






作者介绍

张宇
张宇,算法工程师,2017 年加入去哪儿网,主要负责信息流推荐搜索、智能客服、图像识别等方向。
1、引言
随着计算机视觉技术的快速发展,在很多任务上,机器已经超越了人眼的准确率,可以替换人工完成目标检测、识别、跟踪、判别等任务。OCR (Optical Character Recognition) 光学字符识别,是让计算机看图识字的技术。例如,上传一张身份证的图像,通过 OCR,可以识别出图像中的身份证信息,如:姓名张三;性别女等信息,这就是 OCR 技术。

通过 OCR 识别,大大提高了我们的效率,让很多工作实现自动化,不再需要人工进行这些重复的工作。OCR 识别在我们的日常生活中已经有很多的应用场景,如:
1. 车牌识别
使用摄像头抓拍汽车的图像,通过目标检测的方法把汽车车牌的部分截取出来,通过 OCR 识别出车辆的车牌号码,可以用在交通卡口、停车场等场景。
2. 卡证识别
将身份证、银行卡、名片、学历证等各种卡证进行拍照,通过 OCR 提取卡证中的文字信息,可以大大简化人工录入的过程,提高录入速度,降低由于人工失误带来的录入错误。
3. 票据识别
将普通发票、小票、火车票等票据通过拍照,通过 OCR 识别票据中的文字信息,使得在 OA 报销系统不再需要人工提交纸质的票据,提升了报销审核的效率。
4. 文档识别
将纸质的文档进行拍照,通过图像识别技术进行版面分析,通过 OCR 将对应版块中的文字进行提取识别,可以进行文档重建等任务。
2、OCR 识别常用方法
从 1929 年德国科学家 Tausheck 提出 OCR 技术开始,人类就开始对 OCR 的研究探索,希望能让计算机识别图像中的文字。在 1966 年,IBM 公司的 Casey 和 Nagy 采用了模板匹配法识别了 1000 个印刷体汉字,这是世界上最早的汉字 OCR 识别方法。之后,中国也进入了 OCR 的研究领域,20 世纪 90 年代,慢慢由实验室走向商业市场,比较优秀的有汉王、清华 OCR 等。
随着互联网的快速发展,各家互联网公司都积累了大量的现实场景图像数据,对这些图像中的文字进行识别以服务各种应用场景,已经成为 OCR 识别的主流任务。相比于印刷场景文字识别,将面临更多挑战:
1. 图像背景复杂:现实场景图像中包含的信息丰富、色彩多样、无规则布局。
2. 识别文字复杂:文字有不同字体、不同大小、不同展示方式。
目前 OCR 识别技术,大体可以分为三个步骤:图像预处理、文本检测、文本识别。
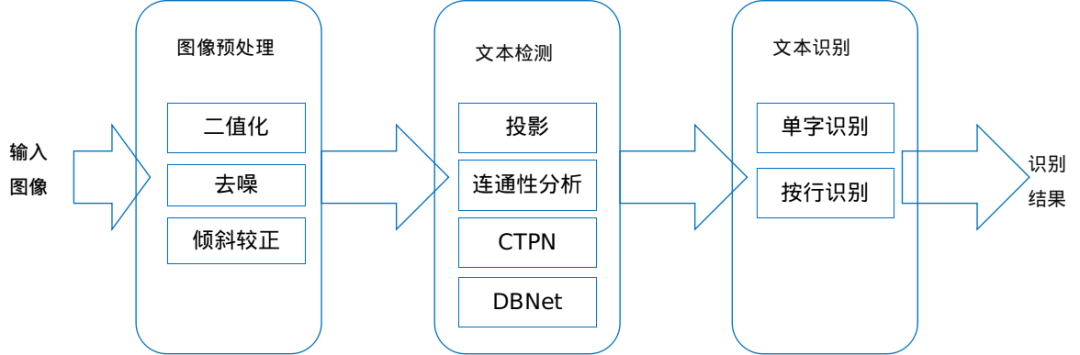
图像预处理:在进行 OCR 之前,先对图像进行预处理操作,如去除图像中的噪声、对于倾斜的图像做校正、图像二值化等操作。
文本检测:通过传统 CV 或者深度学习的方法,检测提取图像中的文本,标记文本所在的位置。
文本识别:根据检测提取的文本在图像中的位置,将文本从图像中切出来,进行识别的过程。
对于文本检测或文本识别的技术,又可以分为传统 CV 方法和深度学习的方法。下面通过一些示例来介绍传统 OCR 与深度学习 OCR 的适用场景及效果对比。
