




引入 | 数据采集-ETL(Extract-Transform-Load)之Kettle抽取-Spoon作业

开篇:想必大家都有一个疑问?何为ETL?它又能够给我们带来什么?
综述:ETL英文Extract-Transform-Load,BI项目重要的一环-将业务系统的数据经过抽取、清洗转换之后加载到数据仓库->企业中的分散、零乱、标准不统一的数据进行整合,为决策提供分析依据。
实战:go...
Kettle建数据库流程
一、创建MySQL数据库流程:
1. 打开Spoon,点击右上角

2. 点击Repository Manager,点击add,新增一个用户
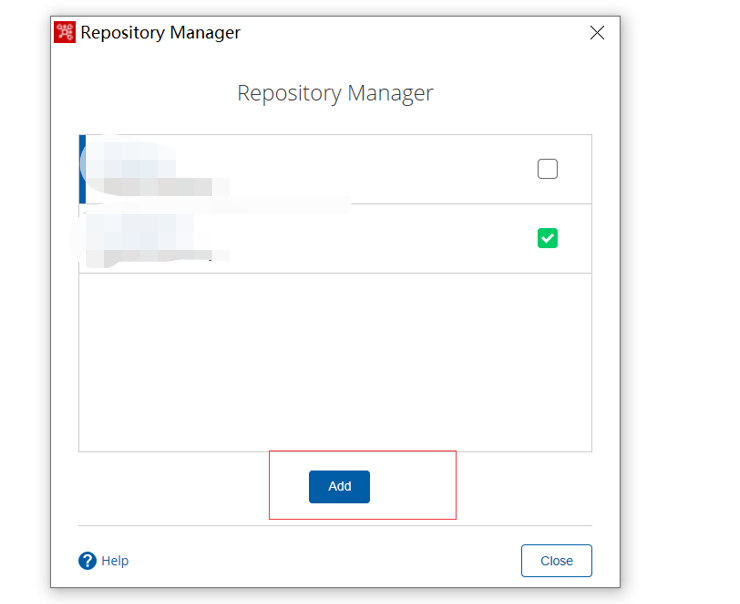
3. 选择database

4. Mysql数据库用户名密码


创建完成.
二、创建Oracle数据库流程:
数据库连接编辑
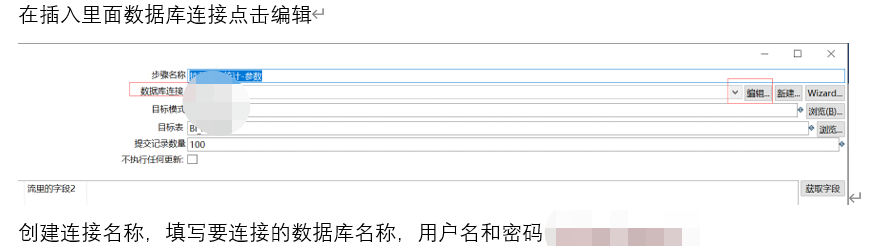

点击测试,成功后显示

「 往期文章 」
Elasticsearch读写数据工作原理 | MySQL的重复数据插入处理
Elasticsearch进阶篇 | 记kibana执行dsl脚本实战过程
Kafka | 记一次修复Kafka分区所在broker宕机故障-引发当前分区不可用的思考过程
开源数据库 | 记一次基于鲲鹏欧拉操作系统openGauss实践过程
序列化 | Google的Gson与Alibaba的FastJson机制

「喜欢这篇文章,您的关注和赞赏是给作者最好的鼓励」
关注作者
【版权声明】本文为墨天轮用户原创内容,转载时必须标注文章的来源(墨天轮),文章链接,文章作者等基本信息,否则作者和墨天轮有权追究责任。如果您发现墨天轮中有涉嫌抄袭或者侵权的内容,欢迎发送邮件至:contact@modb.pro进行举报,并提供相关证据,一经查实,墨天轮将立刻删除相关内容。
