




上一章节我们了解Receive是如何处理数据请求的,客户端的remote_write请求到达Receive后,完整的数据扭转链路,这节我本来计划带大家一起了解thanos如何处理数据进行本地存储的?怎么写对象存储的?
由于Thanos使用的是Prometheus的数据存储策略,在没有了解rometheus的TSDB实现策略前实在难以阅读这块代码,所以这一章节将首先带领大家了解rometheus的TSDB实现策略。
指标
例如,Prometheus通过Node Expoter采集上来有关CPU的指标:(这里作为示例,仅列举出4项)
node_cpu_seconds_total{cpu="0",mode=“idle”} 5340.12
node_cpu_seconds_total{cpu="0",mode=“iowaite”} 11.13
node_cpu_seconds_total{cpu="1",mode=“idle”} 4740.34
node_cpu_seconds_total{cpu="1",mode=“iowaite”} 12.10
假设以上指标在 1640185665 这个时间戳采集上来的,那么加上Prometheus会将以上指标转化为 < Sereis, T, V >的结构:
{__name__=”node_cpu_seconds_total",cpu="0",mode=“idle”} 1640185665 5340.12
{__name__=”node_cpu_seconds_total",cpu="0",mode=“iowaite”} 1640185665 11.13
{__name__=”node_cpu_seconds_total",cpu="1",mode=“idle”} 1640185665 4740.34
{__name__=”node_cpu_seconds_total",cpu="1",mode=“iowaite”} 1640185665 12.10
在Prometheus中对于以上指标项,有专业术语对其进行定义,包括:
Label:标签,例如cpu="0"为一组标签,mode=“idle”也为一组标签;
Series:系列,若干个标签组合为一个系列,例如
{name=”node_cpu_seconds_total",cpu="0",mode=“idle”}
,例如案例中的4项称为4个系列更为准确;Index:索引,用于确定Label和Series之间的关系,便于通过Label条件查找对应的series,在后文中将详细讲解;
以下两个概念有关于当指标存储在磁盘中时使用到:
Chunk:数据块,在磁盘中存储的
数据对; meta.json:一个肉眼可读且可理解的json文件,包含时间范围等描述内容
分块存储
早期的TSDB存储采用将一个Series存储在一个文件里,例如:
{__name__=”node_cpu_seconds_total",cpu="0",mode=“idle”}
1640185665 5340.12
1640185695 5340.07
1640185725 5340.09
1640185755 5340.13
通过上述示例可以看出:
每30秒采集一次指标
将这个系列的指标依次按照时间排序存储
这种存储方式带来通过指标的逻辑条件进行查询,以及删除历史数据等难以处理问题。而且当Series特别多时,会大量占用系统文件打开句柄数。
倒排索引
在一个目录中保存了若干个 Series,如果想要通过一个 Label 来查询对应的所有 Series,其实是一个比较麻烦的事情。而Prometheus TSDB通过建立倒排索引来解决这个问题。
Label 查询
例如通过Label__name__=”node_cpu_seconds_total"
查询完整的数据,是如何查找的呢?
