




引言
随着互联网的快速发展,尤其是移动互联网的快速普及,用户和数据都在急剧膨胀,服务需要支撑更多的用户请求和更大的数据规模。业务在快速发展既是幸福也是烦恼、原有的通架构是否能支撑、有限的资源投入如何能支撑快速的用户增长。缓存是在互联网业务后台会经常用到的基础组件,特别是在业务快速发展阶段经常会引入缓存来降低存储层压力降低用户请求延迟提升系统性能,让有限的资源能够更好的服务更多的用户。
内容概要
缓存作为性能优化的银弹究竟适用哪些业务场景,缓存资源有限而珍贵又该如何提升缓存的有效使用避免资源浪费,缓存在使用中又该如何尽量保证和存储层的数据一致性,缓存的三座大山又该如何翻越,实践中缓存组件引入和运营该注意哪些点,本文将一一解答。
缓存的适用场景
高并发系统中经常使用缓存来提升系统性能,保护后端的存储系统。为了降低服务响应延迟,服务中经常会将一些常用数据和热点数据缓存起来,从而直接读取缓存数据降低请求的响应延迟。缓存虽然是提升系统最常见在某些常见下也是最方便适用的手段但并意味着缓存就是银弹,缓存也有适用的场景,缓存的适用场景一般需要满足如下条件:
读多写少,读多才能更好发挥缓存性能优势提升收益,写少能够降低写入的成本
弱一致性要求,增加一层缓存系统之后缓存和存储系统的数据一致性比较难保证,系统对数据一致性有强要求的不适合使用缓存
除上述场景之外缓存还可以用来解决高并发写的问题,比如统计数据,对精度要求不高,但是写量特别大很容易导致存储层过载,特别是热key的场景无法通过扩容解决。
读场景
该场景下数据的读取都是先从缓存中读取,读取不到再从存储层读取,然后更新到缓存。
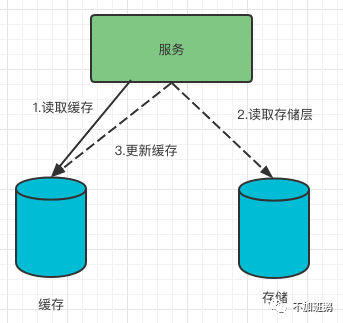
读场景的逻辑看起来很简单,但是在分布式高并发场景下要真正能处理好又很复杂,需要处理的并发细节太多了。缓存命中率是缓存系统中首先要考虑的问题,缓存的空间珍贵而有限,存储真正的核心数据和热点数据才更有利于整个系统的心更难,缓存命中率超过一定值才能对系统性能有比较明显的提升。缓存的淘汰和更新是使用缓存需要考虑的第二个问题,过期缓存如何淘汰才能保证缓存的是有效数据,缓存如何更新才能尽量保证缓存和存储层的数据一致性。