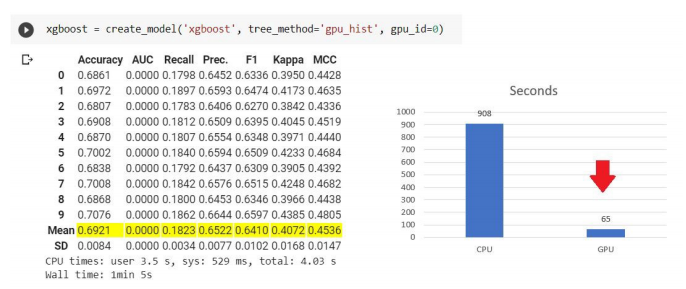
xgboost = create_model('xgboost', tree_method = 'gpu_hist')
tuned_xgboost = tune_model(xgboost)
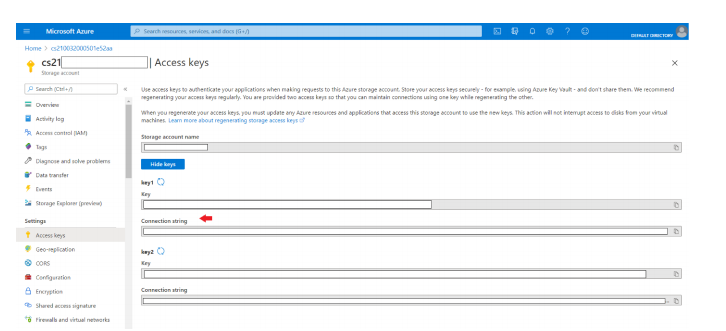
Import osos.environ['AZURE_STORAGE_CONNECTION_STRING'] = 'your-conn-string'from pycaret.classification import deploy_modeldeploy_model(model = model, model_name = 'model-name', platform = 'azure', authentication = {'container' : 'container-name'})
Import osos.environ['AZURE_STORAGE_CONNECTION_STRING'] = 'your-conn-string'
loaded_model = load_model(model_name = 'model-name',platform = 'azure', authentication = {'container' :'container-name'}
predictions = predict_model(loaded_model, data = new-dataframe)
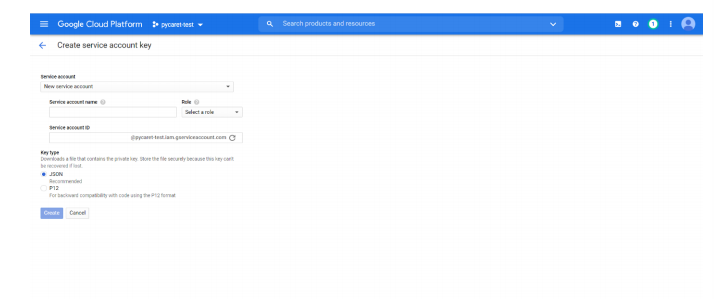
os.environ['GOOGLE_APPLICATION_CREDENTIALS'] ='c:/path-to-json- file.json'from pycaret.classification import deploy_modeldeploy_model(model = model, model_name = 'model-name',platform = 'gcp', authentication = {'project' : 'project-name','bucket' : 'bucket-name'})
os.environ['GOOGLE_APPLICATION_CREDENTIALS'] ='c:/path-to-json- file.json'
loaded_model = load_model(model_name = 'model-name',platform = 'gcp', authentication ='project-name', 'bucket' :'bucket-name'})
predictions = predict_model(loaded_model, data = new-dataframe)
exp1 = setup(data, target = 'target-name', log_experiment = True,experiment_name = 'exp-name')
xgboost = create_model('xgboost')......#其余的脚本
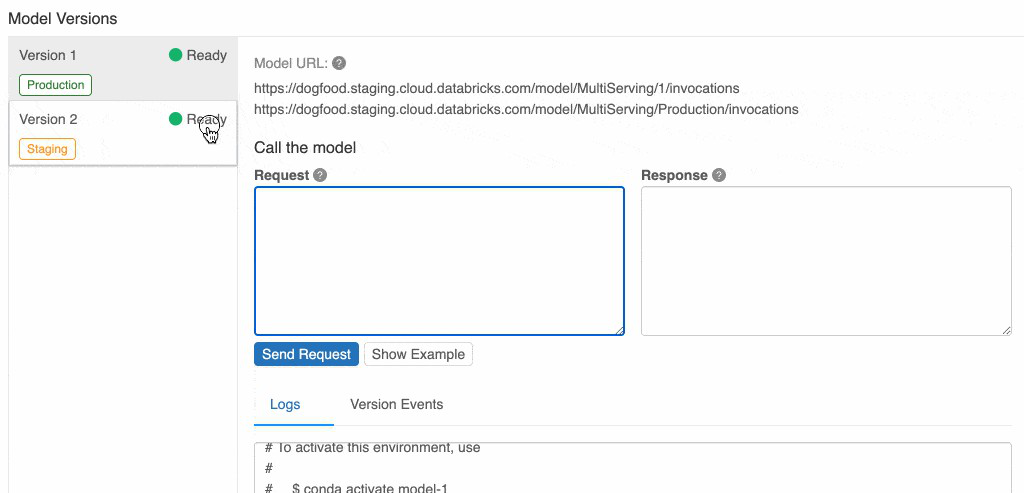
!mlflow ui
https://localhost:5000
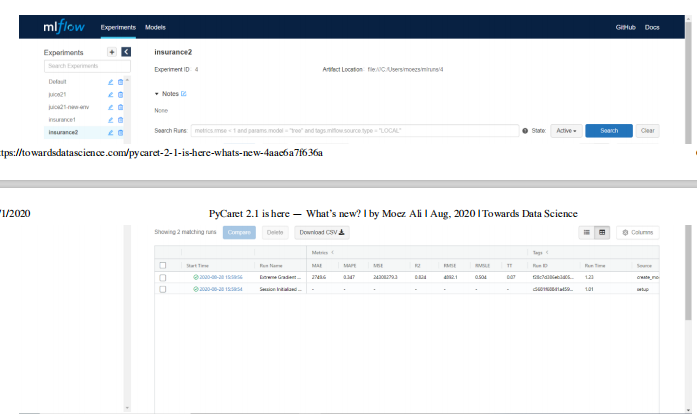
https://localhost:5000上的MLFlow UI
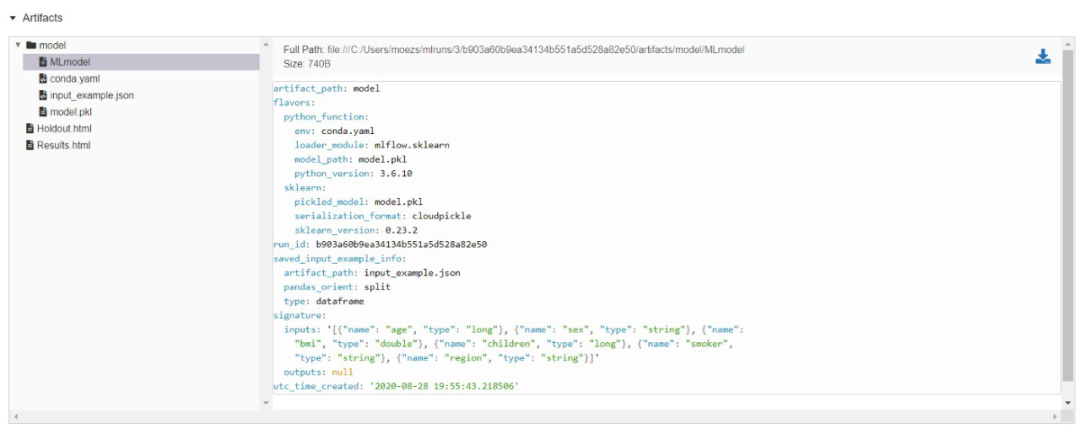
MLFLow代码
mlflow models serve -m local-path-to-model
curl http://127.0.0.1:5000/invocations -H 'Content-Type: application/json' -d '{"columns": ["age", "sex", "bmi", "children","smoker", "region"],"data": [[19, "female", 27.9, 0, "yes", "southwest"]]}'
