




常见操作
oracle是我们生产环境使用最频繁的数据库之一,因此将之前日常使用的相关操作记录下,备忘和方便使用。
1、连接
1)常规
oracle安装部署好后,cmd方式,输入sqlplus命令进行登录,格式sqlplus 用户名/密码@host:port/实例名
需要DBA角色登录要加 as sysdba
sqlplus system/123@127.0.0.1:1521/orcl
2)不使用用户名密码
有时候因为各种原因,需要不使用用户名密码直接连接oracle,一般情况下,按照如下命令登录即可
sqlplus /nolog
conn / as sysdba
有时候会提示无法登录,具体操作参考第四章1部分
2、表空间
临时表空间创建temporary tablespace
create temporary tablespace spacename_TEMP tempfile 'E:\oradata\spacename_TEMP.dbf' size 50m autoextend on next 50m maxsize 20480m extent management local;
表空间创建tablespace
create tablespace spacename logging datafile 'E:\oradata\spacename.dbf' size 50m autoextend on next 50m maxsize 20480m extent management local;
--不指定文件路径
--创建默认PDB表空间(会创建默认大小为100M,自增长为1M的表空间)
create tablespace cookdba;
Tablespace created.
--创建自定义PDB表空间
create tablespace lastdba datafile size 500m autoextend on next 100m;
Tablespace created.
Elapsed: 00:00:14.93
--批量修改用户表空间脚本
select 'alter table '||owner||'.'||object_name ||' move tablespace '|| owner ||';' from dba_objects where owner in ('CHARISMA') and object_type ='TABLE';
select 'alter index '||owner||'.'||object_name ||' rebuild tablespace '|| owner ||';' from dba_objects where owner in ('CHARISMA') and object_type ='INDEX';
表空间使用情况管理及扩展
--1、查看表在那个表空间
select tablespace_name,table_name from user_talbes where table_name='spacetest';
--2、获取用户的默认表空间
select username,DEFAULT_TABLESPACE from dba_users where username='spacetest';
--3、查看表空间所有的文件
select * from dba_data_files where tablespace_name='WORKINFO';
--4、查看表空间使用情况:
SELECT a.tablespace_name "表空间名",
total "表空间大小",
free "表空间剩余大小",
(total - free) "表空间使用大小",
total / (1024 * 1024 * 1024) "表空间大小(G)",
free / (1024 * 1024 * 1024) "表空间剩余大小(G)",
(total - free) / (1024 * 1024 * 1024) "表空间使用大小(G)",
round((total - free) / total, 4) * 100 "使用率 %"
FROM (SELECT tablespace_name, SUM(bytes) free
FROM dba_free_space
GROUP BY tablespace_name) a,
(SELECT tablespace_name, SUM(bytes) total
FROM dba_data_files
GROUP BY tablespace_name) b
WHERE a.tablespace_name = b.tablespace_name
--5、临时表空间剩余情况
select c.tablespace_name,
to_char(c.bytes/1024/1024/1024,'99,999.999') total_gb,
to_char( (c.bytes-d.bytes_used)/1024/1024/1024,'99,999.999') free_gb,
to_char(d.bytes_used/1024/1024/1024,'99,999.999') use_gb,
to_char(d.bytes_used*100/c.bytes,'99.99') || '%'use