例如对于这个Series {__name__=”node_cpu_seconds_total",cpu="0",mode=“idle”}
,其对应的数据结构如下:
| 索引 | series |
|---|---|
__name__=”node_cpu_seconds_total" | {__name__=”node_cpu_seconds_total",cpu="0",mode=“idle”} |
cpu="0" | {__name__=”node_cpu_seconds_total",cpu="0",mode=“idle”} |
mode=“idle” | {__name__=”node_cpu_seconds_total",cpu="0",mode=“idle”} |
例如对于这个Series {__name__=”node_cpu_seconds_total",cpu="1",mode=“idle”}
,其对应的数据结构如下:
| 索引 | series |
|---|---|
__name__=”node_cpu_seconds_total" | {__name__=”node_cpu_seconds_total",cpu="1",mode=“idle”} |
cpu="1" | {__name__=”node_cpu_seconds_total",cpu="1",mode=“idle”} |
mode=“idle” | {__name__=”node_cpu_seconds_total",cpu="1",mode=“idle”} |
定义 {__name__=”node_cpu_seconds_total",cpu="0",mode=“idle”}
的ID为1000
定义 {__name__=”node_cpu_seconds_total",cpu="1",mode=“idle”}
的ID为1001
那么这两个表将会合并为:
| 索引 | series |
|---|---|
__name__=”node_cpu_seconds_total" | [1000,1001] |
cpu="0" | [1000] |
cpu="1" | [1001] |
mode=“idle” | [1000,1001] |
所以通过Label__name__=”node_cpu_seconds_total"
获取到的series为1000,1001,即对应的{__name__=”node_cpu_seconds_total",cpu="0",mode=“idle”}
、 {__name__=”node_cpu_seconds_total",cpu="1",mode=“idle”}
组合Label 查询
按照之前的定义方法
定义 {__name__=”node_cpu_seconds_total",cpu="0",mode=“iowaite”}
的ID为1002
定义 {__name__=”node_cpu_seconds_total",cpu="1",mode=“iowaite”}
的ID为1003
那么:
| 索引 | series |
|---|---|
__name__=”node_cpu_seconds_total" | [1000,1001,1002,1003] |
cpu="0" | [1000,1002] |
cpu="1" | [1001,1003] |
mode=“idle” | [1000,1001] |
mode=“iowaite” | [1002,1003] |
如果查询 cpu="0" and mode=“idle”
,那么对
| cpu="0"
| [1000,1002] |与| mode=“idle”
| [1000,1001] |取交集,则为1000。即为{__name__=”node_cpu_seconds_total",cpu="0",mode=“idle”}
