




一、Spark
1、Spark的简介
(官网:http://spark.apache.org)
spark 中文官网:http://spark.apachecn.org/
Spark 是一种快速、通用、可扩展的大数据分析引擎,2009 年诞生于加州大学伯克利分校AMPLab,2010 年开源,2013 年 6 月成为 Apache 孵化项目,2014 年 2 月成为 Apache顶级项目。目前,Spark 生态系统已经发展成为一个包含多个子项目的集合,其中包含SparkSQL、Spark Streaming、GraphX、MLlib 等子项目,Spark 是基于内存计算的大数据并行计算框架。Spark 基于内存计算,提高了在大数据环境下数据处理的实时性,同时保证了高容错性和高可伸缩性,允许用户将 Spark 部署在大量廉价硬件之上,形成集群。
Spark是一个弹性的分布式运算框架,作为一个用途广泛的大数据运算平台,Spark允许用户将数据加载到cluster集群的内存中储存,并多次重复运算,非常适合用于机器学习算法。
Spark的核心是RDD(Resilient Distributed Dataset)弹性分布式数据集,RDD能与其他系统兼容,也可以导入外部储存系统的数据集,例如HDFS、HBase或其他Hadoop数据源。
Spark在运算时,将中间产生的数据暂存在内存中,因此可以加快运行速度,Spark在内存中运行命令比Hapdoop MapReduce命令运行速度快100倍(硬盘上快10倍)。
Spark的主要功能模块有:Spark SQL DataFrame、Spark Streaming、Mllib(machine learning)、GraphX。
Spark SQL DataFrame:Spark SQL 兼容SQL查询语言,DataFrame具有Schema(定义字段名与数据类型),可使用类SQL方法,例如select(),使用上比RDD更方便。
Spark Streaming:可实现实时的数据串流的处理,具有大数据量、容错性、可扩充性等特点。
GraphX:分布式图形处理,可用于图表计算。
Spark MLlib:可扩充性机器学习库。
2、Spark数据处理
(1)Spark数据处理的方式主要有3种:RDD、DataFrame、Spark SQL。
(2)三者主要的差异在于是否定义Scheme
RDD 的数据未定义Scheme(也就是未定义字段名及数据类型),使用上必须有Map/Reduce的概念,需要高级程序设计,同时功能最强,能完成所有Spark功能。
Spark DataFrame 建立时必须定义Schema(也就是定义字段名及数据类型)。
Spark SQL 是由DataFrame衍生出来的,必须先建立DataFrame,然后通过登录Spark SQL temp table,就可以使用Spark SQL语法了。
DataFrame与Spark SQL通过Cataly进行最优化,可以大幅度提高执行效率。基于Python使用RDD速度慢于基于Scala使用RDD。Spark Python 使用DataFrame执行性能与Spark Python相当,且二者运行速度都比RDD快。
易使用度:Spark SQL > DataFrame > RDD。
DataFrame 与 Spark SQL 比RDD更快速。
3、为什么使用Python结合Spark机器学习及大数据开发
(1)目前Spark支持Scala,Python,Java,R:
Scala是Spark开发语言,与Spark兼容性最好,执行效率也最高,但数据分析使用Scala较少,学习门槛较Python高。
Java作为常用的程序设计语言,运用很广泛;但使用Java开发Spark相同功能,语句较长,数据分析师不熟悉Java。
R语言是数据分析很常用的语言,但目前Spark的R语言功能不完整,由于R专注于数据分析,没有其他程序设计模块(爬虫等)。
Python同样是数据分析很常用的语言,代码简洁易学、高生产力,同时也是面向对象、函数式的动态语言,并且有很多数据分析相关的强大的功能库和模块。
(2)Python Spark机器学习
Python目前有许多机器学习库以及基于Python的机器学习框架Scikit-learn、Tensorflow等,而面对海量大数据处理时,就必须结合分布式存储以及分布式计算。
Python结合Spark,可以使用HDFS分布式存储大量数据,还可以在集群(Spark stand alone、Hadoop YARN、Mesos)上执行分布式计算。
(3)Spark机器学习主要有两个API:
【1】 Spark MLlib: RDD-based 机器学习 API