(注:MLFlow的这一功能尚不支持Windows操作系统)。
mlflow sagemaker build-and-push-containermlflow sagemaker run-local -m <path-to-model>mlflow sagemaker deploy <parameters>
lr = create_model('lr')
plot_model(lr, scale = 5) # 默认值为 1
def my_function(y_true, y_pred):......
from sklearn.metrics import make_scorermy_own_scorer = make_scorer(my_function, needs_proba=True)
catboost = create_model('catboost')
tuned_catboost=tune_model(catboost,custom_scorer=my_own_scorer)
exp1 = setup(data, target = 'target-var', feature_selection = True,feature_selection_method = 'boruta')
compare_models函数中的blacklist 和whitelist 参数已变更为exclude 和 include,但是功能并没有改变。
在 compare_models函数中设置训练时间的上限,添加了新参数budget_time。
PyCaret 可以与Pandas 的数据类型兼容,它们在内部被转换为object,像处理 object 或 bool 一样。
在数值处理部分,在setup 函数 的numeric_imputation参数中添加了zero 方法。当method设置为 zero 时,将其替换为常数0。
为了方便阅读,predict_model 函数返回Label 列的原始值而不是编码值。
(https://github.com/pycaret/pycaret/)
原文链接:
https://towardsdatascience.com/pycaret-2-1-is-here-whats-new-4aae6a7f636a
译者简介

陈之炎,北京交通大学通信与控制工程专业毕业,获得工学硕士学位,历任长城计算机软件与系统公司工程师,大唐微电子公司工程师,现任北京吾译超群科技有限公司技术支持。目前从事智能化翻译教学系统的运营和维护,在人工智能深度学习和自然语言处理(NLP)方面积累有一定的经验。业余时间喜爱翻译创作,翻译作品主要有:IEC-ISO 7816、伊拉克石油工程项目、新财税主义宣言等等,其中中译英作品“新财税主义宣言”在GLOBAL TIMES正式发表。能够利用业余时间加入到THU 数据派平台的翻译志愿者小组,希望能和大家一起交流分享,共同进步。
翻译组招募信息
工作内容:需要一颗细致的心,将选取好的外文文章翻译成流畅的中文。如果你是数据科学/统计学/计算机类的留学生,或在海外从事相关工作,或对自己外语水平有信心的朋友欢迎加入翻译小组。
你能得到:定期的翻译培训提高志愿者的翻译水平,提高对于数据科学前沿的认知,海外的朋友可以和国内技术应用发展保持联系,THU数据派产学研的背景为志愿者带来好的发展机遇。
其他福利:来自于名企的数据科学工作者,北大清华以及海外等名校学生他们都将成为你在翻译小组的伙伴。
点击文末“阅读原文”加入数据派团队~
转载须知
如需转载,请在开篇显著位置注明作者和出处(转自:数据派ID:DatapiTHU),并在文章结尾放置数据派醒目二维码。有原创标识文章,请发送【文章名称-待授权公众号名称及ID】至联系邮箱,申请白名单授权并按要求编辑。
发布后请将链接反馈至联系邮箱(见下方)。未经许可的转载以及改编者,我们将依法追究其法律责任。


点击“阅读原文”拥抱组织
