




测试新模型
从上篇文章,我们知道了在规范模型中PowerBI是如何处理多对多模型的。那现在我们看看新模型是如何处理多对多关系及性能如何。新模型如下图:
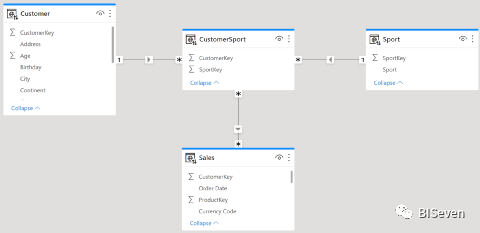
模型中不存在双向关系,Customer表通过CustomerSport表关联到Sales表上。
我们首先执行下述查询:
EVALUATESUMMARIZECOLUMNS (Sport[Sport],"Amt", [Sales Amount])
结果如下:
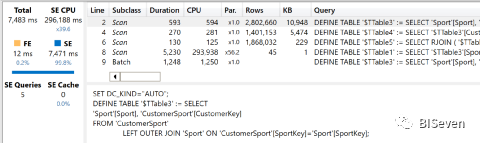
整个查询在存储引擎中解析。在单个核心上运行一些查询,主查询实现了非常好的并行度。总的来说,其时间非常接近于我们使用规范模型实现的时间。
由于关系的布局不同,因此查询计划也与使用规范模型获得的计划略有不同——尽管总体逻辑非常接近。让我们看看存储引擎的查询:
---- Here we retrieve Sport and CustomerKey scanning CustomerSport--DEFINE TABLE '$TTable3' :=SELECT'Sport'[Sport],'CustomerSport'[CustomerKey]FROM'CustomerSport'LEFT OUTER JOIN 'Sport'ON 'CustomerSport'[SportKey]='Sport'[SportKey];---- Here we retrieve CustomerKey only from Table3, which is derived from CustomerSport--DEFINE TABLE '$TTable4' :=SELECT'$TTable3'[CustomerSport$CustomerKey]FROM'$TTable3';---- Table5 contains the values of CustomerKey that are present in Sales, it will-- be used later to reduce the scanning of Sales--DEFINE TABLE '$TTable5' :=SELECTRJOIN ( '$TTable4'[CustomerSport$CustomerKey] )FROM '$TTable4'REVERSE BITMAP JOIN 'Sales'ON '$TTable4'[CustomerSport$CustomerKey]='Sales'[CustomerKey];---- In this final query, Table5 is used to reduce the scanning of Sales to retrieve-- the final result--DEFINE TABLE '$TTable1' :=SELECT'$TTable3'[Sport$Sport],SUM ( '$TTable2'[$Measure0] )FROM'$TTable2'INNER JOIN '$TTable3'ON '$TTable2'[Sales$CustomerKey]='$TTable3'[CustomerSport$CustomerKey]REDUCED BY'$TTable2' :=WITH $Expr0 := 'Sales'[Quantity] * 'Sales'[Net Price]SELECT'Sales'[CustomerKey],SUM ( @$Expr0 )FROM'Sales'WHERE'Sales'[CustomerKey] ININDEX '$TTable5'[$SemijoinProjection];
正如您所看到的,尽管存储引擎查询的数量不同,但总体逻辑与规范模型相同。物理查询计划最终证明了这些计划几乎是相同的,并且整个工作都是在存储引擎中完成的。