from (select tablespace_name,sum(bytes) bytes
from dba_temp_files GROUP by tablespace_name) c,
(select tablespace_name,sum(bytes_cached) bytes_used
from v$temp_extent_pool GROUP by tablespace_name) d
where c.tablespace_name = d.tablespace_name;
select * from dba_temp_free_space;
select tablespace_name,file_name,bytes/1024/1024 file_size,autoextensible from dba_temp_files;
--5、扩展表空间 单个表空间文件最大不得大于32g,所以maxsize最大可以设置为31g
alter database datafile 'D:\ORACLE\PRODUCT\ORADATA\TEST\USERS01.DBF' resize 50m;
--自动增长
alter database datafile 'D:\ORACLE\PRODUCT\ORADATA\TEST\USERS01.DBF' autoextend on next 50m maxsize 500m;
--增加数据文件
alter tablespace yourtablespacename add datafile 'd:\newtablespacefile.dbf' size 5m;
--12c 扩展临时表空间
alter tablespace gj_temp add TEMPFILE size 1024m autoextend on next 200m;
--6、删除表空间 datafile_ID
ALTER TABLESPACE TEST DROP DATAFILE 3
3、创建用户
create user spacetest identified by 123456 default tablespace spacename temporary tablespace spacename_TEMP;
4、授权(根据实际情况)
grant connect,resource,dba to spacetest;
--表批量授权脚本
select 'grant select on '||table_name ||' to spacetest ;'
from user_tables
where tablespace_name='spacename' and table_name not like 'XX%';
--视图批量授权脚本
select 'grant select on '||view_name ||' to spacetest ;' from user_views;
5、备份及还原
备份
单次备份
exp spacetest/123456@127.0.0.1:1521/orcl file=E:\backup\spacetest_20190100.dmp tables=(TABLE1,TABLE2)
定时任务配套备份脚本
exp spacetest/123456@127.0.0.1:1521/orcl BUFFER=64000 file=E:\backup\spacetest_%date:~0,4%%date:~5,2%%date:~8,2%.dmp tables=(TABLE1,TABLE2) OWNER=spacetest log=E:\backup\log\spacetest_%date:~0,4%%date:~5,2%%date:~8,2%.log
还原
imp spacetest/123456@127.0.0.1:1521/orcl file=E:\backup\imp\spacetest_20190100.dmp log=E:\backup\imp\log\spacetest_imp.log FROMUSER=spacetest TOUSER=spacetest buffer=5120000 indexes=n commit=n ignore=y grants=n FEEDBACK=10000
impdp 详解
有时候数据的量比较大的时候 用dp的模式效率比较高
创建路径
--创建路径 windows E盘a文件夹 linux的话 /a/
create directory dpdata1 as 'E:\a';
select * from dba_directories;
--授权路径 对路径访问授权
grant read,write on directory dpdata1 to USERNAME;
impdp导入模式:1、按表导入 p_street_area.dmp文件中的表,此文件是以gwm用户按schemas=gwm导出的:
impdp gwm/gwm@fgisdb dumpfile =p_street_area.dmp logfile=imp_p_street_area.log directory=dir_dp tables=p_street_area job_name=my_job