缓存中的三座大山缓存击穿、缓存穿透、缓存雪崩是所有使用缓存的开发都头痛的问题。并发继续增加后可能还需要考虑本地缓存,以redis为例单分片只能抗10w/s左右的读,并发超过的这个数据量级的就只能采用多级缓存的策略使用本地缓存继续提升性能。
写场景
该场景下数据的写入不是直接写入到存储服务,而是将数据缓存到存储服务然后再定时或者定量刷入到存储服务。
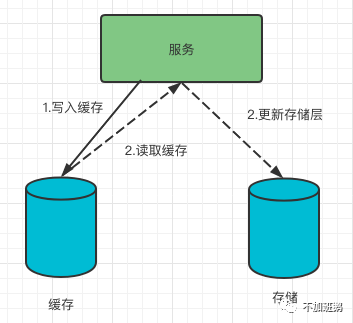
缓存写场景一般针对的是热key的写入,而且这类场景一般对于数据的准确度要求不高。以直播的点赞为例,点赞过程可以分为写入个人的点赞列表和新直播间的点赞数目两个步骤,个人数据的更新由于key不一样可以认为均匀分布的,但是直播间的点赞数据由于都是同一个key很容易形成热KEY,这类数据的数据准确度要求不高,可以通过本地缓存结合异步合并写入的方式来降低存储层的写入压力解决热key写入的问题。
点赞更新逻辑:更新个人点赞列表更新本地缓存的点赞数目检查本地缓存的点赞数if 本地缓存点赞数 > 50 || 上次更新时间 > 100ms更新存储层点赞数更新本地缓存数据和更新时间
缓存的淘汰策略
缓存资源一般比较有限且珍贵,为了最大限度的提升缓存资源的利用率,需要保证核心的、热门的数据的缓存空间,淘汰掉不常用的数据,提升缓存命中率。常见的淘汰策略有LRU、LFU、 LRU-K等,下面将对几种最常见缓存淘汰策略进行详细介绍比较。
LRU
LRU淘汰策略,英文名Least Recently Used,意思是最近最少使用的淘汰算法。LRU记录数据访问历史,按访问的先后顺序进行排序优先淘汰最近没有访问过的数据。LRU的实现一般使用一个双向链表最近访问的放在队头从队尾开始淘汰。虽然看着data1被访问后迁移了3步,但因为是双向链表实际上只是从队尾删除插入队头,data3和data2都不用移动。
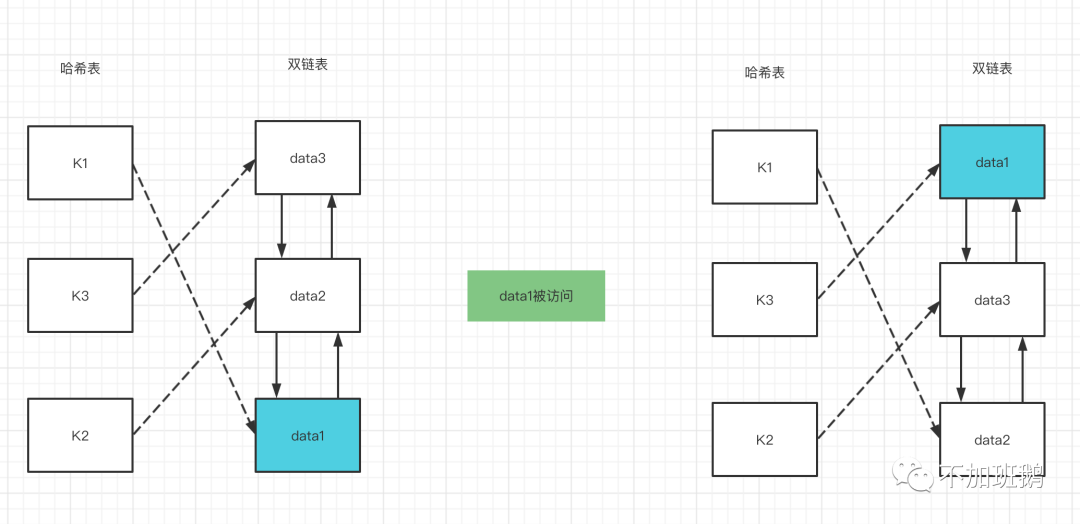