2.1 传统 OCR
使用传统 CV 的方法进行文本检测,可以使用投影、连通性分析、MSER 等方法,但这些传统 CV 的方法需要大量的先验规则,只适用于一些背景简单、布局规则的场景。
2.1.1 投影
先介绍两个概念:二值化和投影。
二值化:将图像上的像素点的灰度值通过卡一个阈值设置为 0 或 255 ,0 是黑色,255 是白色,处理后的图像呈现出黑白的效果。
投影:形象的理解就是通过一束光对物体照射后留下的阴影,对于二值化图像,水平的投影就是每行的非零像素值的个数,垂直投影就是对每列图像数据中非零像素值的个数。

输入图像是一张超市小票,先通过二值化,将图像中的灰度值设置为 0 或者 255,再对图像进行水平投影,然后将投影部分进行提取,就得到了文本行所在的位置区域。但使用投影法提取文本行,有一定的局限性,就是图像中的文本行必须是非常标准的一行一行的,对于一些布局复杂的图像,投影之后得到的区域,可能会包含多行的情况,就无法提取到文本行。对于这种图像,可以尝试使用连通性分析来提取。
2.1.2 连通性分析
先介绍两个概念:膨胀、连通性分析。
膨胀:形态学图像处理的一种方式,就是将图像的边缘扩大些,作用就是将目标的边缘或者是内部的坑填掉。
连通性分析:简单的理解,就是判断一个像素点与周围的点的灰度值是否相同,如果相同,就可以连成一片。

还是上面那张超市的小票,区别在于图像的右下角多了一个“测”字,我们来模拟复杂排版的场景。将输入图像进行膨胀处理,使文字内部连成一片,然后进行二值化、连通域分析,就得到了文字的轮廓,再进行后处理,就提取到了文本行区域。这种方法的局限性在于图像的背景和文字必须是简单的,可以通过二值化进行分离。但对于一些背景与文字复杂的,就无能为力了,需要尝试使用其它方法,比如 MSER。
总而言之,传统的 CV 方法局限性比较多,需要根据不同的场景尝试使用不同的方法。复杂多变的背景与文字,给传统 OCR 带来了极大的挑战。
2.2 深度学习 OCR
从 2012 年 Hinton 通过 AlexNet 网络获取 ImageNet 竞赛冠军开始,深度学习在 CV 领域的各种任务上,都表现出极佳的效果。从此,使用 CNN 成为图像识别的首选方案。而对于 OCR 领域,深度学习方法可以从基于 Anchor 的 CTPN 的文本检测模型开始,到端到端的文本识别模型 CRNN,无论是效果、鲁棒性、还是通用性,深度学习的 OCR 方法以绝对的优势战胜了传统 CV 方法。
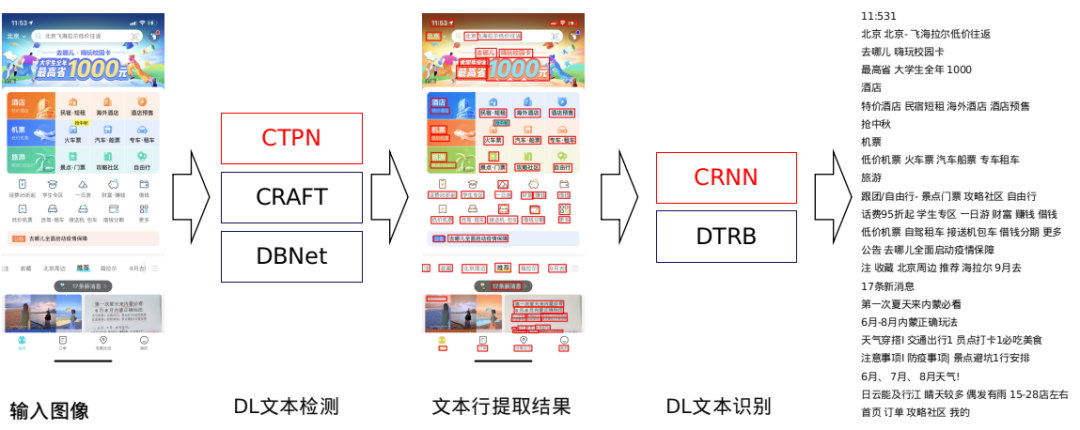
输入图像是一张 qunar app 的首页截屏,背景与文字都非常复杂,使用深度学习的文本检测与识别方法,可以得到非常准确的结果。
3. 深度学习文本检测与文本识别
3.1 文本检测 CTPN
文本检测,就是将图像中的文本所在的位置标记出来,这是一种跟目标检测非常相似的任务,是否可以把文本检测任务当成单一的目标检测呢?

