




翻译自SQLBI
这篇文章很长,所以会分两次进行翻译。原文链接如下:
https://www.sqlbi.com/articles/different-options-to-model-many-to-many-relationships-in-power-bi-and-tabular/
我们的读者知道SQLBI对双向关系的看法:它是一种强大的工具,在大多数情况下都应该小心使用并避免使用。实际上有一种情况下双向关系很有用的:当您需要创建一个模型,其中涉及维之间的多对多关系时。在此场景中,建议使用双向过滤器关系。然而,不能建立双向关系的原因之一可能是模棱两可。如果您面临这种情况,您可以使用基于有限的多对多基数关系的建模技术,即将其
设置为单向关系,这种方法也可以工作。在这两种模式之间做出选择并不容易。两者都有各自的优点和缺点,为了做出正确的决定,我们需要深入了解这些优点和缺点。
在本文中,我们首先对这两种技术进行描述,然后对这两种解决方案进行性能分析,以便决定关于何时使用哪种技术。
场景
在Contoso数据库中,并不存在多对多关系。因此,我们在Customer和Sport表之间创建了多对多关系。我们给每个人分配了一定数量的运动项目。因为每个人可以进行多个运动,而且每个运动可以由多人进行,所以客户与运动之间的自然关系是多对多关系。
对这种关系建模的规范方法如下所示:
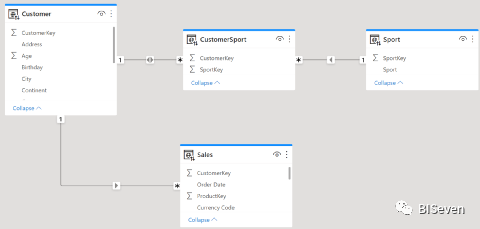
Filter从Sport表传递到CustomerSport,然后通过双向关系到customer ,最后传递到Sales表。
通过使用此模型,你可以通过Port切片Sales表,从而获得这种多对多的行为。这是我们多年来教授的多对多的关系。
我们最近讨论了通过使用多对多关系完成该模型:
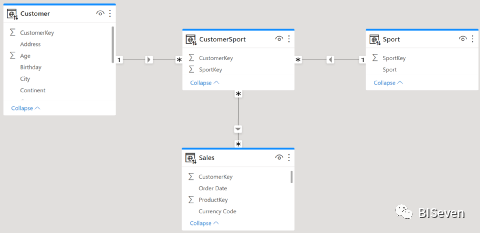
第二个模型在视觉上更吸引人,它没有双向关系——这是最重要的。来自Customer或Sport的Filter首先应用于CustomerSport,然后通过多对多交叉过滤器关系传递到Sales。
由于该模型中不存在双向关系,因此该模型必然比之前的模型更加灵活。也就是说,在性能方面,它是否也更好或至少可以与之媲美?不幸的是,快速的答案是“视情况而定”。第二个模型生成不同的查询计划,这些计划在某些场景中可能更好,但在其他场景中可能不那么好。这完全取决于特定查询中涉及的表。因此,在将新模型转移到生产环境之前,应该对其进行全面测试。
为了证明上述说法,我们显然需要进行测试。在讨论测试的细节之前,我们先来看看一些注意事项。为了区分这两个模型,我们称第一个模型为“规范”模型,而提出的第二个模型为“新”模型。
规范多对多关系的缺点是双向关系。从建模的角度来看,这是一个弱点,因为它可能会引入歧义。从性能的角度来看,这也是一个弱点,因为将一个Filter从多端传输到单边总是比反向传输更慢。
新的解决方案不具有双向关系,但也存在两个弱点。首先,CustomerSport和Sales之间的关系是一个有限的关系。从性能上看,有限的关系是缓慢的,因为它们没有被具体化。我们应该衡量的是双向关系是否比多对多基数关系慢。但还有另一个问题。在规范模型中,Customer通过一个规则的1:M关系直接链接到Sales。在新的模型中,Customer仅通过桥接表链接到Sales。这意味着,只要用户按Customer或Sport的属性切片,引擎就会遍历多对多关系。在规范模型中,如果用户按客户进行浏览,那么桥接表就不是这个游戏中的一部分。在新的模型中,桥接表总是起着重要的作用。在新的模型中,按用户浏览的用户运行一个查询,该查询总是使用CustomerSport过滤Sales。这个重要的细节是新模型的最薄弱之处,我们将通过查询进一步分析。
测试性能
到目前为止,上述的注意事项对于定义要执行的测试是有用的。我们将检查计算Sales Amount(扫描Sales表的度量值)在两个场景中按Sport和Customer进行过滤的性能。我们使用的模型是一个有14亿行的Contoso版本。CustomerSport表包含大约300万行:我们创建了一个模型,其中每个客户都在零
项运动和三项不同的运动之间活动。
第一个查询按Sport[Sport]分组,并计算销售额。简单来说,查询需要遍历CustomerSport关系,只
使用Sport表来分组:
EVALUATESUMMARIZECOLUMNS (Sport[Sport],"Amt", [Sales Amount])
为了加深我们对多对多关系计算的理解,我们还分析了第二个稍微复杂一些的查询,该查询按
Sport和Customer进行分组:
EVALUATESUMMARIZECOLUMNS (Customer[Continent],Sport[Sport],"Amt", [Sales Amount])
最后,在最后一个查询中,我们仅根据Customer来分组。在规范模型中,该查询不需要遍历