LRU的核心思想是最近被访问的数据后续被访问的概率更高,通过hash表和双链表结合能够实现get和put都O(1)的复杂度。put的时候先查询hash表看是否存在,如果存在则通过hash查到到对应的链表指针从该位置删除并插入到队头,如果没有则直接插入到队头判断是否启动台套流程返回数据。get和put的流程比较类似,hash表中先看是否有没有就直接返回无数据,有的话将数据调整到队头然后返回。
LRU是缓存中最常见的淘汰算法。LRU算法通过hash和双链表能够实现get/put都O(1)的复杂度,LRU淘汰的是最近最少使用的数据从而将最近使用的数据缓存起来。这个策略是最常见的的缓存淘汰策略但对某些场景也会有不适用,突发性的、周期性的突然的大量冷数据缓存会淘汰热key数据从而降低缓存命中率导致严重的缓存污染问题。
LFU
LFU是另一种常见的缓存淘汰策略,LFU淘汰策略是基于最近访问频次进行淘汰。LFU淘汰策略的核心思想是历史被高频访问的数据后续继续访问的概率更高。LFU淘汰策略需要记录缓存的访问频次信息,在get/put的时候更新频次信息,进行缓存数据淘汰的时候淘汰掉最低频次的双链表中的表尾数据,必要时候更新缓存策略的最小频次数。整个LFU的数据结构如下图所示。
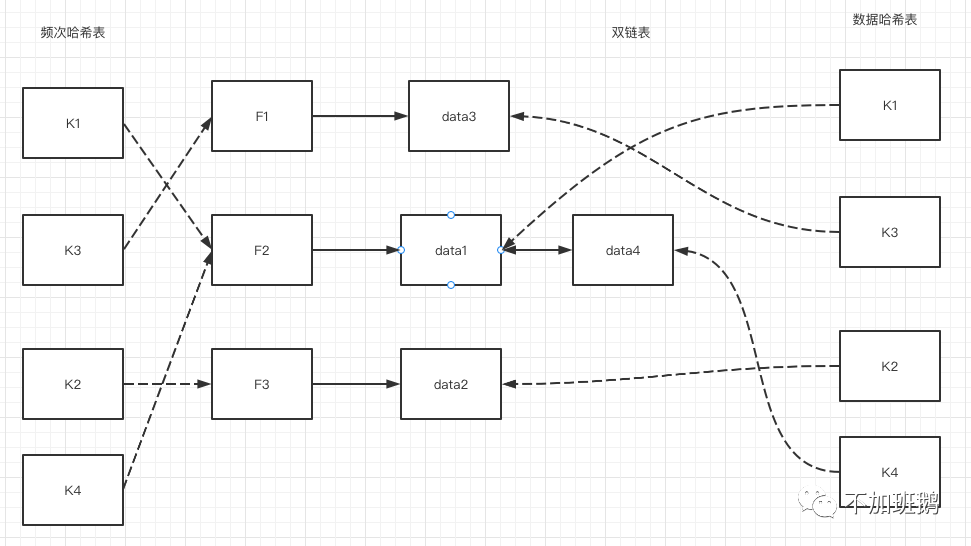
LFU淘汰策略由于引入了历史频次数据,所以对于偶发性和周期性的冷数据具有天然抗性。
LRU-K
LRU-K是针对LRU算法存在的突发或者周期性的大量冷数据淘汰热点数据的问题而进行优化的算法,LRU可以认为是LRU-1的特例。LRU-K的核心思想是最近访问过超过K次的数据最近被访问的可能性会更好,通过K提升了进入LRU队列的缓存数据的门槛,能够较好的避免缓存污染的问题。
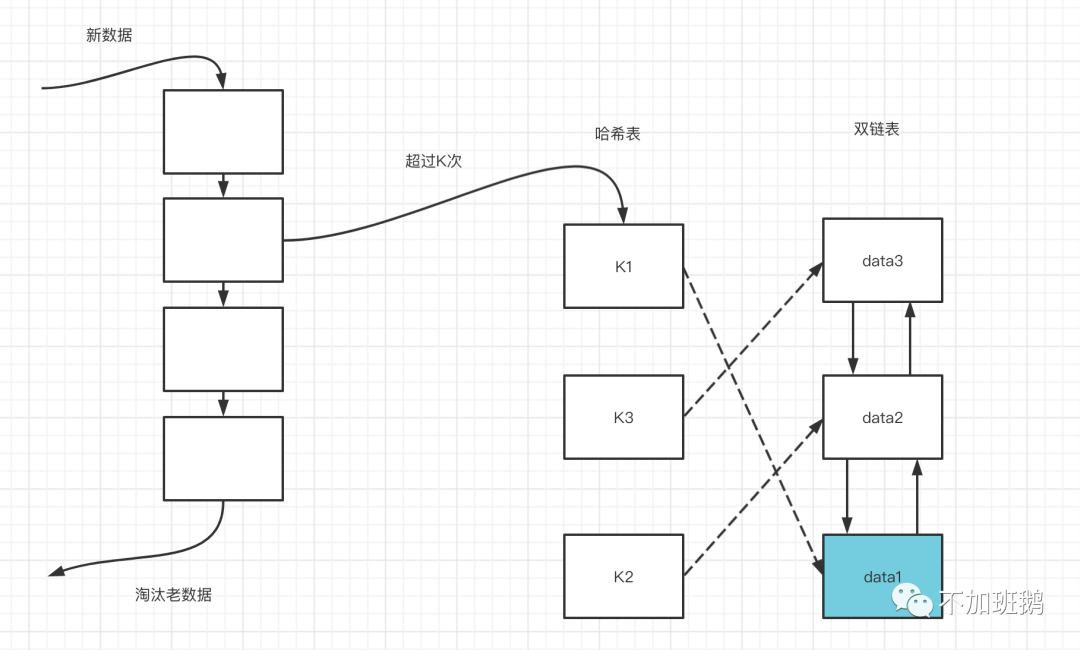
LRU-K与LRU区别是,LRU-K多了一个数据访问历史记录队列。队列中维护着数据被访问的次数以及时间戳,当队列超过限制就会淘汰老的访问次数少的数据,
只有当这个数据被访问的次数大于等于K值时,才会从历史记录队列中删除,然后把数据加入到缓存队列中去。