上图左边是使用目标检测 Faster RCNN 的检测结果,很明显能看出,检测框标记的不太准确。右边是使用文本检测 CTPN 的方法,检测出来的框比较准确。究其原因,是因为目标检测 Faster RCNN 没有考虑文本的一些特点:
1. 文本长度不固定,文本可以是很短的,也是可以很长的。
2. 文本一般是以长矩形的形式存在。
3. 文本行中每个字中间会有小间隔。
基于上面这些问题,CTPN 提取了将文本检测的任务进行拆分,有点像“分治法”的方法,不再是大文本框一次性预测整行文本,而是将大文本框拆分成宽度为 16px 的小文本框,然后将所有的小文本框进行拼接和后处理,合并成最终的大文本框。这样就解决了文本长度不固定的问题。由于使用了固定宽度,模型在训练的时候不再需要学习小文本框的宽度,只学习小文本框的中心点在Y轴的偏移量和小文本框的高度。而对于文字以及拆分后的小文本框,都可以看成是一个序列,CTPN 引入了 BLSTM 来提取序列特征,这样大大提升了文本检测的准确率。
3.1.1 CTPN 网络结构
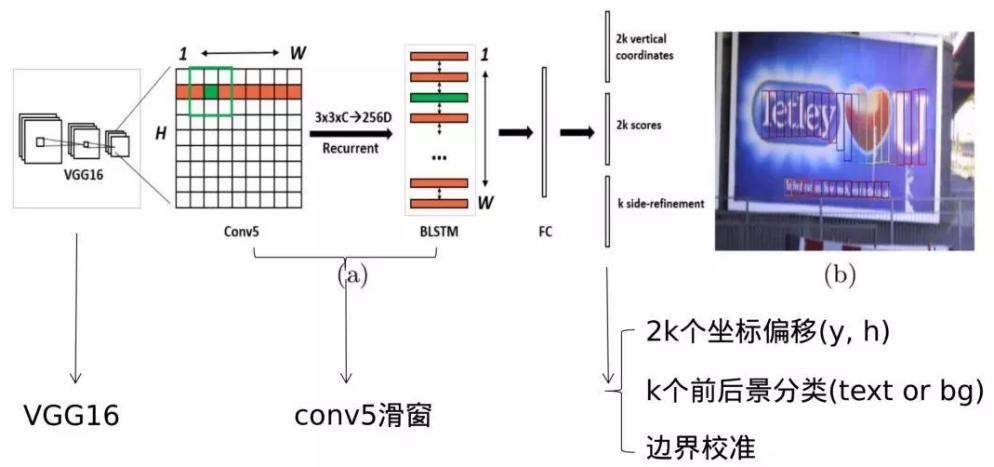
CTPN 的网络结构可以分成三个部分:
1. 提取图像特征的 backbone,如 VGG16。
2. 一个 3*3 卷积核的卷积和一个双向的 LSTM。
3. 全连接之后的预测部分有三个任务,文本框竖起方向的两个坐标偏移量、前后景(文本或背景)分类概率、最后文本框边界校准偏移量。
3.1.2 CTPN 模型训练
1. 切分 groundtruth
在模型训练的时候,CTPN 会将标注好的 groundtruth 切分成固定宽度为 16px 的小框,作为新的 groundtruth。
2. 提取空间+序列特征
图像先经过 VGG16 的 backbone 提取特征,然后经过 3*3 的卷积和双向的 LSTM,再经过一个全连接,这样,就提取到了空间+序列特征。
3. RPN 网络
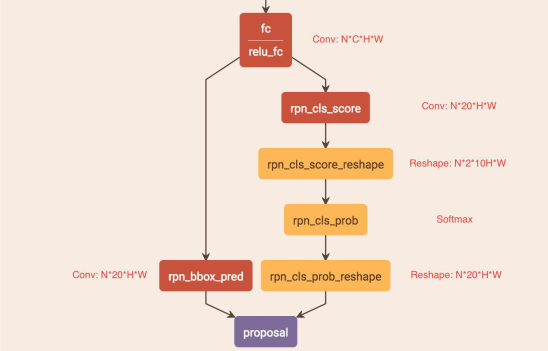
这里的 RPN 网络是与 Faster R-CNN 的类似,分成两个部分:
(1) 左边的是用来回归文本框竖直方向的两个偏移量。CTPN 将大的文本框切分成了固定 16px 的小框,所以只回归竖直方向文本框的高度与中心点Y轴的偏移量这两个值。由于在 FC Feature Map 的每个点都预置了 10 个不同高度的文本框,所以,RPN_bboxp_red 有20 个 Channels。
(2) 右边分支是 Softmax 分类,用来判断锚框是文本或背景的概率。
4. loss function
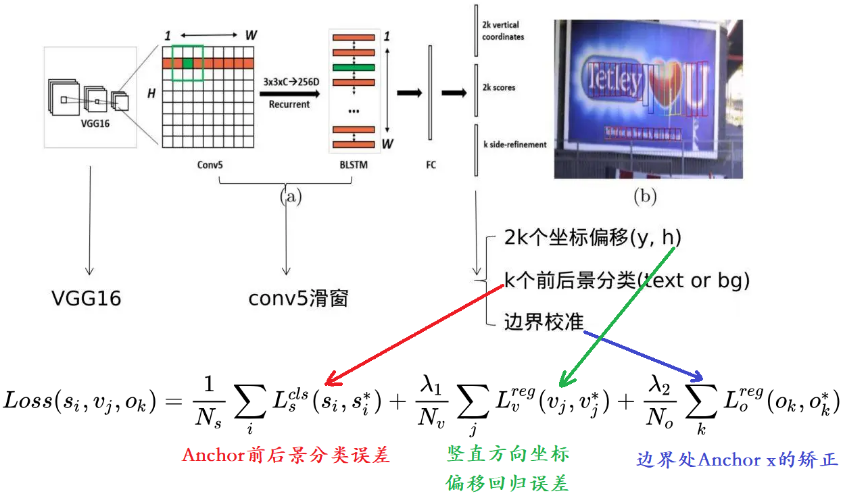
CTPN 的损失函数包括三个部分,将这三个部分加起来就是整体的损失。