2、按用户导入(可以将用户信息直接导入,即如果用户信息不存在的情况下也可以直接导入)
impdp gwm/gwm@fgisdb schemas=gwm dumpfile =expdp_test.dmp logfile=expdp_test.log directory=dir_dp job_name=my_job
3、不通过expdp的步骤生成dmp文件而直接导入的方法:--从源数据库中向目标数据库导入表p_street_area
impdp gwm/gwm directory=dir_dp NETWORK_LINK=igisdb tables=p_street_area logfile=p_street_area.log job_name=my_job
igisdb是目的数据库与源数据的链接名,dir_dp是目的数据库上的目录
4、更换表空间 采用remap_tablespace参数 --导出gwm用户下的所有数据
expdp system/orcl directory=data_pump_dir dumpfile=gwm.dmp SCHEMAS=gwm
注:如果是用sys用户导出的用户数据,包括用户创建、授权部分,用自身用户导出则不含这些内容 --以下是将gwm用户下的数据全部导入到表空间gcomm(原来为gmapdata表空间下)下
impdp system/orcl directory=data_pump_dir dumpfile=gwm.dmp remap_tablespace=gmapdata:gcomm
5、table_exists_action
oracle10g之后impdp的table_exists_action参数
impdp username/password table_exists_action=truncate directory=DATA_PUMP_DIR dumpfile=expdpfilename.dmp logfile=implog.log
table_exists_action:
skip 是如果已存在表,则跳过并处理下一个对象;
append是为表增加数据;
truncate是截断表,然后为其增加新数据;
replace是删除已存在表,重新建表并追加数据;
由于数据量较大 导入时可能出现静止的画面疑似卡住了,可以通过如下方法查看是否有数据导入https://blog.csdn.net/demonson/article/details/106056223
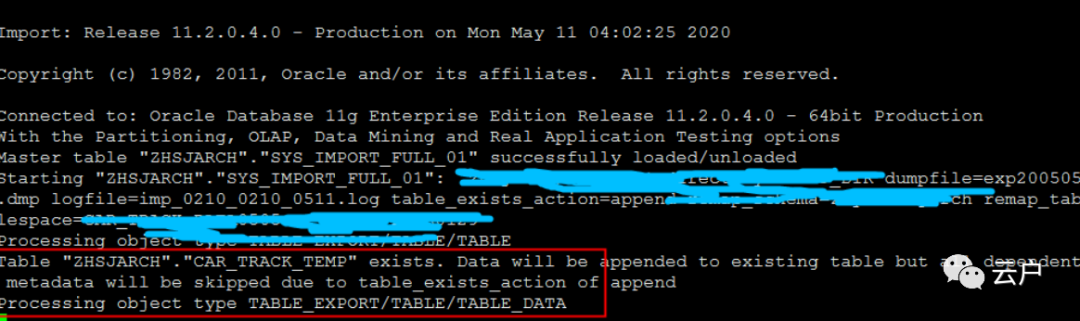
这种情况应该不是卡住了,而是因为导入表太大,oracle读取备份时间太长,没有实时显示读取进度,而产生卡住的错觉;
你可以用dba用户查看视图:
select * from dba_datapump_jobs;
state字段为executing状态则证明impdp正在导入;找到其中的job_name;该任务名应该就是现在正在执行导入的任务名,然后attach到impdp里面查看status进度,要是每次刷新进度增长,则证明impdp导入正常,耐心等待就好;eg:
job_name=sys_impdp_full_01
impdp ' / as sysdba' attach=SYS_IMPORT_FULL_01
若是每次status刷新,数字变化的话,证明没有问题;
6、字符集查询
select userenv('language') from dual;
---例如:结果为SIMPLIFIED CHINESE_CHINA.ZHS16GBK
7、日志查询
查询某张表的日志
select t.LAST_ACTIVE_TIME,t.* from v$sqlarea t
where t.sql_text like '%APPROVE_ITEM_WORKFLOW_FORM%'
order by t.LAST_ACTIVE_TIME desc;
附字段说明
SQL_TEXT ``//当前正在执行的游标的sql文本的前1000个字符
SQL_FULLTEXT ``//CLOB类型 整个sql文本,不用借助于V$SQL_TEXT视图来查看整个文本
SQL_ID ``//库缓存中的SQL父游标的标志
SHARABLE_MEM ``//子游标使用的共享内存的大小,bytes
PERSISTENT_MEM ``//子游标生存时间中使用的固定内存的总量,bytes
RUNTIME_MEM ``//在子游标执行过程中需要的固定内存大小,bytes
SORTS ``//子游标发生的排序数量
LOADED_VERSIONS ``// 显示上下文堆是否载入,1是,0否
USERS_OPENING ``// 执行这个sql的用户数
FETCHES ``// sql取数据的次数
EXECUTIONS ``//自从被载入共享池后,sql执行的次数
FIRST_LOAD_TIME ``// 父游标产生的时间戳
PARSE_CALLS ``//解析调用的次数
DISK_CALLS ``//读磁盘的次数
DIRECT_WRITES ``//直接写的次数
BUFFER_GETS ``//直接从buffer中得到数据的次数
APPLICATION_WAIT_TIME ``// 应用等待时间,毫秒