LRU-K降低了“缓存污染”带来的问题,命中率比LRU要高。实际应用中LRU-2是综合各种因素后最优的选择,LRU-3或者更大的K值命中率会高,但适应性差,一旦访问模式发生变化,需要大量的新数据访问才能将历史热点访问记录清除掉。
复杂度与代价:LRU-K队列是一个优先级队列。由于LRU-K需要记录那些被访问过,但还没有放入缓存的对象,导致内存消耗会很多。
缓存的更新策略
缓存的使用是为了降低服务响应延迟提升服务整体性能,前面提到过缓存适用于那些对于数据一致性没有强要求的场景,然而如何尽量保证缓存和存储的一致性仍然是缓存使用中要思考的问题。为了保证缓存和存储层的数据一致性就涉及到缓存的更新策略,常见的缓存更新策略有Cache aside, Read through, Write through, Write behind caching,下面对这几种更新策略做详细介绍。
Cache aside
cache aside是最常见缓存更新策略,基本逻辑是数据读取时先从缓存中读取,如果缓存命中则直接返回,否则从存储层读取数据并更新到缓存中最后返回数据。数据更新的时候先更新存储层的数据然后删除缓存中的数据。
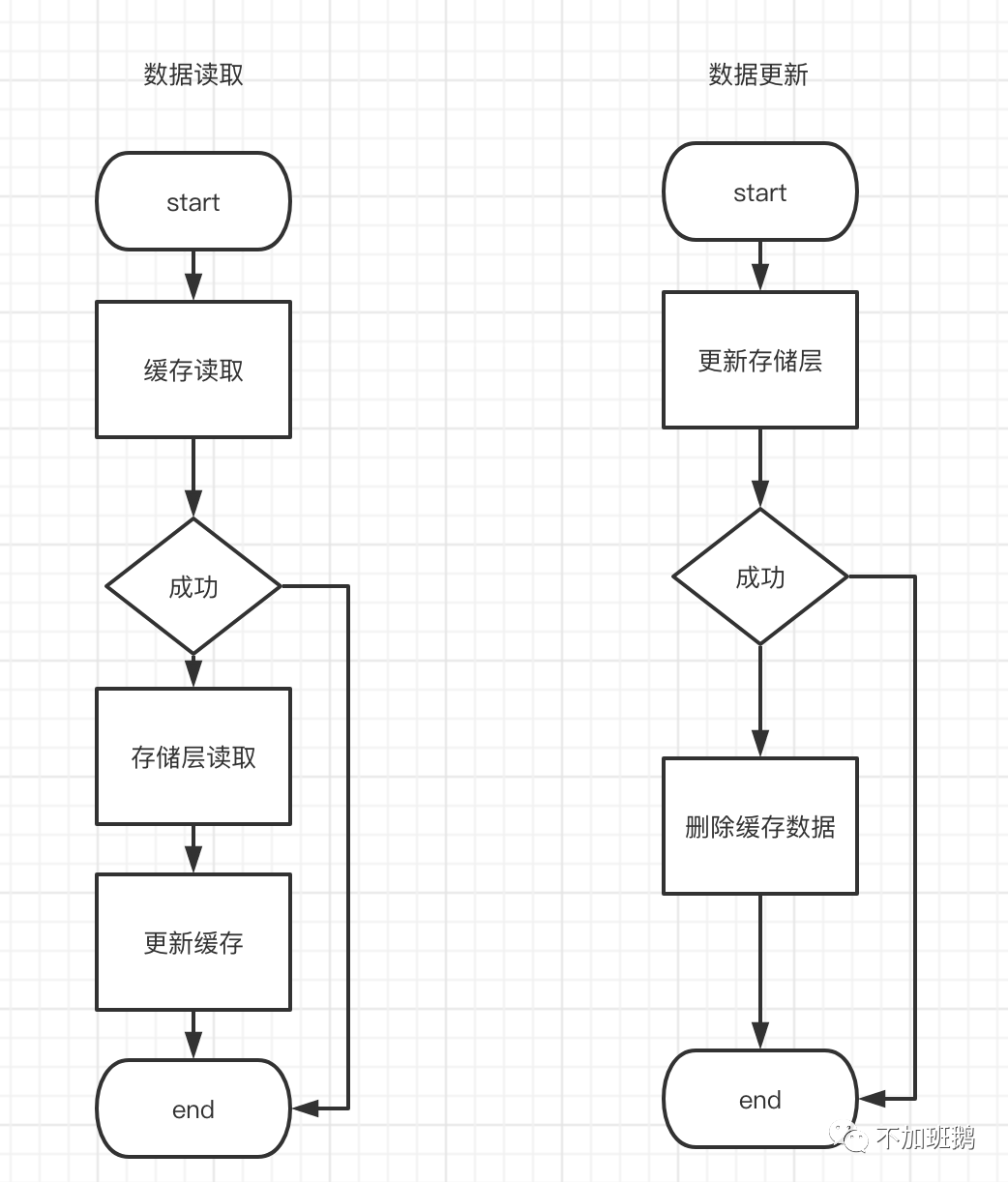
数据读取的流程比较容易理解,缓存中没有数据要去存储层读取,但是数据更新流程中删除缓存数据这个操作能不能是更新缓存,是否需要在更新存储层前后进行双删等可能会有很多疑惑。
删除缓存数据是为了尽快实现缓存数据和存储层数据的一致性,否则缓存中的数据需要等到缓存数据自然到过期时间后才会进行更新,通过缓存数据的删除能加速数据一致性的同步。那是不是可以先删除缓存再来更新存储层呢?考虑如下读写并发场景,更新操作在删除缓存之后读操作发现缓存失效就会加载存储层数据到缓存从到导致缓存旧数据。那是否需要进行双删呢?其实意义也不大,更新前缓存删不删都是读取的旧数据,更新后的删除会让缓存进行强制更新。
有些可能想把删除操作换成更新缓存的操作,缓存更新操作存在如下两个问题:
缓存数据存储的可能是加工后的数据,数据计算过程比较复杂会导致更新时间长