1. 锚框里是否是文本的分类误差。
2. 锚框竖直方向两个偏移量的误差。
3. 最终的文本框边界矫正的误差。
4. NMS
通过 CTPN 网络的前向运算之后,会有大量的文本框保留下来,需要使用 NMS (非极大值抑制)将 RPN 网络输出的重合的锚框过滤掉,同一位置只保留概率最大的。
5. 文本区域构造
将得到的一连串锚框,通过文本线构造方法,就得到了最终的文本检测框。

3.2 文本识别 CRNN
文本识别,是通过文本检测得到的文本在图像中的位置,然后对文本进行识别的过程。在传统 CV 阶段,常规的做法是将字符切出来,训练一个多分类模型进行单字符的识别。这种方法在准备训练数据的时候会非常复杂,需要进行字符切分。在进入深度学习阶段,出现了 CTC,可以解决序列数据对齐的问题,这样就可以完成端到端的模型训练。
3.2.1 CRNN 网络结构
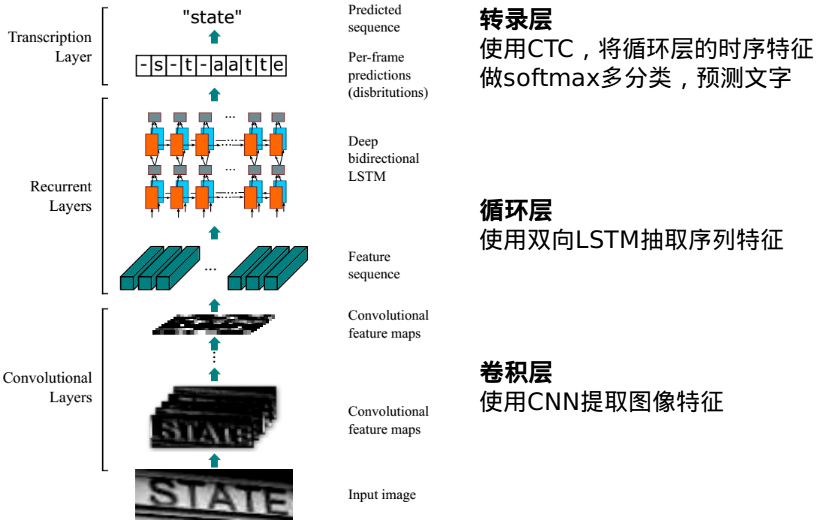
卷积层:使用深度 CNN,对输入图像提取特征,得到特征图。
循环层:使用双向 RNN(BLSTM) 对特征序列进行预测,对序列中的每个特征向量进行学习,并输出预测标签(真实值)分布。
转录层:使用 CTC 损失,把从循环层获取的一系列标签分布转换成最终的标签序列。
3.2.2 CTC 损失
对于 CRNN 中,最关键的一个过程,就是转录层。将 BLSTM 对每个特征向量所做的预测转换成标签序列的过程。这也是端到端 OCR 识别的难点,如何解决不定长序列的对齐问题,而这个问题在语音识别中也是存在的,由于不同的人语速不一样,每个音符的时长不一样,也存在对齐的问题。CTC 的出现,使得这种序列预测任务不再需要做数据对齐,可以实现端到端的模型训练,大大减少了模型标注的难度。
3.2.2.1 预测序列合并
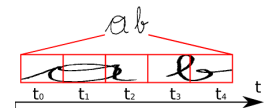
上面这个文本 ab,LSTM 输出有 5 个时间步,理想情况下是"aaabb",将重合的合并之后就是"ab",但存在 book、hello 这样的情况,所以CTC增加了一个 blank 机制解决这个问题。即对字符序列先删除重复的,有 blank"-" 的,则保留。这样就解决了重复的问题。
3.2.2.2 CTC 训练
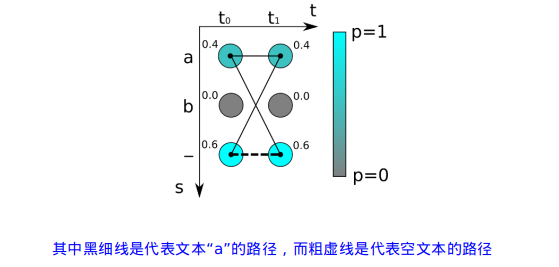
如上图,有两个时间步长,t0 和 t1,可能的字符有"a"、"b"、"-",我们得到两个概率分布向量,如果采用最大概率路径解码的方法。则"--"的概率最大,其值为:0.6*0.6 =0.36。但输出字符为"a"有多种组合情况,"aa"、"a-"、"-a",其中"-"为占位符。故输出字符为"a"的概率应该是三种组合之和:0.4 * 0.4 + 0.4 * 0.6 + 0.6 * 0.4 = 0.16 + 0.24 + 0.24 = 0.64。所以,"a"的概率是最大的。
