




还是继续JAVA NIO2的旅程,本文讲述的内容是如何对于文件和目录进行访问,并且在文件访问的时候做一下手脚;
1.访问者模式
首先,来看看访问者模式,这个模式可谓是设计模式中最复杂最难以理解的模式;
其实,我觉得不然,因为主要你就是没有场景,如果有一个场景的话,我相信非常容易理解,先上类图:
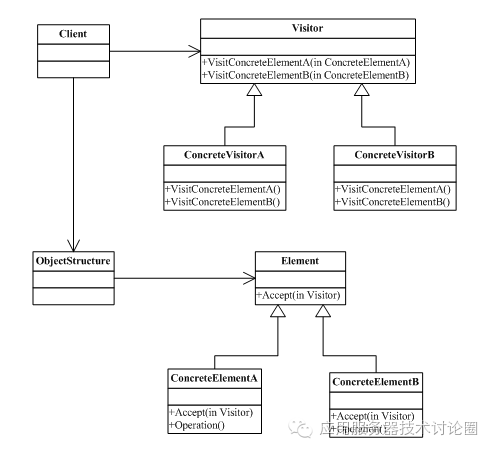
两类事物,
一类是访问者,访问者抽象层有一些接口方法需要实现,你可以写各种访问者的实现,该策略的各种逻辑的访问的变化,
一类是要访问的对象,这类一般是有层级的结构或者有一些规律可循的,如图,树,文件系统的遍历等等;
访问者主要的意图是什么?
设计模式讲究开放和封闭,对于要访问的对象,我想做个类,如上图中的Element对象,因为数据结构基本就是固定的,没什么可变化的,但我想基于这个数据结构做一些文章,例如访问之前干点啥,访问的时候改改东西,访问后又干点啥,当访问出异常的时候干点啥,等等各种场景,这些场景有点类似于AOP切面的这种感觉;
而之所以访问者模式牛,牛就在于基于上述的需求,数据结构抽象出来的Element类,我可以保证不发生变化,那么变的这些动作,我给其抽取出来,你不是变吗?那好,不变的是Element类不动,变的Visitor访问者你随便写;
再仔细看看上图,这个模式最经典的地方在Element中的Accept(Visitor)这个方法中,在Element的Operation的主逻辑中,会内置Visitor的各种需要扩展的方法,在流程中,但因为都是基于接口编程,所以没有具体的实现;而回过头来看看Visitor的这些方法的实现,正式不同的Visitor实现,才赋予这个流程以不同的动作和变化,这才是访问者最经典的之处;
2.FileVisitor
再看看java.nio.file包中的这个FileVistor,你就会明白了,这个实际上和上面的这个访问者模式是一样的;
文件目录层级就是树状的,这个是不变的,也就是说数据结构我们不能进行修改了,但我要在访问这些文件的时候做一些操作,如增删改查,或者打印一些文件信息等各种操作,那我就需要类似于AOP一样的放出一些切面方法出来,例如下面的这个自定义的Visitor的实现:

AOP的这几个方法都在上面的定义中;
preVisitDirectory是访问前,visitFile是访问,postVisitDirectory是访问后,
visitFileFailed是访问失败;
我们可以看到,上述的逻辑就是在访问的时候打个日志而已;
看看怎么调用的:
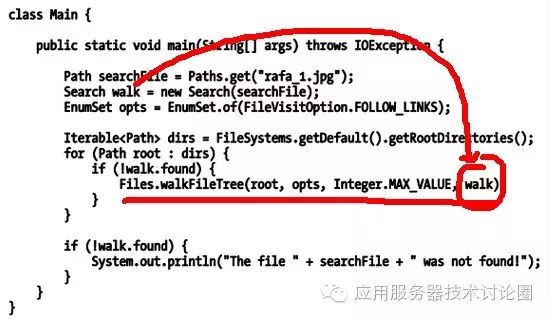
主要是上述的Files.walkFileTree这个方法,这个方法就类似于访问者模式中的Operation方法,也就是主要业务逻辑,它所要分离的都在FileVistor中进行定义,我们分解一下JAVA API的源码,看看这个walkFileTree方法源码是怎么写的;
Files类的walkFileTree,在其类内部启动一个内部类FileTreeWalker,将这个FileVistor作为实例传入进去:
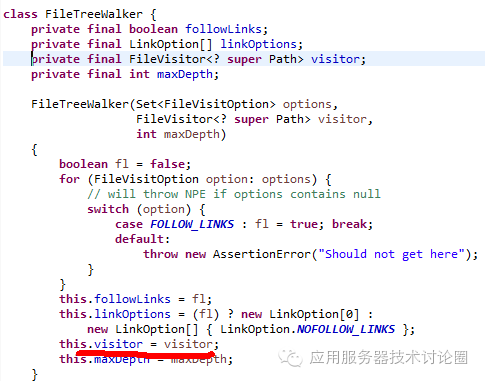
我们需要关注这个内部类FileTreeWalker的walk方法,这是主要的实现:
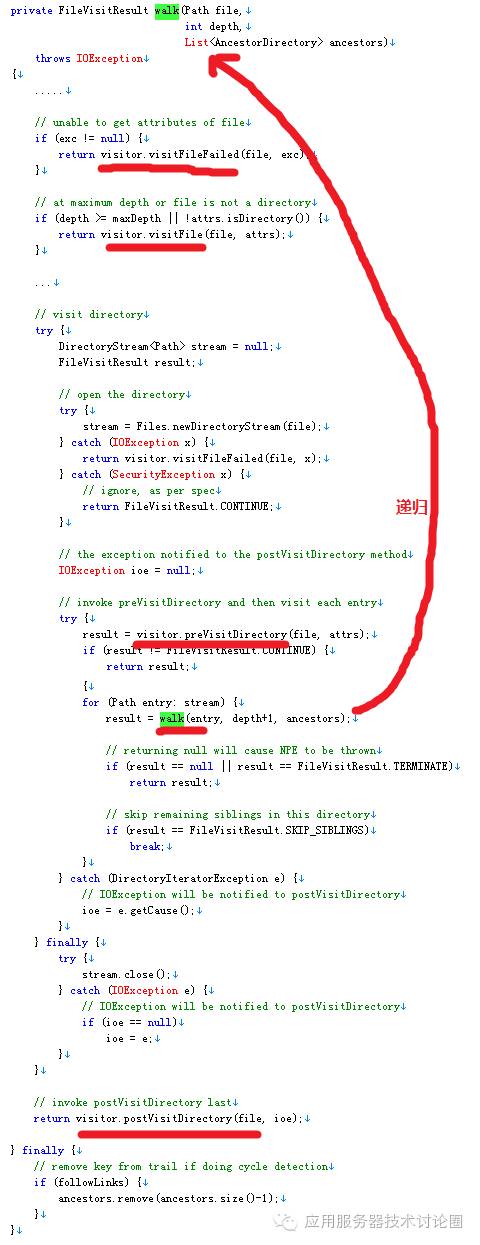
上述代码中最重要的是递归这个思路,这也是类似于图,树这种带有层次结构的必须得用递归,每一次递归都拿到一个file,然后通过Files.newDirectoryStream(file)获得这个流,当发现其下面还有目录的话,继续进行递归;
在迭代递归遍历文件的过程中,上述的这些访问者的方法 preVisitDirectory,visitFile,postVisitDirectory,visitFileFailed 都会被触发,而这些访问者的实现留有空间是非常大的,这也是基于接口编程的好处;
在上述的程序中,基于每一次的walk会有很多的访问状态,这些访问状态,标识着是继续访问,还是跳过等等:

FileVisitResult.CONTINUE:继续访问,从源码分析看出,当访问没有异常,肯定是继续访问;
FileVisitResult.TERMINATE:当访问到最后一个结束了,标识这次访问完成;
FileVisitResult.SKIP_SIBLINGS:这个属性是需要设置标识到walk方法中的,如果设置了,在walk的实现中,可以不考虑跳过兄弟节点;
FileVisitResult.SKIP_SUBTREE:这个属性和FileVisitResult.SKIP_SIBLINGS差不多,当设置了之后,跳过子树,不进行访问;
3.一个高级内容查询的例子
利用这个FileVisitor,我们可以做更多的事情,例如沿着这个文件查询的思路走,我们甚至可以对文件的内容进行搜索,有下面的程序:


这个FileVistor定义的非常长,其主要思路就是搜索文本的内容,因为文本有不同的类型,对内容进行查找和匹配,需要用到不同的包来做:
excel:使用poi的包进行解析
word:poi包
ppt:poi包
pdf:pdfbox解析
txt:逐个字节进行读取
所以,上述的FileVistor的实现才会引入不同的开源的包来做这个事;
最后看看,怎么调用的吧:
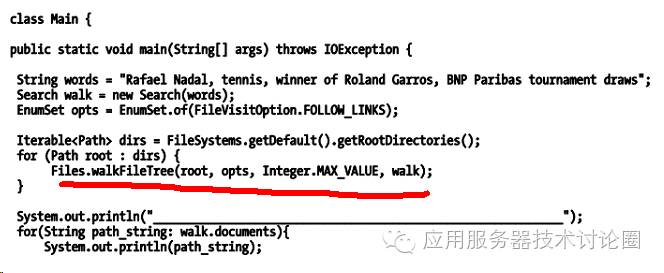
这样就能完成了一个基本的文件系统的基于pdf,ppt,word,txt,excel的简单搜索了!
总结:
本文从访问者模式开始聊起,java NIO2中FileVistor完全借鉴的是访问者模式,对访问方式进行扩展,本文最后给出一个例子,基于文件系统的文本搜索,就是利用FileVistor的机制来做的!