删除缓存其实是一个懒加载的思想,更新的可能是一个冷数据没有必要更新到缓存占用缓存空间
缓存删除相比更新更轻量,可靠性更好
当然这种缓存更新方案并不是说完全没有并发问题,缓存读取操作时发现缓存失效,然后去读取存储层数据,这时候写操作更新了存储层数据并使缓存失效,然后读操作将读取到的旧数据更新到了缓存中就会出现缓存旧数据的问题。这种场景出现的概率极小,因为这个条件需要发生在读缓存时缓存失效,而且并发着有一个写操作。而实际上数据库的写操作会比读操作慢得多,而且还要锁表,而读操作必需在写操作前进入数据库操作,而又要晚于写操作更新缓存,所有的这些条件都具备的概率基本并不大。
Read/Write through
cache aside模型需要应用开发人员同时维护缓存读取和存储读取两套逻辑,加重了应用开发人员的工作负担。Read/Write through通过一个缓存中间件收拢了对缓存和存储层的操作,业务逻辑服务只需要对接该中间件。读取的时候直接从该中间件读取,如果命中了缓存数据则从缓存直接读取,否则由该中间件去存储层中加载数据并更新缓存后返回。更新也是类似的,如果缓存中没有则直接更新存储层,如果有则先更新缓存然后更新到存储层。读写的缓存和存储层的同步统一由中间件进行管理,对上层服务来说只会感知到一个数据源的操作,相比cache aside简化了上游服务的复杂度。
Write behind cache
该更新策略和Read/Write through策略比较类似,也是由一个中间件代理了代理了缓存和存储层的数据同步管理。两者之间的区别是一个是同步更新存储层,一个是异步更新。Write behind的一个典型应用就是文件系统的Page Cache,文件数据的更新并不是每次都会刷盘而是定时或者定量的刷新到磁盘。这种缓存更新的好处就是读写都很快,因为操作对象都是内存,但是会存在数据丢失的风险。
其他策略
除了上述常见的缓存更新策略,还有一些常见直接把缓存当做存储层来使用,缓存了存储层的全量数据,监听存储层的数据更新来同步到缓存系统,比较典型的就是听过binlog的监听来更新redis缓存。存储层更多的是作为一个冷数据备份来使用。
缓存的过期