CustomerSport表。另一方面,在新模型中,由于关系的布局方式,该查询无论如何都需要使用CustomerSport:
EVALUATESUMMARIZECOLUMNS (Customer[Continent],"Amt", [Sales Amount])
测试规范模型
这是一个规范模型,在Customer和CustomerSport之间具有双向关系。
我们计算第一个查询:
EVALUATESUMMARIZECOLUMNS (Sport[Sport],"Amt", [Sales Amount])
首先是执行时间。该查询使用385,984毫秒的存储引擎CPU,只使用少量的公式引擎(10毫秒)。
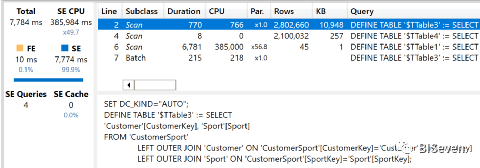
分析查询计划很有意思。在临时表的帮助下,整个计算被下推到存储引擎。以下是细节:
2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 | -- -- First we retrieve the pairs of CustomerKey and Sport from CustomerSport -- DEFINE TABLE '$TTable3' := SELECT 'Customer'[CustomerKey], 'Sport'[Sport] FROM 'CustomerSport' LEFT OUTER JOIN 'Customer' ON 'CustomerSport'[CustomerKey]='Customer'[CustomerKey] LEFT OUTER JOIN 'Sport' ON 'CustomerSport'[SportKey]='Sport'[SportKey];
-- -- Here we extract the CustomerKey values in a bitmap -- DEFINE TABLE '$TTable4' := SELECTSIMPLEINDEXN ( '$TTable3'[Customer$CustomerKey] ) FROM '$TTable3';
-- -- Here is where the actual computation happens. -- Note that the first INNER JOIN is with Table3, to retrieve the Sport -- Table4 is used to further filter the scanning of Sales -- DEFINE TABLE '$TTable1' := SELECT '$TTable3'[Sport$Sport], SUM ( '$TTable2'[$Measure0] ) FROM '$TTable2' INNER JOIN '$TTable3' ON '$TTable2'[Customer$CustomerKey]='$TTable3'[Customer$CustomerKey] REDUCED BY '$TTable2' := WITH $Expr0 := 'Sales'[Quantity] * 'Sales'[Net Price] SELECT 'Customer'[CustomerKey], SUM ( @$Expr0 ) FROM 'Sales' LEFT OUTER JOIN 'Customer' ON 'Sales'[CustomerKey]='Customer'[CustomerKey] WHERE 'Customer'[CustomerKey] ININDEX '$TTable4'[$SemijoinProjection];
|
<https://www.sqlbi.com/articles/different-options-to-model-many-to-many-relationships-in-power-bi-and-tabular/>
引擎执行计算分为三个步骤,对应于三个存储引擎查询:
首先,它从CustomerSport检索SportKey和CustomerKey对。
接下来,它生成一个位图,其中包含CustomerKey值出现在CustomerSport中。这个表将在下一步中使用,用于过滤从Sales。的确,因为我们只对Sport切片感兴趣,没有做任何运动的客户将被忽略。
最后一步是实际计算发生的地方。引擎扫描Sales并只检索CustomerSport中的客户(表2)。它将这个
结果与表3连接起来,表3将客户映射到运动。
尽管这是一个复杂的计划,但是您可以看到整个计算都被推到存储引擎中。尽管如此,存储引擎
本身不能处理双向过滤器,因此它需要准备这些临时表来生成正确的连接。
在物理查询计划中也可以看到整体逻辑。实际上,物理查询计划仅由4行组成,这些行检索与运动
对应的45行,完全由存储引擎计算。

因为整个计算被下推到存储引擎,所以所使用的并行度非常好:它显示了在具有64个虚拟核的机器上的x49.7,进一步证明了该引擎正在最大化地使用CPU能力。