对于循环层输出的概率分布,y={y1,y2,...,yT},T是序列长度,最后映射为标签文本l的总概率为:
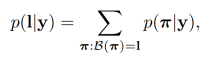
我们的目标就是训练网络使这个概率最大化,从而通过反向传播,更新网络参数。
4. OCR 在 qunar 的应用落地
4.1 酒店 List 页比价 OCR 识别
4.1.1 背景
随着移动互联网的发展,拍照设备已经成为手机最标配的功能,而通过图像查找自己想要的东西,相比于文本,更加直观、方便快捷,各大电商也都上线了以图搜物的功能。通过图像查找内容,正在得到越来越多的用户青睐。在我们酒店预定场景中,通过对用户调研发现,大量的用户在下单前会发生比价行为,而从用户的搜索词分析,酒店信息的 query 词占比非常高,并且各大竞品都不允许用户直接复制酒店名,这就导致用户要完成比价,需要手动输入酒店名或关键字才能完成。为了给用户提供更便捷的比价服务,允许用户上传一张其它 APP 酒店 List 页的图像,我们通过分析识别图像里的文字,获取用户想要比价的酒店及价格,然后完成跟我们对应酒店的比价操作。
4.1.2 挑战
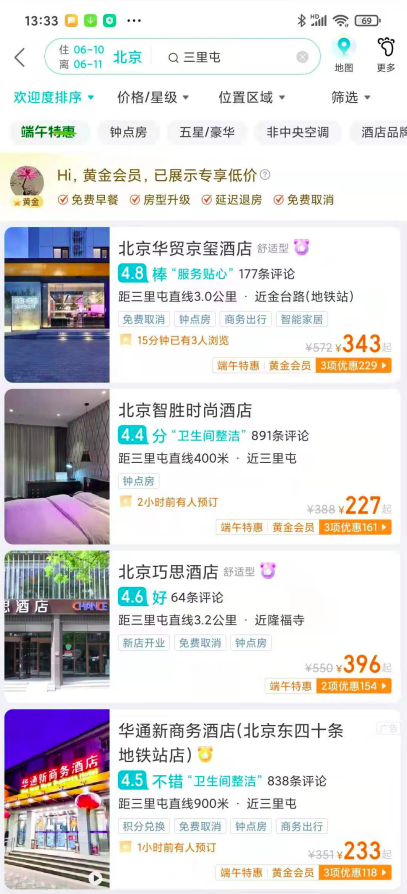
要实现通过图像比价的功能,有两个重要环节,即识别图像中的文字和解析其中的酒店名、价格,由于酒店 List 页的图像相比于普通文档更加复杂,给我们带来了极大的挑战。
4.1.2.1 酒店名包含生僻字和繁体字
为了酒店更具特色有吸引力,各家酒店在酒店名上下了很大的功夫,这就导致酒店名中包含了一些生僻字和繁体字,这些字在我们常用的字符集中是没有的,如何构建一个覆盖很高的字符集是我们需要解决的问题。
4.1.2.2 文字样式复杂
相比于普通文档图像,APP 界面排版复杂、字体样式、大小、颜色丰富,给文字识别带来一定的困难。
4.1.2.3 识别结果结构化困难
图像 OCR 识别之后会将图像中所有的文字全部提取出来,这里面除了我们想要的酒店名和价格,还包含了其它一些我们用不到的信息。想要从一堆文字中解析得到酒店名和价格,常用的方法是字符串匹配或者 NLP 文本分类,但这些方法在兼容性或准确率都存在一些问题。
4.1.2.4 遮挡导致文字识别错误
用户上传的图像中,存在一些酒店名、酒店价格显示不全或被其它物体遮挡的情况,这些都将影响到识别的准确率。
4.1.3 解决方案
4.1.3.1 构建更全面的字符集
一个 OCR 识别模型的字符集决定了这个模型能够识别的字符个数的上限,为了能构建一个覆盖更加全面的字符集,我们对 Qunar 酒店基本信息表中所有的酒店名做了聚合去重,有 1W+ 个不同的字符,使用这个字符集跟我们原来的字符集进行合并去重之后,有 1.2W+ 个字符,下面是部分字符集的展示:

4.1.3.2 生成丰富的训练样本
不同 APP 的酒店 List 页使用的字体、字号、颜色、排版不同,为了识别模型的鲁棒性更好,我们收集了常用字体宋体、微软雅黑、仿宋、黑体、方正姚体、华文行楷、楷体、方正舒体、幼圆、华文中宋、隶书、黑体等三十多种字体,基于我们最新构建的字符集,使用随机的字号、颜色,生成 100W 左右的训练集,如:

有了训练集,我们就可以训练 CRNN 识别模型来识别图像中的文字,下面是识别效果:
4.1.3.3 识别结果结构化
对于上面的 OCR 识别结果,我们想要直接抽取出酒店名和酒店价格还是比较困难的,那么我们是否可以从图像的角度解决这个问题。通过对各 APP 酒店 List 页的分析发现,酒店的 List 页在布局上有一定规律的,每个酒店区域的边境非常清晰,酒店区域内的排版有一定的规则,最上方是酒店名,右下角是酒店的价格。这样,我们就可以使用目标检测的方法,把酒店区域以及酒店名和酒店价格检测出来,然后对酒店名和酒店价格进行文字识别,就得到了我们想提取的内容。
4.1.3.4 过滤展示不完整的酒店
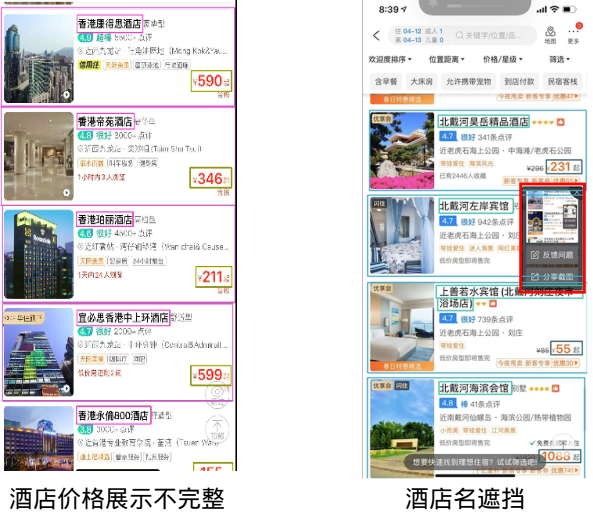
对于展示不完整,导致识别错误,我们可以先判断这个酒店区域是否是一个完整的区域,如果不是则丢弃,不再识别其中的酒店名和价格。而由于遮挡造成的不准确问题,我们是把遮挡区域进行了识别,如果遮挡区域与酒店区域的酒店名或价格重合,则也对此酒店区域进行丢弃。
4.1.4 结果展示与评估
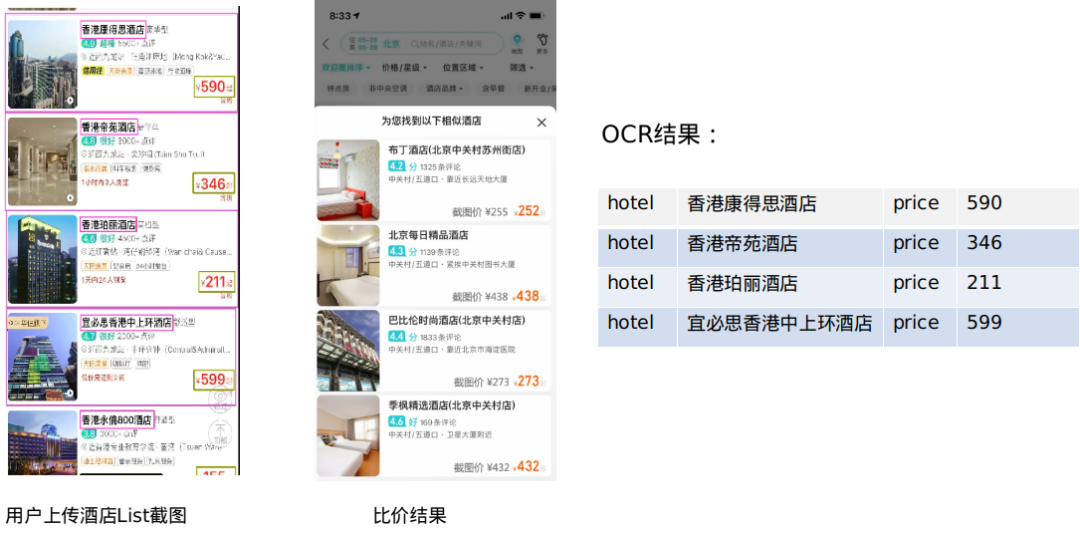
对于 OCR 识别结果的评估,通用 OCR 一般采用字符准确率作为评估指标。比如整个图像中有 100 个字,其中有 4 个字识别错误,那么字符准确率为 (100-4)/100=0.96,看上去是一个还比较不错的结果。但在酒店比价的场景中,如果图像中的 100 个字分布在4家酒店中,每家酒店中有一个错字,那么这4家酒店的信息全是无效的。基于这种情况,我们根据自己的业务场景,制定了按酒店维度准确率的评估标准,即一张图像中有4家酒店,识别之后,有 3 家信息是完全正确的,那么准确率为 3/4=0.75。最终,测试人员使用多种 APP 酒店 List 页图像进行了评测,酒店维度准确率为 94%。
4.2 电子发票 OCR 识别
4.2.1 背景
酒店发票系统中,代理商可以根据用户提交的发票信息为用户开具 PDF 版增值税电子普通发票,如何保证代理商开具的发票是准确无误的,是我们面临的问题。在这样的背景下,我们可以对代理商开具的电子发票与用户提交的信息做比对,以达到为用户提供的电子发票是准确无误的。那么,如何获取 PDF 电子发票中的信息呢?
