





注:本文来源于老白的微信公众号“白鳝的洞穴”。
一套达梦DM8的数据库突然宕机了,从达梦数据库的日志中没有发现任何有价值的报错信息:

13点13分的最后一个报错信息是一个网络报错,因为有会话断开导致,只是一个警告,并不是导致达梦数据库宕机的主要原因。在操作系统上也找不到core dump的信息:

如何进一步定位问题呢?这时候D-SMART登场了。从告警台可以看出11:00开始系统开始出现大量的runtimeerror报警,并且在13点开始超过了20个:
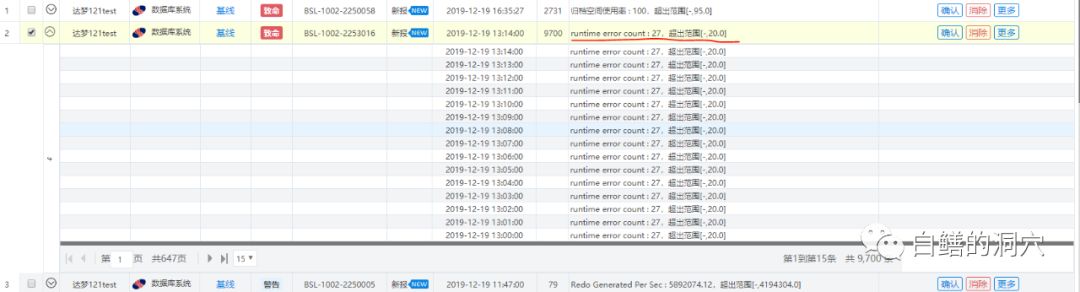
大致定位系统故障的开始区间是在13点左右。从runtime error指标上看:
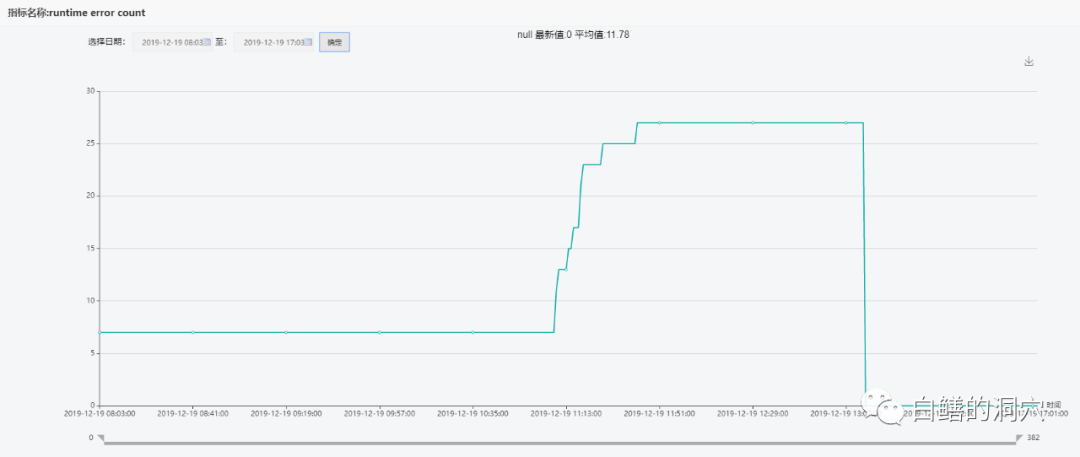