CONCURRENCY_WAIT_TIME ``//并发等待时间,毫秒
USER_IO_WAIT_TIME ``//用户IO等待时间
ROWS_PROCESSED SQL ``//解析sql返回的总行数
OPTIMIZER_MODE ``//优化器模式
OPTIMIZER_COST ``//优化器对于sql给出的成本
PARSING_USER_ID ``//第一个创建这个子游标的用户id
HASH_VALUES ``//解析产生的哈希值
CHILD_NUMBER ``//该子游标的数量
SERVICE ``//服务名
CPU_TIME ``//该子游标解析,执行和获取数据使用的CPU时间,毫秒
ELAPSED_TIME ``//sql的执行时间,毫秒
INVALIDATIONS ``//该子游标的无效次数
MODULE ``//第一次解析该语句时,通过DBMS_APPLICAITON_INFO.SET_ACTION设置的模块名
ACTION ``//第一次解析该语句时,通过DBMS_APPLICAITON_INFO.SET_ACTION设置的动作名
IS_OBSOLETE ``//标记该子游标过期与否,当子游标过大时会发生这种情况
is_bind_sensitive ``//不仅指出是否使用绑定变量窥测来生成执行计划,而且指出这个执行计划是否依赖于窥测到的值。如果是,这个字段会被设置为Y,否则会被设置为N。
is_bind_aware ``//表明游标是否使用了扩展的游标共享。如果是,这个字段会被设置为Y,如果不是,这个字段会被设置为N。如果是设置为N,这个游标将被废弃,不再可用。
is_shareable ``//表明游标能否被共享。如果可以,这个字段会被设置为Y,否则,会被设置为N。如果被设置为N,这个游标将被废弃,不再可用。
v$sqlarea的字段定义和v$sql基本一致,不同的是VSQLAREA是在父游标级别上统计的sql信息,vsql的汇总表,进行了group by hash_value,sql_id的汇总。
8、数据较大 插入优化
1、alter table tb nologging --若是归档模式下,将表设置为不记录日志
2、drop index index_name.....--若表上有index,先删除表上的index
3、insert /*+append*/ into tb ..... --执行插入
4、create index index_name on .....--重建index
5、alter table tb logging --回复日志记录功能
9、数据查询优化
not exists
改为left join where中判断主键为空即可。
select A.* from A left join B on A.ID=B.ID
where B.ID is null;
10、表分区
1.基本实例
例一:按照值大小创建分区
CREATE TABLE CUSTOMER
(
CUSTOMER_ID NUMBER NOT NULL PRIMARY KEY,
FIRST_NAME VARCHAR2(30) NOT NULL,
LAST_NAME VARCHAR2(30) NOT NULL,
PHONE VARCHAR2(15) NOT NULL,
EMAIL VARCHAR2(80),
STATUS CHAR(1)
)
PARTITION BY RANGE (CUSTOMER_ID)
(
PARTITION CUS_PART1 VALUES LESS THAN (100000) TABLESPACE CUS_TS01,
PARTITION CUS_PART2 VALUES LESS THAN (200000) TABLESPACE CUS_TS02
);
例二:按时间划分
CREATE TABLE ORDER_ACTIVITIES
(
ORDER_ID NUMBER(7) NOT NULL,
ORDER_DATE DATE,
TOTAL_AMOUNT NUMBER,
CUSTOTMER_ID NUMBER(7),
PAID CHAR(1)
)
PARTITION BY RANGE (ORDER_DATE)
(
PARTITION ORD_ACT_PART01 VALUES LESS THAN (TO_DATE('01- MAY -2003','DD-MON-YYYY')) TABLESPACEORD_TS01,
PARTITION ORD_ACT_PART02 VALUES LESS THAN (TO_DATE('01-JUN-2003','DD-MON-YYYY')) TABLESPACE ORD_TS02,
PARTITION ORD_ACT_PART02 VALUES LESS THAN (TO_DATE('01-JUL-2003','DD-MON-YYYY')) TABLESPACE ORD_TS03
);
例三:MAXVALUE
CREATE TABLE RANGETABLE
(
idd INT PRIMARY KEY ,
iNAME VARCHAR(10),
grade INT
)
PARTITION BY RANGE (grade)
(