我们有两种方案,一是使用 PDF 解析工具直接解析电子发票中的内容,但对于解析之后的结果提取我们关注的内容是个难题,另一种方案是使用图像 OCR 识别的方法,我们可以利用电子发票的版面结构,提取 OCR 识别之后的结果。经过对两种方案的对比,使用 PDF 解析工具需要对各种版本进行兼容,不同尺寸的电子发票在定位的时候也需要单独处理,最终我们选择了后者。
4.2.2 挑战
我们使用通用的 OCR 识别方法对电子发票进行了识别,从初步结果来看,还是存在一些问题:

4.2.2.1 结构化困难
目前大部分文本识别模型都是按行识别,OCR 之后的结果就是一行一行的一堆文本数据。而原始的发票信息其实不是简单的一行一行的排版,这就给我们结构化带来了很大的挑战。如第 5 行文本,将“购买方”中的“购”字,与“密码区”中的“密”字,以及名称等识别在了同一行,如果我们想提取购买方的名称的话,就需要对第5行文本通过增加各种规则才能解析出关注的内容。而这个规则又需要根据各种具体的 case 进行定制实现,实现起来会非常麻烦,且可能存在由于结果的变化,导致解析错误。
4.2.2.2 文字黏连
OCR 识别模型需要依赖检测模型的结果,如果检测错误,就会导致识别错误。第 9 行文本,可能是因为生成电子发票的时候,填写的内容与发票原来的结构信息出现位置偏移,导致“项目名称”与“*餐饮服务*餐费”两行离得太近,几乎黏连在一起,检测模型将这两行识别成同一行,识别模型将两行文本当成了一行识别,最终导致识别错误。
4.2.3 解决方案
4.2.3.1 发票图像版面分析
OCR 结果结构化,一直是业务的痛点,虽然将图像中的文字进行了识别,但想从 OCR 的结果中提取自己感兴趣的内容,还是一件比较困难的事情。电子发票的排版主要是使用表格,我们的做法是先对图像进行直接线检测,使用交点过滤掉无效直线,就得到了图像中的表格,表格中的每一个单元格都是一个独立的区域,整个发票被切分成 18 个区域。
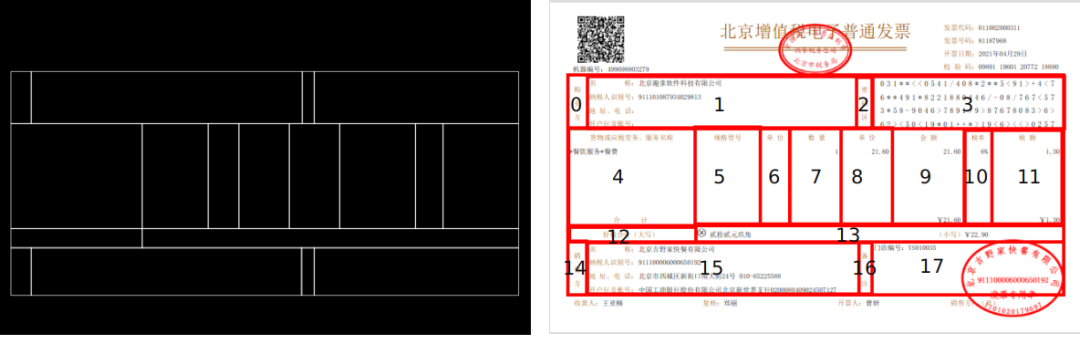
在发票系统项目中,业务中只关注购买方的信息、项目名称、价格、销售方信息、备注这 5 个区域,也就是 1、4、13、15、17 区域,这样我们就只需要识别这 5 个区域就可以了。使用这种方法,不再会受到其它区域中文字的干扰,给结构化带来了便利。并且我们只需要对整个图像的部分区域进行识别,减少了 OCR 的识别量,间接提升了识别性能。
4.2.3.2 发票图像内容分离
我们通过对发票图像中颜色的深入分析,发现其实可以将图像中的内容按颜色分成两类,一类是发票的原始结构信息,使用彩色展示,另一类是填写的发票内容信息,使用灰度色展示,我们可以基于这个特性,将发票图像分离成两部分。

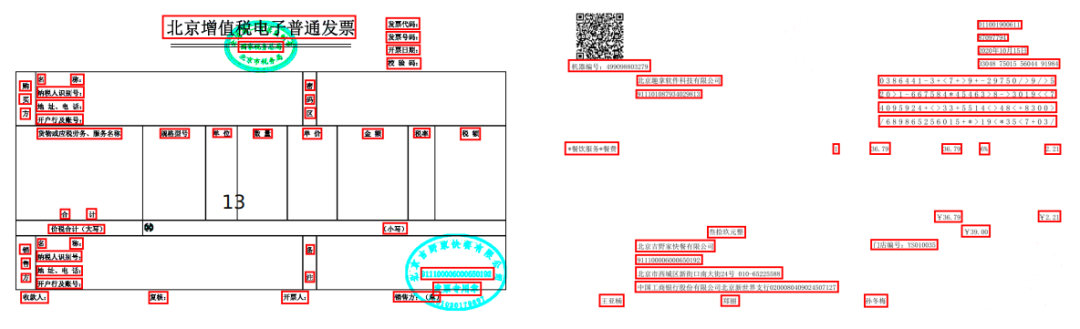