为了保证数据的一致性和缓存的命中率,缓存中的数据会淘汰和过期,缓存资源有限也不太可能能够缓存全部的数据,这样在高并发的情况下就会出现缓存击穿、缓存穿透、缓存雪崩的问题。
缓存击穿
缓存击穿是指热点数据过期后,高并发的大量请求在缓存中读取不到数据从而全部转向存储层读取数据。热点数据是不可预测的,比如明星出轨这类资讯你很难提前预测到,所以那些说提前预热热点数据的方案只能解决类似双11那类提前有规划和预测的热点数据,对于这类突然的热点数据是没有效果的。缓存击穿的核心问题还是过期瞬间的突发流量,如何避免这些并发请求全部压到存储层保护好存储层呢?对于请求并发最简单的方式其实就是加锁,只有获取锁成功的请求才能去请求存储层,而加锁失败的则进行自旋或者sleep等待,等待的请求每隔一段时间请求一次缓存看是否已经有数据,如果有则读取缓存中的数据返回,如果超时则失败。通过该方案能够对于过期的热点数据只有一个请求会穿透到存储层上。
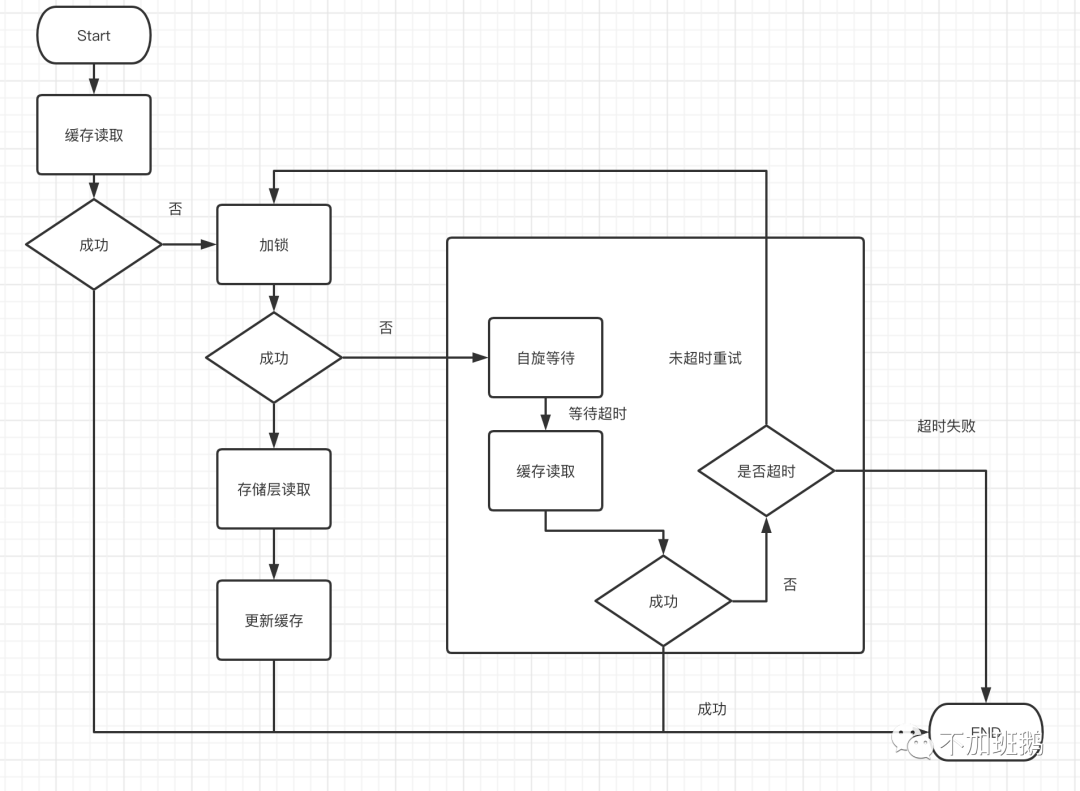
实际上对于go熟悉的话,系统库已经提供了缓存击穿的解决方案singinflight。基本原理相似都是保证对于同一个key的请求只有一个会传统到存储层上,不过在缓存更新成功之后singleinflight库采用了主动唤醒的方式,让等待这个缓存的所有协程能够快速读取缓存返回。singleinflight库的源码解析后续会再写个分析文章详细解读下。
缓存穿透
缓存穿透和击穿不同的点在于穿透是由于请求的数据是本身不存在的或者恶意请求的数据导致大量请求穿透到存储层从而对存储层造成很大的压力。由于数据不存在所以这类数据每次请求都会去访问存储层,对这类数据的拦截有两种常见的解决方案。
缓存无效数据。如果缓存中查不到数据,存储层也查不到,可以将该KEY当成一个正常数据缓存起来设置一个过期时间,同时该KEY对应的值为null。这样处理有两个好处,首先是统一了数据处理方式恶意数据和正常数据的处理都是一致的,然后是缓存中的数据能有效避免后续对该不存在数据的继续请求穿透。