我们用如此多的细节来描述这个计划,因为能够将第一个计划与下面的计划进行比较是很重要的。不同模型上的不同查询的性能有显著差异,细节很重要。
现在让我们将Customer[Continent]添加到查询中。从DAX的角度来看,差别并不复杂:只需在SUMMARIZECOLUMNS组by列表中多一行:
EVALUATESUMMARIZECOLUMNS (Customer[Continent],Sport[Sport],"Amt", [Sales Amount])
尽管非常接近前一个查询,但现在的时间非常不同。
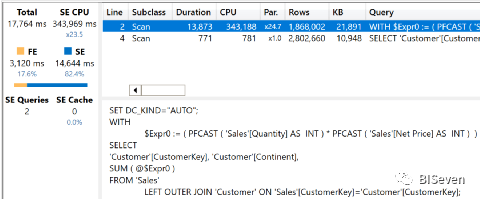
在深入研究细节之前,请注意并行度大大降低了:现在显示的是x23.5,不到之前查询的一半。此外,公式引擎的时间也大大增加:从10毫秒增加到3120毫秒。
为了理解性能下降的原因,我们需要深入研究。这些是存储引擎查询:
--
-- Here we retrieve the Sales Amount for each customer, without reducing the-- set to only the customers being filtered by the CustomerSport table, as it-- happened in the previous query--WITH$Expr0 := 'Sales'[Quantity] * 'Sales'[Net Price]SELECT'Customer'[CustomerKey],'Customer'[Continent],SUM ( @$Expr0 )FROM'Sales'LEFT OUTER JOIN 'Customer'ON 'Sales'[CustomerKey]='Customer'[CustomerKey];---- Here we match CustomerKey values with Customer[Continent] and Sport-- by scanning Customersport, Customer and Sport together--SELECT'Customer'[CustomerKey],'Customer'[Continent],'Sport'[Sport]FROM'CustomerSport'LEFT OUTER JOIN 'Customer'ON 'CustomerSport'[CustomerKey]='Customer'[CustomerKey]LEFT OUTER JOIN 'Sport'ON 'CustomerSport'[SportKey]='Sport'[SportKey];
这一次,存储引擎并不实际计算查询返回的值。它首先检索每个客户键的销售额,然后检索将客户键映射为大洲和运动的另一个表。
存储引擎中没有进一步的计算,这清楚地表明真正的多对多计算是在公式引擎中进行的。因此公式引擎的使用大幅增加。此外,由于计算实际值的将是公式引擎,这意味着需要将包含部分值的数据结构传递回公式引擎。这是两个查询计划之间最大的区别:前一个查询计划在存储引擎中执行其所有计算,而后一个查询计划需要将大量数据移回公式引擎。
您可以通过查看物理查询计划来了解这个“细节”,现在该物理查询计划清楚地表明,包含Continent和Sport(135行)的表与公式引擎中包含CustomerKey Sales Amount(2,802,660行)的更大表相连接。

由于涉及公式引擎,因此与前一个查询计划相比,该查询计划显然是次优的。
当CustomerSport表不是游戏的一部分时,情况就大不相同了。实际上,我们分析的最后一个查询只按客户(大洲)划分销售金额。由于我们布局关系的方式,所以不需要使用CustomerSport表,因为Customer可以将其过滤直接应用到Sales:
EVALUATESUMMARIZECOLUMNS (Customer[Continent],"Amt", [Sales Amount])
服务器返回的时间非常好
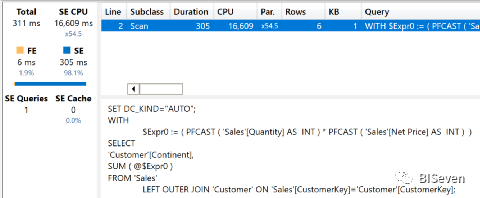
不涉及公式引擎,并行度是令人敬畏的x54.5,整个查询只使用16609毫秒的存储引擎CPU执行。这是可以预期的具有常规一对多关系的DAX的行为。整个计算是由它最好的引擎完成的:存储引擎。
现在我们已经执行并分析了这三个查询,我们可以得出关于规范化模型的结论。当查询只涉及Sport表且计算可以下推到存储引擎时,Tabular会生成一个非常好的查询计划,该计划在最佳状态下使用存储引擎。查询很繁重,但是通过使用不移出VertiPaq的临时表,并行度很好。当查询变得更复杂时,就需要公式引擎——这大大降低了整个查询的速度。如果引擎不使用CustomerSport桥接表,则VertiPaq的性能最佳:不涉及公式引擎,查询甚至不需要临时结构。
敬请期待下篇文章
我是BISeven,欢迎讨论,欢迎关注