通过分离后的图像再进行 OCR,不再有原来的黏连问题。在酒店发票系统这个应用场景下,结合版面分析与发票分离后的结果,我们可以只对指定的感兴趣区域中的内容信息进行 OCR 识别,不再识别固定的结构信息。这样,OCR 的识别量有了更进一步的下降。
4.2.4 结果展示与评估
发票识别 OCR 结果展示:

经过最终测试评估,图片维度的准确率为 99%。
5. 未来规划
5.1 通用方法结构化
OCR 结果结构化,是我们在各个场景中都存在的问题,我们目前的做法基本是针对不同场景,使用不同的结构化方法,比如酒店比价场景中,我们使用了目标检测的方法检测酒店名价格,在发票识别场景中,我们使用了表格检测的版面分析方法。但这些方法都不能通用,后续希望能通过 NLP 文本分类的方法直接对文本进行属性识别,比如识别类别可以分为酒店名、酒店级别、酒店地址、酒店价格、评论、标签等。
5.2 OCR 纠错
酒店比价场景,OCR 识别结果中,存在形近字识别错误的情况,而这种错误又是很难通过优化识别模型解决的。比如将下一步的“一”识别成了“-”中划线,这两个字符看起来非常相似,由于不同的字体字号,大小也不一样,想通过识别模型解决这类 case 就会非常困难。后续准备结合使用图像 +NLP 相关特性进行纠错来解决这类问题,使用文字识别的低阈值找到一些可能存在识别错误的文字,使用 NLP 纠错方法对可能错误的文字进行校验和纠错。
5.3 端到端的 OCR 检测与识别模型
目前我们使用的 OCR 识别模型都是分为两个步骤的,文本检测和文本识别,在模型训练和优化过程中会比较麻烦,需要同时考虑两个模型的问题。而文本检测与识别模型融合成一个端到端的模型,一直是学术界研究的热点,后续我们也需要在这个方向有更多尝试,让 OCR 能为 qunar 解决更多的业务问题。
6. 参考文献
[1] Zhi T , Huang W , Tong H , et al. Detecting Text in Natural Image with Connectionist Text Proposal Network[J]. European Conference on Computer Vision, 2016.
[2] Shi B , Xiang B , Cong Y . An End-to-End Trainable Neural Network for Image-Based Sequence Recognition and Its Application to Scene Text Recognition[J]. IEEE Transactions on Pattern Analysis & Machine Intelligence, 2016, 39(11):2298-2304.