使用布隆过滤器。布隆过滤器的作用是过滤恶意请求,布隆过滤器中某个 key 不存在,那么就一定不存在,它说某个 key 存在,那么很大可能是存在(存在一定的误判率)。于是我们可以在缓存之前再加一层布隆过滤器,在查询的时候先去布隆过滤器查询 key 是否存在,如果不存在就直接返回。对于正常数据需要及时更新到布隆过滤器中。
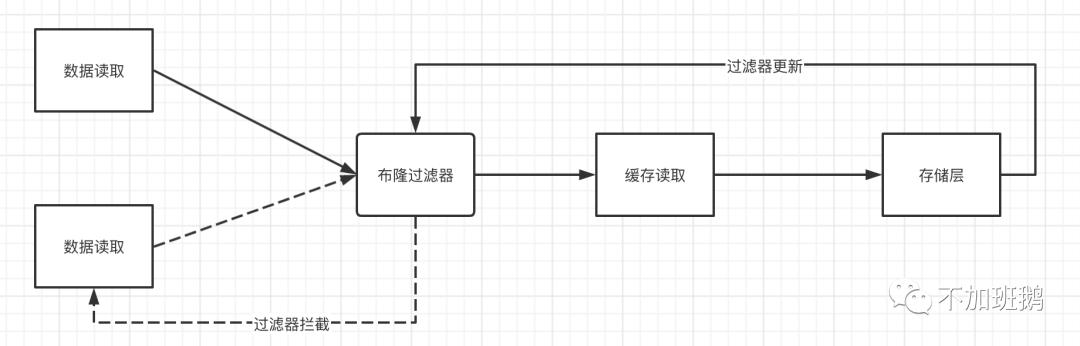
缓存雪崩
缓存雪崩是指缓存中的key大量同时过期导致的缓存失效大量请求同时穿透的存储层,在高并发的情况下存储层突然收到大量请求很容易造成请求的请求延迟增大请求失败等从而引发重试造成雪崩。缓存雪崩的最核心问题还是大量缓存同时过期,所以在设置缓存过期时间的时候可以统一的过期时间上增加一个随机时间避免缓存同时过期。
本地缓存
前面介绍了很多分布式缓存系统的使用,实际服务开发中还会用到大量使用本地缓存,本地缓存和分布式缓存互补构成多级缓存系统。以redis为例单分片估计也就能支撑10w/s的请求,而且在大量请求的时候网络流量和延迟也是使用分布式缓存中会遇到的问题,通过本地缓存减少对分布式缓存的请求压力同时能够减少大量的网络流量提升系统性能。本地缓存使用过程中也面临这和分布式缓存使用同样的问题,缓存如何淘汰、缓存如何更新、缓存的击穿、穿透和雪崩都是要考虑的点。相比分布式缓存本地缓存还有一个需要注意的就是数据请求的单调性。因为本地缓存会有多份缓存数据,每次请求的可能会被调度到不同的机器上从而导致读取的数据出现新旧新反复的问题。
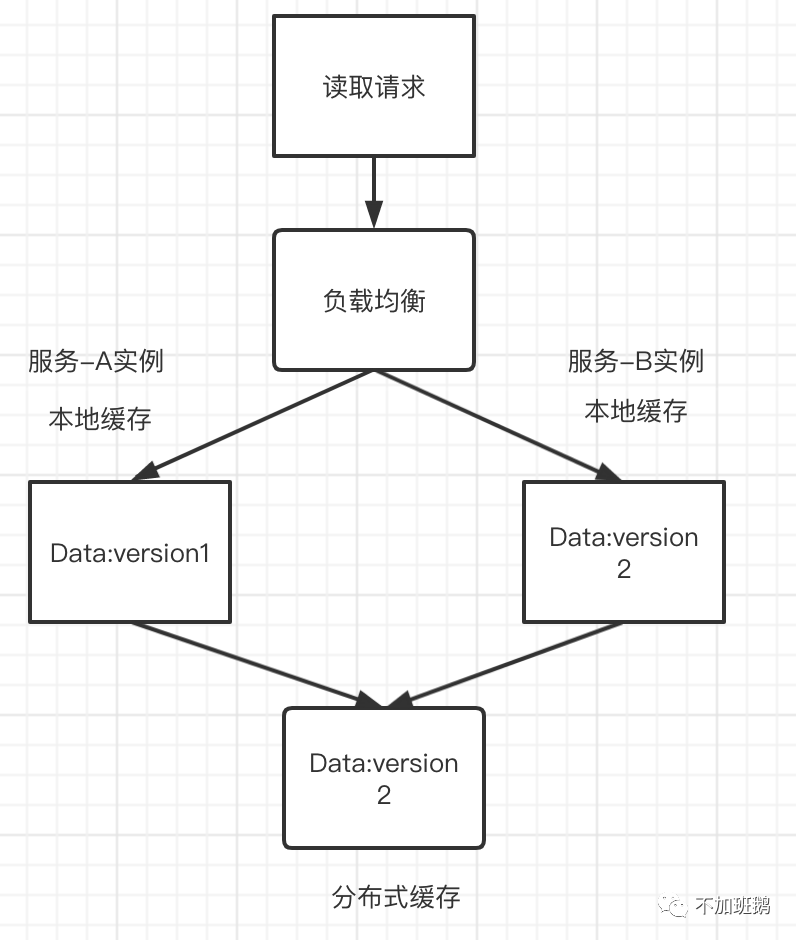
针对这个问题也有两个解决方案,第一个是一致性hash,同一个用户的请求都导到同一个服务实例,这样就能保证用户读取的本地缓存是同一个避免了读取两个不同的本地缓存数据出现的数据回滚问题。第二个方案是数据读取带上版本号,服务在读取本地缓存的时候比较数据版本号,如果低于请求的版本号则强制更新本地缓存数据。
本地缓存组件