以RDD为基础的机器学习模块,优点是可以发挥in-memory与分布式运算,大幅度提升需要迭代的机器学习模块的执行效率,功能强大。
【2】 Spark ML pipeline: Dataframes-based 机器学习 API
Dataframe:Spark 受Pandas程序包启发所设计的数据处理架构。
Spark ML Pipeline:Spark受Scikit-learn程序包启发设计的机器学习架构。
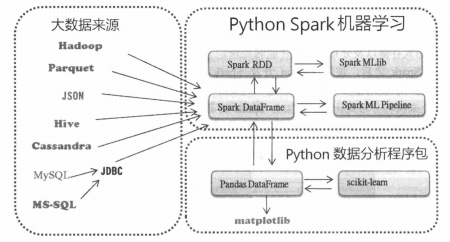
Spark Dataframe 与 Pandas Dataframe 可以互相转换,带来极大方便:例如:数据读取->Spark Dataframe -> Spark ML Pipeline 机器学习->返回Spark Dataframe -> 转化为Pandas Dataframe->使用Python其他模块(matplotlib)进行数据分析。
Spark Dataframe 提供的API可以轻松读取大数据的各种数据源:Hadoop、Parquet、JSON等,还可以通过JDBC读取关系数据库,例MySQL等。
4、 spark 的部署模式:
local 本地模式,只要机器上有 spark 的安装包, 仅仅是用于测试不写 master -- master local 一个线程 local[2] local[\*] 模拟使用多个线程。
Standalone spark 自带的集群模式 --master spark://hdp-01:7077。
yarn 把 spark 任务,运行在 yarn --master yarn。
mesos 把 spark 任务,运行在 mesos 资源调度平台上 --master mesos。
5、Spark 特点
【1】 快
【2】 易用
【3】 通用
【4】兼容性
二、Hadoop
1、 Hadoop及其特性
Hadoop是存储与处理大数据的平台。具有可扩展性(Scalable)、经济性(Economical)、弹性(Flexible)及可靠性(Reliable):
可扩展性(Scalable):Hadoop采用分布式计算与存储,当扩充容量或运算时,不需要更换整个系统,只需要增加新的数据节点服务器即可。
经济性(Economical):Hadoop采用分布式计算与存储,不必使用昂贵高端的服务器,只需一般等级的服务器就可架构出高性能、高容量的集群。
弹性(Flexible):传统关系型数据库存储数据时必须有数据表结构schema(各个数据对象的集合),Hadoop存储的数据是非结构化(schema-less)的,可以存储各种形式、不同数据源的数据。
可靠性(Reliable):Hadoop采用分布式架构,当某台服务器(甚至整个机架)坏掉,HDFS仍可正常运行,数据有两个另外的副本。
Hadoop采用分布式文件系统(Hadoop Distributed File System),可以由单台服务器扩充到数千台服务器。
2、HDFS分布式文件系统
(1)HDFS分布式文件系统中,NameNode服务器负责管理与维护HDFS目录系统并控制文件的读写操作。多个DataNode服务器负责存储数据。
(2)HDFS设计的前提与目标:
硬件故障是常态而不是异常(Hardware Failure)
HDFS是设计运行在低成本的普通服务器上,硬件故障是常态,而不是异常,所以HDFS被设计成具有高度容错能力、能够实时检测错误并且自动恢复,这是HDFS核心的设计目标。
Streaming流式数据存取(Streaming Data Access)
运行在HDFS上的应用程序会通过Streaming存取数据集。HDFS的主要设计是批处理,而不是实时互动处理,优点是可以提高存取大量数据的能力,但是牺牲了响应时间。
大数据集(Large Data Sets)
为了存储大数据集,HDFS提供了cluster集群架构,用于存储大数据文件,集群可扩充数百个节点。
简单一致性模型(Simple Coherency Model)
HDFS 的存取模式是一次写入多次读取,一个文件被创建后就不会再修改。该设计优点是提高存储大量数据的能力,并简化数据一致性问题。
移动“计算”比移动“数据”成本更低(Moving Computation is Cheaper than Moving Data)
搬移数据耗费大量时间成本,因此需要计算数据时,将计算功能在接近数据服务器中运行而不是搬移数据。
跨硬件与软件平台
HDFS在设计时就考虑到平台的可移植性。
(3)HDFS文件存储架构: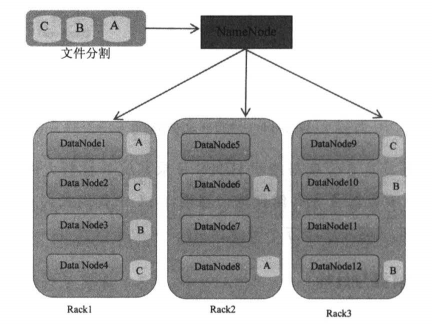
【1】文件分割:
当用户以HDFS命令要求存储文件时,系统会将文件切割为多个区块(Block),每个区块为64MB,上图文件被分割为A、B、C共3个区块。
【2】区块副本策略:
一个文件区块默认会复制成3份,也可以设置文件区块创建几个副本。
文件区块损坏时,NameNode会自动寻找位于其他DataNode上的副本来恢复数据,维持3份的副本策略。
【3】机架感知:
上图,有Rack1,Rack2,Rack3共3个机架,每个机架都有4台DataNode服务器。
HDFS具有机架感知功能,以Block C为例:第一份副本放在Rack1机架的节点,第二份放在同机架Rack1的不同节点,最后一份放在不同机架Rack3的不同节点
这样设计的好处是防止数据遗失,有任何机架出现故障时,仍可以保证恢复数据,提高网络性能。
3、Hadoop Map Reduce的介绍
(1)利用大数据进行数据分析处理时,数据量庞大,所需运算量也巨大。Hadoop MapReduce 的做法是采用分布式计算的技术:
Map将任务分割成更小任务,由每台服务器分别运行。
Reduce将所有服务器运算结果汇总整理,返回最后的结果。
(2)通过MapReduce方式,可以在上千台机器上并行处理巨量的数据,大大减少数据处理的时间。
(3)MapReduce 版本2.0 YARN
Hadoop的MapReduce架构称为YARN(Yet Another Resource Negotiator,另一种资源协调者)是效率更高的资源管理核心。
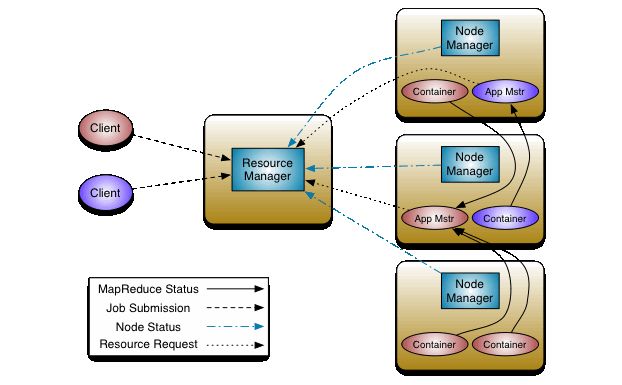
上图中,在Client客户端,用户向Resource Manager请求执行运算(或执行任务)。
在NameNode会有Resource Manager统筹管理运算的请求。
在其他DataNode 会有Node Manageer负责运行,以及监督每一个任务(task),并且向Resource Manager汇报状态。
(4)Hadoop MapReduce的计算框架
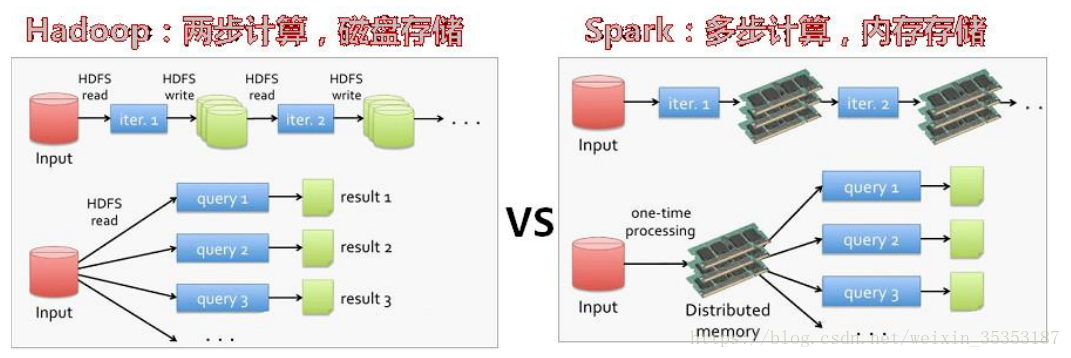
Hadoop MapReduce 在运算时需要将中间产生的数据储存在硬盘中,由于磁盘I/O性能问题,因此会有读写数据延迟的问题。
而Spark是基于内存的计算框架,不会有磁盘I/O读写数据延迟的问题,可以大幅度提升性能。
三、Spark 和 Hadoop 的主要不同点
(1)mapreduce 读 – 处理 - 写磁盘 -- 读 - 处理 - 写
(2)spark 读 - 处理 - 处理 --(需要的时候)写磁盘 - 写
(3)Spark 是在借鉴了 MapReduce 之上发展而来的,继承了其分布式并行计算的优点并改进了 MapReduce 明显的缺陷,(spark 与 hadoop 的差异)具体如下:
首先,Spark 把中间数据放到内存中,迭代运算效率高。MapReduce 中计算结果需要落地,保存到磁盘上,这样势必会影响整体速度,而 Spark 支持 DAG 图的分布式并行计算的编程框架,减少了迭代过程中数据的落地,提高了处理效率。(延迟加载)
其次,Spark 容错性高。Spark 引进了弹性分布式数据集 RDD (Resilient DistributedDataset) 的抽象,它是分布在一组节点中的只读对象集合,这些集合是弹性的,如果数据集一部分丢失,则可以根据“血统”(即允许基于数据衍生过程)对它们进行重建。另外在RDD 计算时可以通过 CheckPoint 来实现容错。
最后,Spark 更加通用。mapreduce 只提供了 Map 和 Reduce 两种操作,Spark 提供的数据集操作类型有很多,大致分为:Transformations 和 Actions 两大类。Transformations包括 Map、Filter、FlatMap、Sample、GroupByKey、ReduceByKey、Union、Join、Cogroup、MapValues、Sort 等多种操作类型,同时还提供 Count, Actions 包括 Collect、Reduce、Lookup 和 Save 等操作。
(4)Spark支持的运算平台,支持的开发语言更多。
Spark 4 种开发语言:scala,java,python,R
(5)总结:Spark 是 MapReduce 的替代方案,而且兼容 HDFS、Hive,可融入 Hadoop 的生态系统,以弥补 MapReduce 的不足。
参考资料
林大贵:Python+Spark+Hadoop机器学习与大数据实战
刘鹏:云计算(第三版)
百度:百度公开PPT、百度图片资源
Hadoop、spark官方文档