从今天上午11点多开始增多,到下午11:42达到峰值,在13:14分后,数据库宕机。于是我们从11:11到13:15 之间生成一份数据库的诊断报告:
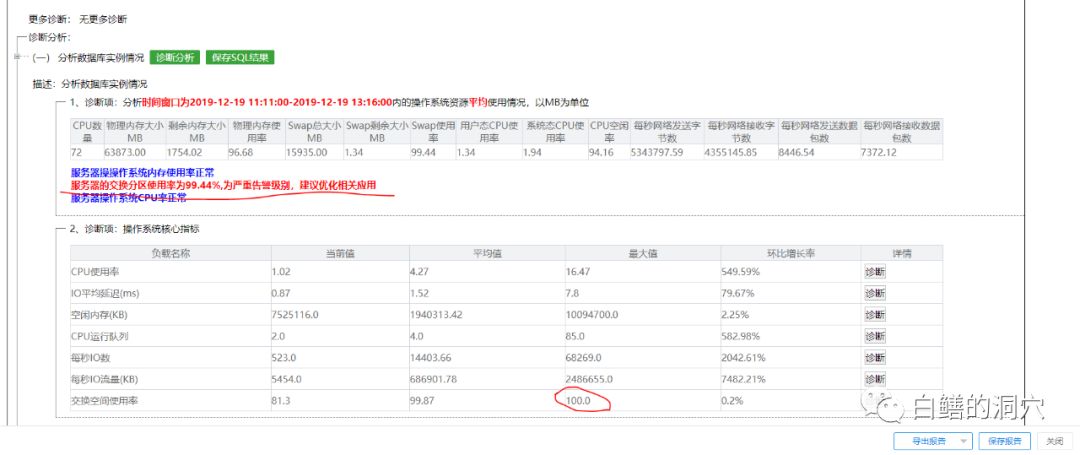
从报告上可以看出,OS的物理内存还有剩余,但是SWAP使用率却十分高,
从诊断报告上可以看出,在可能导致宕机故障的时间段内,有一个明显的问题,就是虽然物理内存还有较多空闲,但是操作系统的SWAP使用率比较高,超过95%,甚至出现了100%的现象。从SWAP使用率指标看:
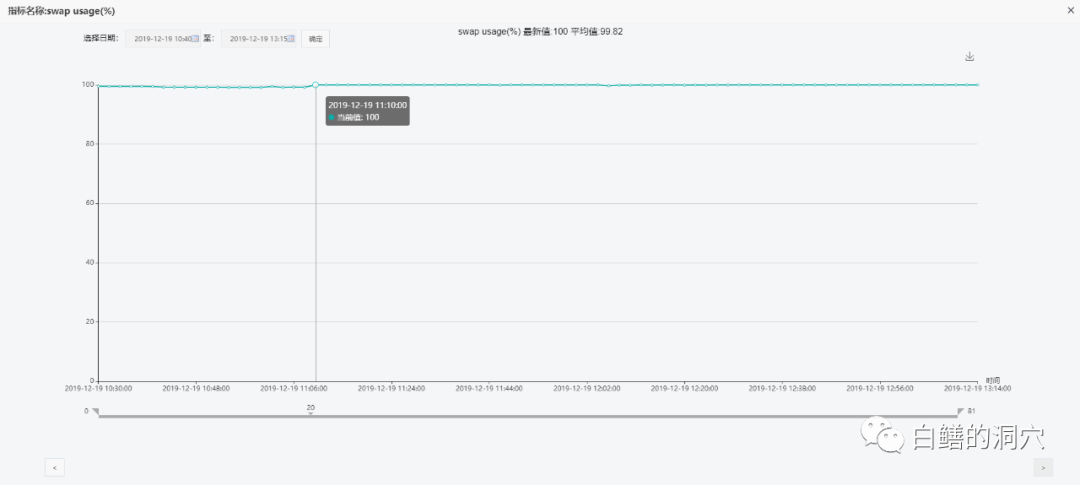
在11点10分之前的采样点虽然都很高,但是没有达到100%,11点10分开始到宕机的所有采样点都是100%。
检查OS的MESSAGES日志:

在数据库宕机时,OS同样在报SWAP空间为0。至此,该问题基本定位,是因为OS的SWAP耗尽导致数据库宕机。从这个案例也给我们一个警示,LINUX 7.x在VM策略上有较大的调整,因此即使物理内存还有空闲的情况下,也还有可能出现SWAP耗尽的情况,因此仅仅监控操作系统内存是不够的。
至此我们的工作并没有完成,由于我们以前在知识上的误区,导致了这次宕机并没有被十分明显的报出来,我们的健康模型与运维经验报警都没有准确的对此次故障进行预警。通过这个故障的分析,我们将调整两个知识库,一个是达梦的健康模型,以前的模型中只关注物理内存空闲比例,而没有关注SWAP的使用率,因此我们必须将SWAP使用率的成分加入到健康模型中。同时我们将针对物理内存监控的运维经验进行进一步的调整与优化。
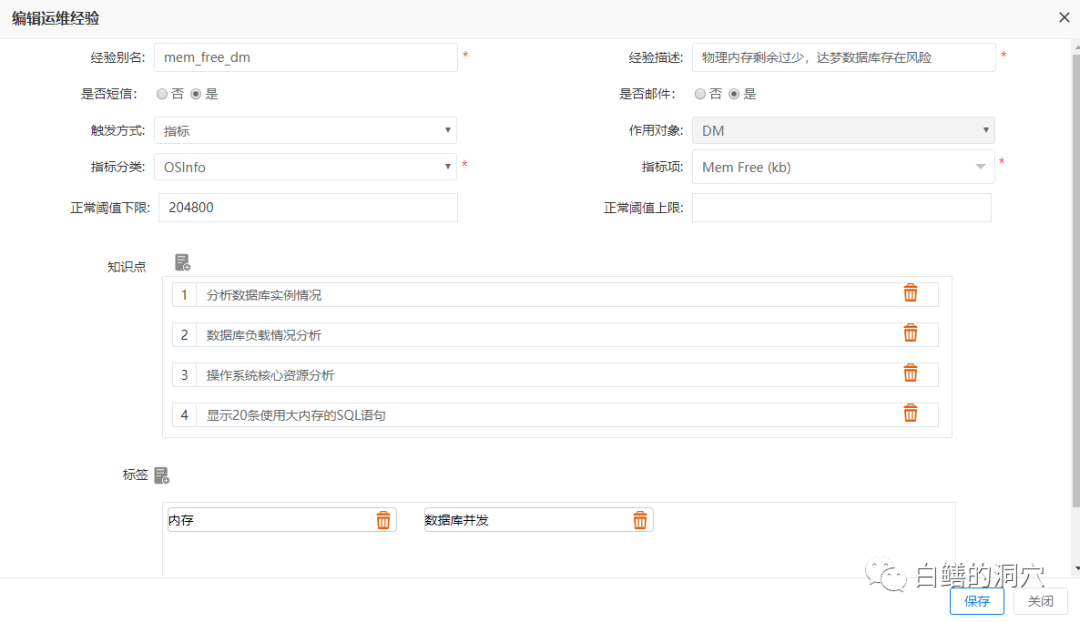
我们将该运维经验调整为一个高级表达式,同时监控MEM FREE和SWAP USAGE:
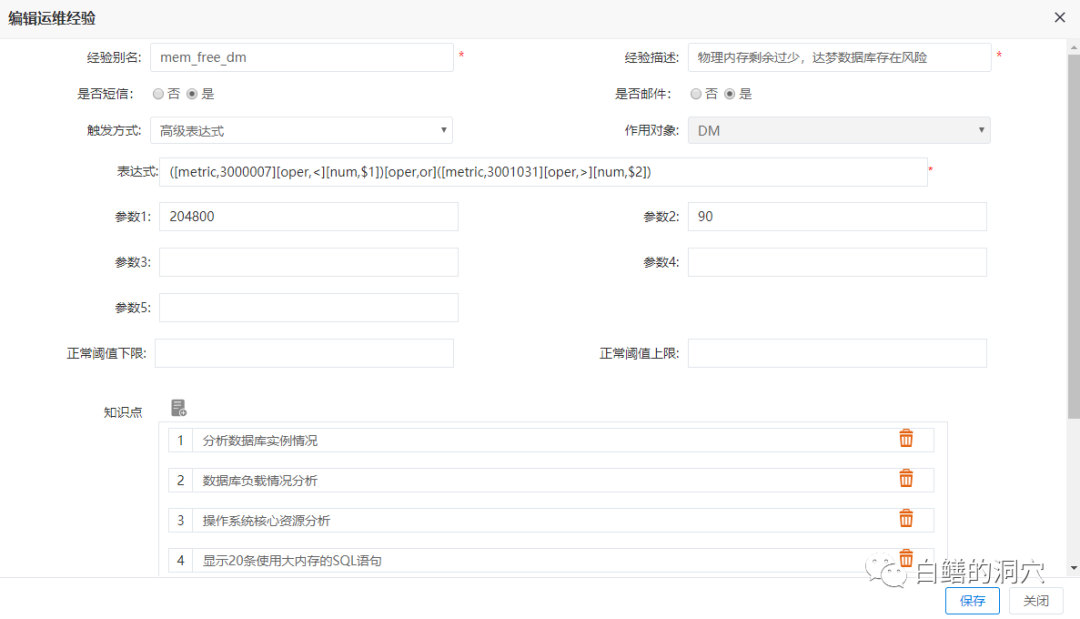
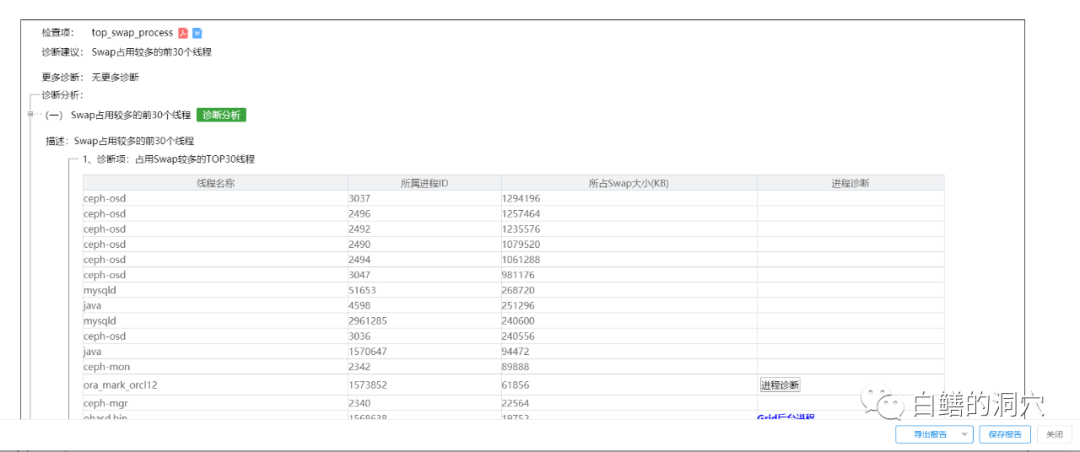
调整后,再次出现类似问题时,健康指标会大幅下降,产生报警,同时运维经验也会报警,运维人员根据这两个报警,可以在系统宕机前就发现问题所在,并使用SWAP分析工具查找问题根源,提前处置,解决相关问题:

徐戟,网名“白鳝”。从事应用开发、Oracle数据库、性能优化工作超过20年,一直从事IT咨询服务和系统优化工作。曾供职于DEC、赛格集团、长天集团、联想集团等国内外知名企业,现任南京基石数据技术有限责任公司/子衿技术团队 技术总监。
1999年起致力于Oracle数据库性能优化等方面的研究,参与了大量性能优化项目,积累了大量的实际工作案例。著有《ORACLE 优化日记》、《ORACLE RAC日记》和《DBA的思想天空》三本数据库技术图书。