PARTITION part1 VALUES LESS THEN (1000) TABLESPACE Part1_tb,
PARTITION part2 VALUES LESS THEN (MAXVALUE) TABLESPACE Part2_tb
);
——在表上执行查询
select * from RANGETABLE;
——在表分区上执行查询
select * from RANGETABLE partition(part1);
2.列表分区(LIST)
该分区的特点是某列的值只有几个,基于这样的特点我们可以采用列表分区。创建一个按字段数据列表固定可枚举值分区的表。插入记录分区字段的值必须在列表中,否则不能被插入。
例一:
CREATE TABLE PROBLEM_TICKETS
(
PROBLEM_ID NUMBER(7) NOT NULL PRIMARY KEY,
DESCRIPTION VARCHAR2(2000),
CUSTOMER_ID NUMBER(7) NOT NULL,
DATE_ENTERED DATE NOT NULL,
STATUS VARCHAR2(20)
)
PARTITION BY LIST (STATUS)
(
PARTITION PROB_ACTIVE VALUES ('ACTIVE') TABLESPACE PROB_TS01,
PARTITION PROB_INACTIVE VALUES ('INACTIVE') TABLESPACE PROB_TS02
);
例二:
CREATE TABLE ListTable
(
id INT PRIMARY KEY ,
name VARCHAR (20),
area VARCHAR (10)
)
PARTITION BY LIST (area)
(
PARTITION part1 VALUES ('guangdong','beijing') TABLESPACE Part1_tb,
PARTITION part2 VALUES ('shanghai','nanjing') TABLESPACE Part2_tb
);
3.哈希分区(散列分区)(HASH)
利用字段hash值进行分区,是对于未知数据量大小,或者说无法明确分区方法的情况下可以相对较平均的对数据进行分区的方法。
例一:
CREATE TABLE HASH_TABLE
(
COL NUMBER(8),
INF VARCHAR2(100)
)
PARTITION BY HASH (COL)
(
PARTITION PART01 TABLESPACE HASH_TS01,
PARTITION PART02 TABLESPACE HASH_TS02,
PARTITION PART03 TABLESPACE HASH_TS03
)
简写:
CREATE TABLE emp
(
empno NUMBER (4),
ename VARCHAR2 (30),
sal NUMBER
)
PARTITION BY HASH (empno) PARTITIONS 8
STORE IN (emp1,emp2,emp3,emp4,emp5,emp6,emp7,emp8);
4.已建表的分区处理
alter table ea_jc_step_basicinfo_sw add PARTITION BY HASH (COL)
(
PARTITION PART01 TABLESPACE HASH_TS01,
PARTITION PART02 TABLESPACE HASH_TS02,
PARTITION PART03 TABLESPACE HASH_TS03
);
5.分区查询
显示数据库所有分区表的信息:DBA_PART_TABLES显示当前用户可访问的所有分区表信息:ALL_PART_TABLES显示当前用户所有分区表的信息:USER_PART_TABLES显示表分区信息 显示数据库所有分区表的详细分区信息:DBA_TAB_PARTITIONS显示当前用户可访问的所有分区表的详细分区信息:ALL_TAB_PARTITIONS显示当前用户所有分区表的详细分区信息:USER_TAB_PARTITIONS显示子分区信息 显示数据库所有组合分区表的子分区信息:DBA_TAB_SUBPARTITIONS显示当前用户可访问的所有组合分区表的子分区信息:ALL_TAB_SUBPARTITIONS显示当前用户所有组合分区表的子分区信息:USER_TAB_SUBPARTITIONS显示分区列 显示数据库所有分区表的分区列信息:DBA_PART_KEY_COLUMNS显示当前用户可访问的所有分区表的分区列信息:ALL_PART_KEY_COLUMNS显示当前用户所有分区表的分区列信息:USER_PART_KEY_COLUMNS显示子分区列 显示数据库所有分区表的子分区列信息:DBA_SUBPART_KEY_COLUMNS
--查看当前用户的分区表信息;
select * from USER_PART_TABLES;
--查看数据库所有分区表信息;
select * from dba_part_tables;
--查看表的全部分区详细信息
select * from ALL_TAB_PARTITIONS t
where t.table_name ='TABLE_NAME';
