





翻译:方芳 冯羽
校对:丁楠雅
编辑:刘文清
原文链接:
https://en.fabernovel.com/insights/tech-en/ai-for-dummies
本文长度为2250字,建议阅读5分钟
本文为大家详细解释了人工智能的定义和主要研究方法。
直入主题,咱们该先给人工智能来个全面的定义,对吧?
但悲催的是这种清晰唯一的定义在人工智能研究圈里是不存在的!(不存在至少是因为理解和定义智能本身就是个正在进行时。)
人工智能的三种定义
我们确实有很多种方式来定义什么是人工智能。第一种,也是最常见的一种,从人工智能研究广受欢迎的成果的角度:大体上来讲,人工智能或者是“创造和研究具备智能行为的机器”(注意:“具备”是怎么解释都行),或者是“创造和研究可以思考的机器”(注意:什么样的“思考”都行)。
第二种定义是从人工智能的组成部分或者其想解决的问题的角度,您最常听到的是这样的:
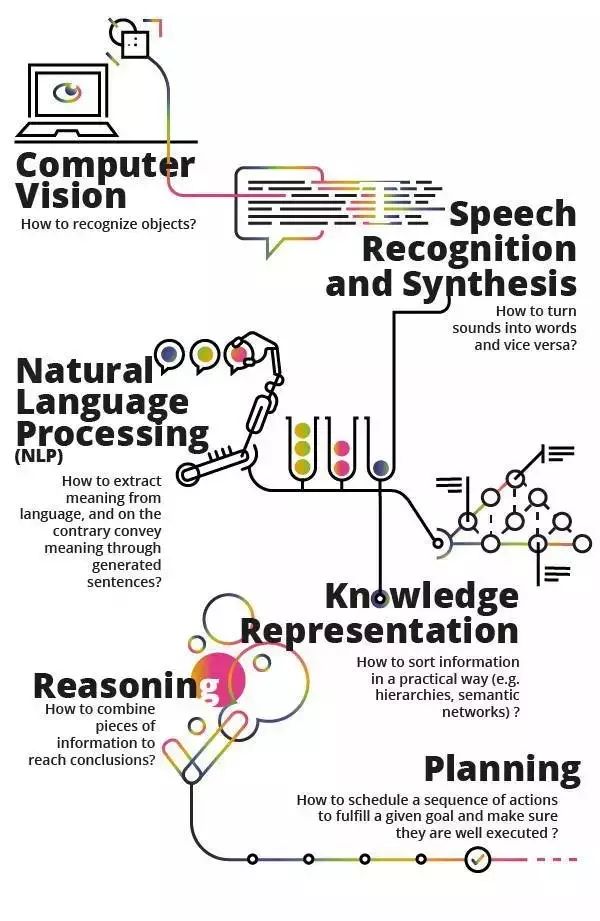
图译
计算机视觉:如何识别目标?
语音识别与合成:如何将声音转化为文字或将文字转换为声音
自然语言处理NLP:如何从语言中提炼有意义的特征?以及如何在生成式语句中赋予有意义的特征?
知识表示:如何用一种更实用的方法(例如,分层级的,语义网络)给信息排序?
推理:如何通过整合碎片信息形成结论?
规划:如何计划一系列行动,以确保这些行动被执行的同时,能达成特定的目标?
所以这儿我们忍不住用一个更有文化的-或者说更高大上的-方式去定义人工智能。 Astro Teller(现任X,Alphabe’s moonshot factory的首席执行官)在1998年提出:“人工智能是研究如何使机器做他们在电影中干的事情的科学”。
这个定义差不多就是通用人工智能(强AI 或者全AI)和超级人工智能的概念,这些所谓智能的例子在科幻小说里非常多。小说里总会说这个通用系统将会达到或者超过人类的能力- 也就是说,人工智能将会整合我们刚才列出的全部功能。
现在人工智能评论员们中最流行的活动之一是试图猜测天网(电影终结者里的人工智能防御系统)何时被取代。如果你注意到针对通用人工智能和超级人工智能的各种预测存在着巨大差别,也会由衷地觉得很难定论这些预测是高估还是低估人工智能,而且这种水平的机器智能是否可以做到。
AI的主要研究方法
从上个世纪50年代开始,人工智能一般采用两种方法进行研究:

第一种方法是首先制定规则,然后通过阶梯树解决问题。人工智能的先驱们,很多是逻辑学家,他们很喜欢这种方法。这种方法在上个世纪八十年代随着专家系统的诞生达到顶峰,例如,系统把从有机化学专家那儿获得的知识库和决策引擎封装在程序中,就能帮助化学家们识别不知名的分子。
问题是这样的系统在开发一个新模型的时候,你必须从头开始-那些手写的,具体的规则本身就非常困难,或者最后就不可能归纳起来运用在不同问题之间,例如语音识别的规则很难用在医学诊断上。
第二种方法是建立一个通用模型,这种方法只需要通过提供数据调整模型参数即可,是近期最受欢迎的方法。
有些模型与统计学方法相当接近,但最有名的那些模型是受神经科学启发而建立的,即人工神经网络。这种人工神经网络都有一个共有的通用方法:
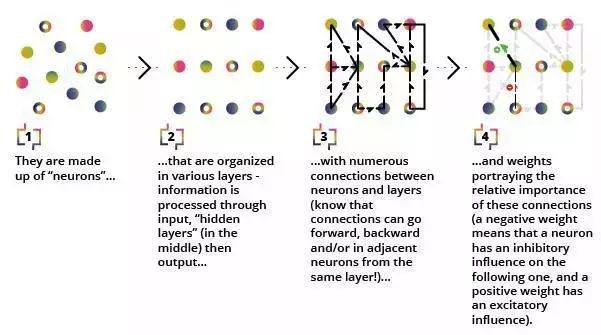
图译
1、它们由神经元构成
2、它们被组织在不同的层里,信息通过输入层,“隐藏层”(由于在中间),然后到达输出层
3、神经元和层之间存在数量巨大的连接(这些连接可能是向前的、向后的,甚至同一层内相邻的神经元之间也会存在连接)
4、这些连接代表了权重,表示某一个连接两端神经元的相对重要性,负权重代表一个神经元对另一个神经元存在抑制作用,正权重代表一个神经元对另一个神经元存在刺激作用。
目前火爆的深度学习,估计大家现在都有所耳闻。深度学习就是一种由大量的层组成的上述类型的人工神经网络 – 因此很“深”, 它在图像目标识别中取得了相当好的成果。
另外,机器学习模型分为三类,都是可能会遇到的:
有监督学习:给模型输入标识过的数据 – 例如一个典型的猫的图片,这张图片带着一个“猫”的标签。
无监督学习:给模型输入未标识的数据,靠它自己进行模式识别。因为数据经常不会被标识 – 想想所有堆积在你智能手机里的照片-并且标识过程很花时间,所以无监督学习方法虽然更难并且不够完善,但是看起来比有监督学习更有前景。
增强学习:每次模型迭代后,你都会给它一个评级。举一个DeepMind的例子,它训练了一个玩古老的雅达利游戏的模型,模型里的等级是游戏显示的分数,模型渐渐地学会了如何获得最多的分数。增强学习方法可能是三种方式中最不完善的,但是最近DeepMind算法的成功已经清楚地表明在增强学习上的努力获得了丰硕回报。
人工智能不是一棵树。而是一片灌木丛!
所以,当把人工智能解决的问题结合在一起时,会发现它是随着各种学派而变化的,这些学派还有自己的分支,有不同的目标和受到不同来源的启发……这样大概就能理解为什么想把这个领域的研究做个完美分类总是有问题的。请看下图 – 看出来问题了吗?
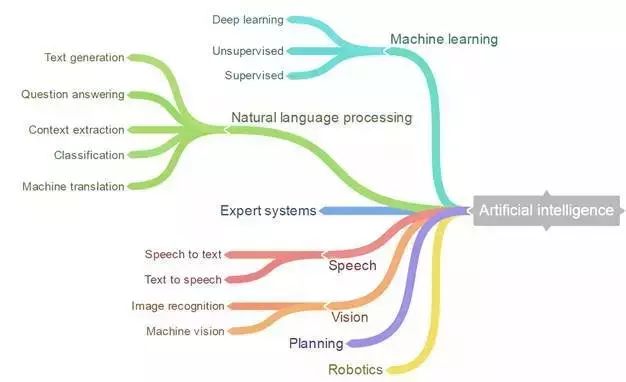
把“机器学习”和“语音”放在同一个层次是不准确的,因为你能用机器学习模型解决语音问题 – 他们不是并行的分支,但是,其他更加不同的分类更让人纠结。
因此,人工智能领域的难与美之处就在于它肯定不是一棵有序的树,而是一片灌木丛。一个分支的成长比另一个快,就会进入大家的视野,然后又轮到另一个分支发生类似的情况等等。有些分支会产生交叉,另一些不会,一些分支被淘汰,又有新的出现。
因此最核心的一条建议是:永远别忘了大方向和重点,否则你就会迷失!

方芳,甲骨文公司研发中心,爱科技,善学习,喜欢一切有科幻色彩的新事物。一路从传统ERP、数据仓库转战大数据,对大数据的技术和应用有无穷的好奇心和关注,愿意作为数据派志愿者为大家提供大数据的有趣知识。

冯羽,算法工程师。负责设计个人或企业信用风险评估算法、市场风险评估算法、仿真优化算法等。数据派志愿者。
翻译组招募信息
工作内容:需要一颗细致的心,将选取好的外文文章翻译成流畅的中文。如果你是数据科学/统计学/计算机类的留学生,或在海外从事相关工作,或对自己外语水平有信心的朋友欢迎加入翻译小组。
你能得到:定期的翻译培训提高志愿者的翻译水平,提高对于数据科学前沿的认知,海外的朋友可以和国内技术应用发展保持联系,THU数据派产学研的背景为志愿者带来好的发展机遇。
其他福利:来自于名企的数据科学工作者,北大清华以及海外等名校学生他们都将成为你在翻译小组的伙伴。
点击文末“阅读原文”加入数据派团队~
转载须知
如需转载,请在开篇显著位置注明作者和出处(转自:数据派ID:datapi),并在文章结尾放置数据派醒目二维码。有原创标识文章,请发送【文章名称-待授权公众号名称及ID】至联系邮箱,申请白名单授权并按要求编辑。
发布后请将链接反馈至联系邮箱(见下方)。未经许可的转载以及改编者,我们将依法追究其法律责任。

点击“阅读原文”拥抱组织