继续执行第二段查询:
EVALUATESUMMARIZECOLUMNS (Customer[Continent],Sport[Sport],"Amt", [Sales Amount])
在这里,我们可以理解规范模型和新模型之间的第一个重要区别。在这个场景中,规范模型大量使用公式引擎,因为它不依赖于前面查询中使用的方法。事实上,客户和销售之间的关系与运动和客户之间的关系并不相同。
在新模型中,客户和运动与CustomerSport使用相同类型的关系进行关联。因此,内部查询的时间和格式与前一个模型中观察到的非常接近。
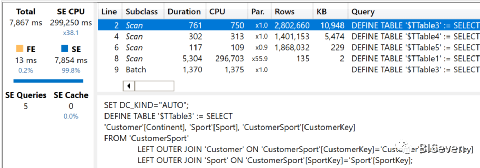
此查询的注意事项与上一个模型相同。几乎没有使用公式引擎:整个查询都在存储引擎中执行。这与规范模型上的查询不同。
在规范模型中,添加客户表导致性能严重下降,公式引擎的使用率更高。在新模型中,添加更多过滤器不是问题。关于这一点,新模型的性能明显更好。让我们看一下存储引擎查询的详细信息,以便更好地了解:
--
-- Here we retrieve Sport, Continent and CustomerKey scanning CustomerSport--DEFINE TABLE '$TTable3' :=SELECT'Customer'[Continent],'Sport'[Sport],'CustomerSport'[CustomerKey]FROM'CustomerSport'LEFT OUTER JOIN 'Customer'ON 'CustomerSport'[CustomerKey]='Customer'[CustomerKey]LEFT OUTER JOIN 'Sport'ON 'CustomerSport'[SportKey]='Sport'[SportKey];---- Here we retrieve CustomerKey only from Table3, which is derived from CustomerSport--DEFINE TABLE '$TTable4' :=SELECT'$TTable3'[CustomerSport$CustomerKey]FROM'$TTable3';---- Table5 contains the values of CustomerKey that are present in Sales, it will-- be used later to reduce the scanning of Sales--DEFINE TABLE '$TTable5' :=SELECTRJOIN ( '$TTable4'[CustomerSport$CustomerKey] )FROM'$TTable4' REVERSE BITMAP JOIN 'Sales'ON '$TTable4'[CustomerSport$CustomerKey]='Sales'[CustomerKey];---- In this final query, Table5 is used to reduce the scanning of Sales to retrieve-- the final result--DEFINE TABLE '$TTable1' :=SELECT'$TTable3'[Customer$Continent],'$TTable3'[Sport$Sport],SUM ( '$TTable2'[$Measure0] )FROM'$TTable2'INNER JOIN '$TTable3'ON '$TTable2'[Sales$CustomerKey]='$TTable3'[CustomerSport$CustomerKey]REDUCED BY'$TTable2' :=WITH $Expr0 := 'Sales'[Quantity] * 'Sales'[Net Price]SELECT'Sales'[CustomerKey],SUM ( @$Expr0 )FROM'Sales'WHERE'Sales'[CustomerKey] ININDEX '$TTable5'[$SemijoinProjection];
如您所见,除了在查询中使用的列中存在一些差异外,整个结构与前一个模型中的结构相同。查询计划同样相同。

在第二个查询中,新模型的性能优于规范模型。这已经非常有趣了,因为它表明,根据您计划在模型上执行的查询类型,一个模型的性能优于另一个。
不幸的是,新模型在第三个查询上存在缺陷——该查询使用对客户表的筛选来达到筛选销售的目的。在规范模型中,客户和销售之间的关系是直接的。因此,整个查询是使用单个xmSQL查询执行的,该查询的性能非常好:
EVALUATESUMMARIZECOLUMNS (Customer[Continent],"Amt", [Sales Amount])
在新模型中,引擎仍需要通过CustomerSport才能实现筛选销售表的目的。因此,第三个查询的运行速度几乎与前两个查询相同,因此该模型失去了优势。以下的消耗时间:
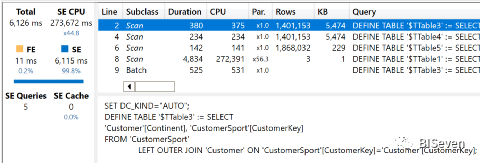
由于大洲包含的值比较少,而且并非所有客户都玩所有的运动,因此查询使用的数据结构稍小,执行时间稍短。总的来说,存储引擎查询的格式与前两个相同,这里就不再重复了。
在第三种情况下,模型的性能比规范模型的性能差得多。同样,这是一个有趣的结果,因为它表明您需要根据执行的查询类型进行选择。如果您在大多数情况下不使用客户表与运动表之间的多对多关系,并且在大多数计算中更依赖客户表与销售表之间的直接关系,那么规范模型的性能会更好。另一方面,如果多对多结构始终是查询的一部分,那么新模型具有有趣的优势。
结论
我们对这两个模型的一些查询进行了详细分析,试图找到最好的模型。最终的结论是,这要视情况而定,这在数据模型领域几乎总是如此。
当很少使用多对多关系时,规范模型是一个很好的选择。当您通过客户表使用桥接表时,您会付出高昂的代价,因为将来自多端的双向筛选关系与其他关系混合在一起会产生较差的查询计划。当桥接表不是公式的一部分时,正则模型的速度要快得多。然而,当使用桥接表时,规范模型的速度较慢,并且它使用了相当多的公式引擎。因此,您观察到查询的速度变化很大,这取决于您是否遍历桥接表。
新模型的整体性能更稳定。桥接表始终是查询的一部分,但常规关系与有限的多对多基数关系的组合会产生始终显示相同性能级别的查询计划。无论用于过滤的维度如何,性能都会有损失。这意味着您永远不会享受到客户表和销售表之间的直接关联的出色性能,因为客户表能够筛选销售表的唯一途径是通过:CustomerSport。
通常情况下,选择取决于模型的具体情况。在选择规范模型还是新模型时,您应该仔细评估将要执行的查询,并根据用户需求做出明智的选择。对于极端优化场景,也可以在模型中保留这两组关系,并通过使用IF条件和交叉过滤器和用户关系修饰符编写代码,以便根据执行的查询选择最佳关系布局。同样,这不是一种建议的技术:更改关系布局会对性能产生另一种影响,并且会禁用一些优化。尽管如此,当您努力实现极端优化时,这是一种值得尝试的技术
参考:
Different options to model many-to-many relationships in Power BI and Tabular - SQLBI