本地缓存组件一般分为两类,一类是独立部署的缓存组件,一类是基于服务本地本地内存嵌入在程序内部的缓存组件。前者如memcached,之前服务运营中也确实碰到过本地缓存采用的这个方案,每台机器上都部署了memcached,混合部署的服务可以共用这个本地缓存组件。后者直接嵌入在应用程序中使用程序本身的内存构建本地缓存系统目前比较有名的如go的cachegroup,该缓存库还集成了singleinfligh的实现避免了缓存失效后对下游服务的压力。上述两个方案各有优劣,实践中本地缓存组件如何选择需要综合分析取舍。
缓存实践
缓存的引入除了需要对服务架构、代码逻辑做出适配调整,实际使用过程中还有很多需要注意的点,比如缓存组件的容量、缓存的隔离、缓存组件的监控、缓存组件的容灾等等。
容量评估
业务接入缓存系统前要做好容量的评估,缓存容量评估除了最基础的存储容量还需要考虑分片容量、流量评估等,尤其是对于那些热点数据集中的业务需要做好分片容量的规划来避免热点数据聚集。
业务分离
缓存使用要做好业务分离,保证核心缓存系统的稳定性。典型的就是运营活动类的缓存系统要和线上核心逻辑的缓存进行隔离,因为运营活动突发性比较强瞬时流量高,不作隔离很容易因为这类运营的突发流量影响到核心缓存系统从而导致整个业务核心服务不可用。根据业务场景做好缓存分离是做好系统隔离和系统降级的基础,必须在业务初期就做好规划否则后续的迁移成本会很高。
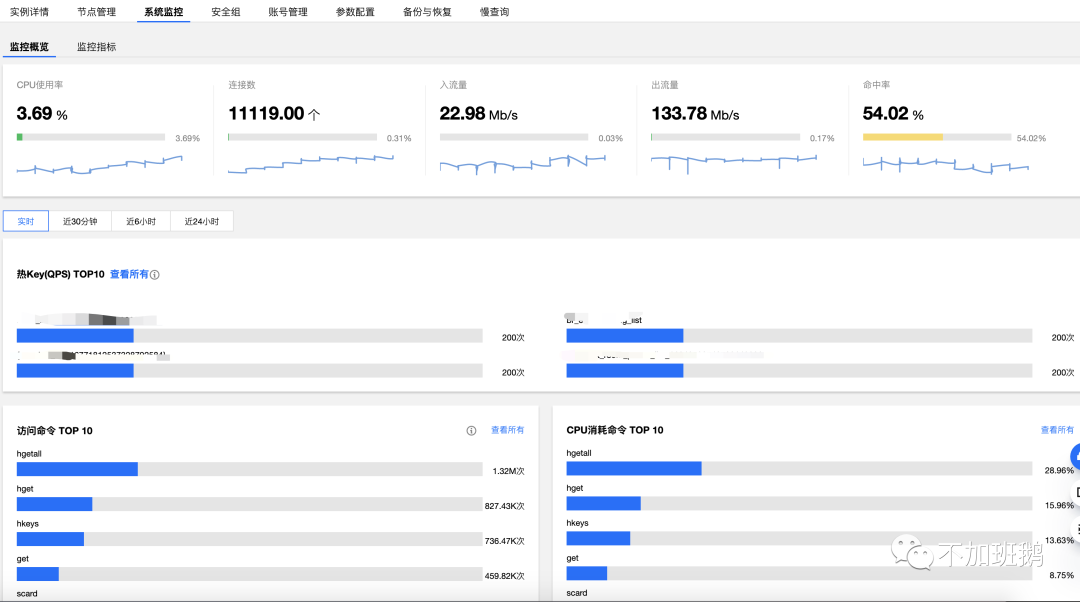
系统监控
监控是任何系统运营中都必不可少的部分,对于基础组件的监控尤其如此。除了常见的负载、流量、并发请求等监控之外缓存系统还需要特别注意缓存命中率的指标。对于这些基础组件的监控指标的异常要能及时告警出来。
总结
缓存的使用能够有效降低存储层的压力降低响应延迟提升系统性能,但是使用缓存会增加系统复杂性,需要对代码甚至整个服务架构和部署进行改造,同时新组件的引入也会增加系统的核心组件依赖风险。实际服务开发中应根据业务需要考虑是否需要引入缓存以及是使用分布式缓存还是本地缓存或者是多级缓存,避免系统的超前优化。如何合理有效的使用缓存需要综合考虑缓存的适用场景、选择合适的缓存淘汰策略、保证缓存系统和存储系统的数据一致性、处理好缓存数据在高并发场景下的击穿、穿透、雪崩的问题,同时要做好缓存组件的规划和运营。