。
同样的其他的逻辑运算符相应的对结果做逻辑运算即可。
WAL
当未达到两个小时的归档时间时,Prometheus在内存中的数据是如何保证重启不会丢失的呢?Prometheus实现了 WAL(write-ahead-log)机制,启动时会以写入日志(WAL)的方式来实现重播,从而恢复数据。
mmap
在Prometheus中将数据进行分块处理,每两个小时的数据存储在一个目录里,且当目录多了还会对历史数据进行合并处理,例如每4小时将两个2小时的合并成一个4小时的数据,每8小时将两个4小时的合并成一个8小时的数据,以此类推。
这样当我要读取某个时间段的数据时,不需要将所有数据一次加载至内存判断,直接跳过对应时间(存储块)的文件夹即可。
那么或许有人会说,当时间足够久,一样的磁盘文件数量会很多,所以Prometheus不主张留存太久的历史指标数据,而且用户查看历史指标的概率也比较小,可通过storage.tsdb.retention.time
启动参数指定数据保留时长,默认为15d(15天)
过程图解
当一个新的样本到来,它将被写入到“活跃 chunk”(红色块)中。且为保证在内存中的数据不会因为重启而丢失,在写chunk前会先写日志记录,便于在后期恢复数据。
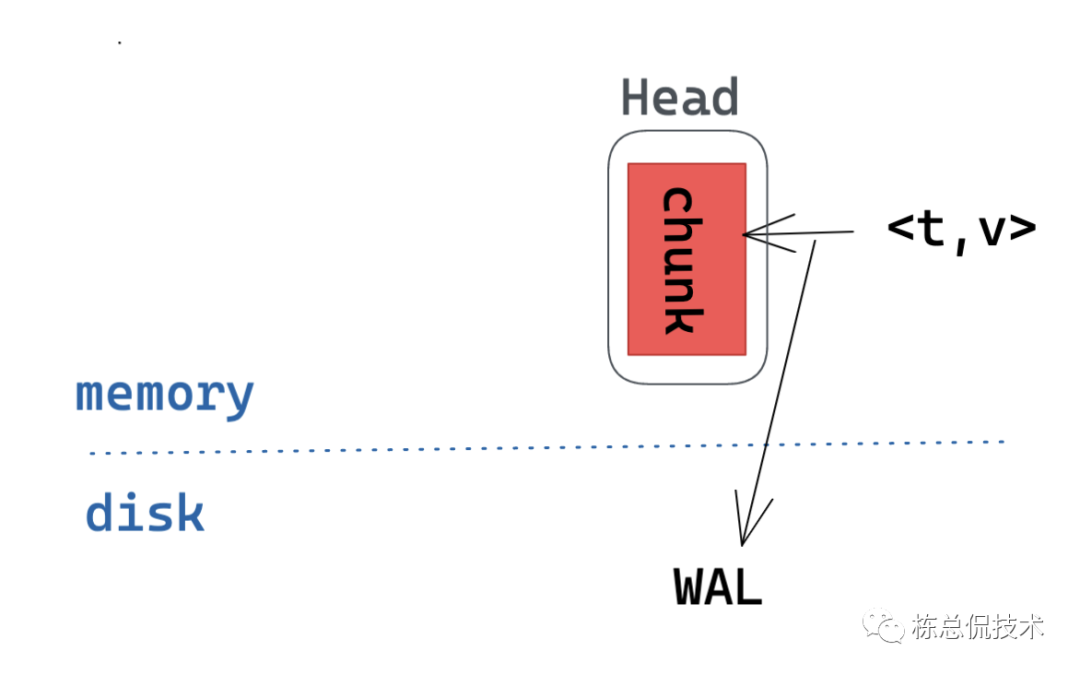
当一个chunk达到120个样本或者写入时间达到了2小时,则会创建一个新的chunk(黄色的1),同时将老的chunk写入磁盘。
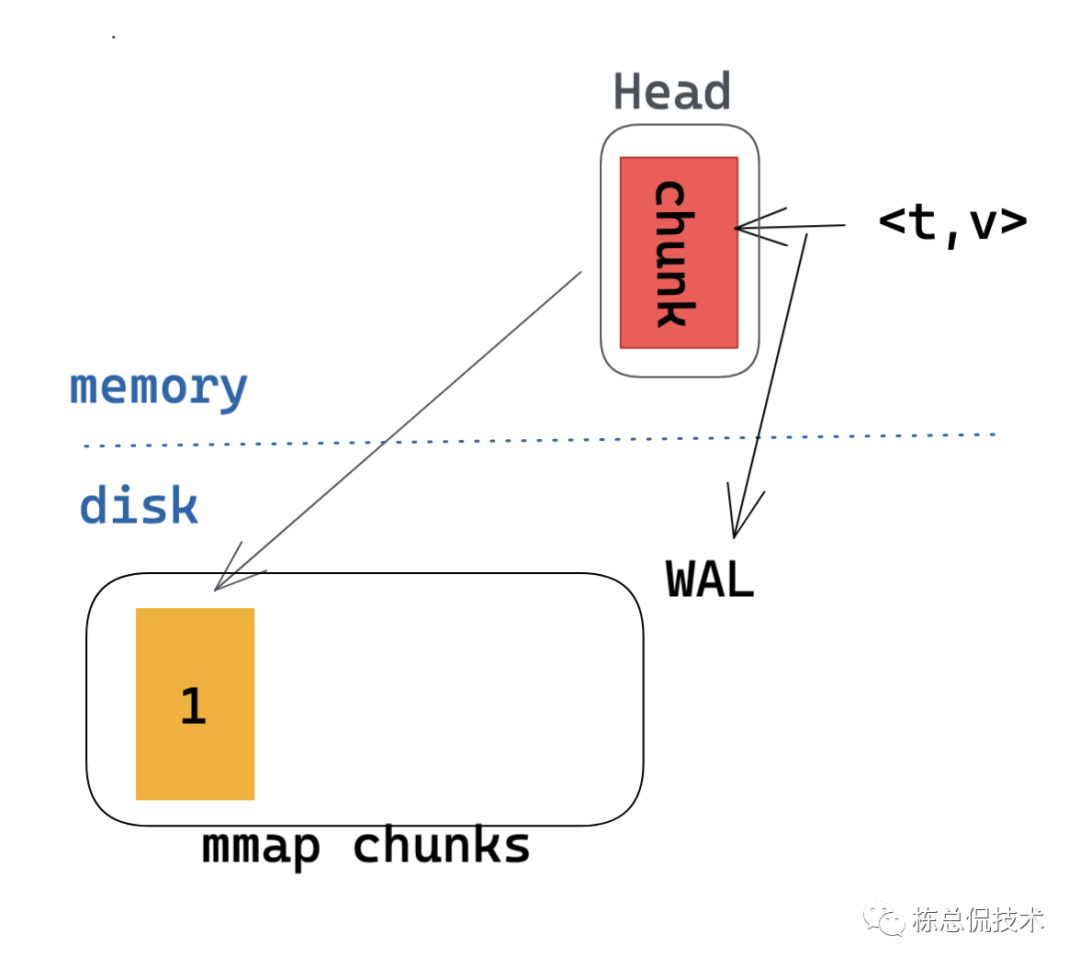
此后,随着更多的指标写入,将会在磁盘产生更多的chunks。
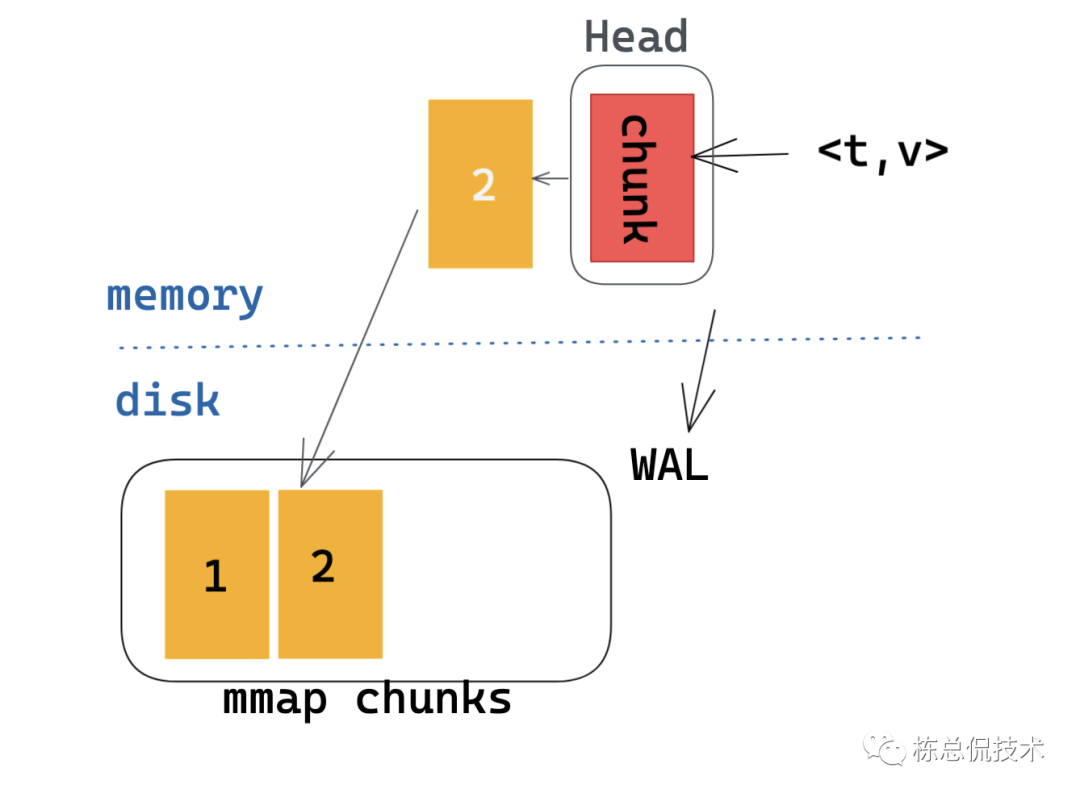
每两个小时会将这个区间内的所有chunks压缩为一个block持久块。
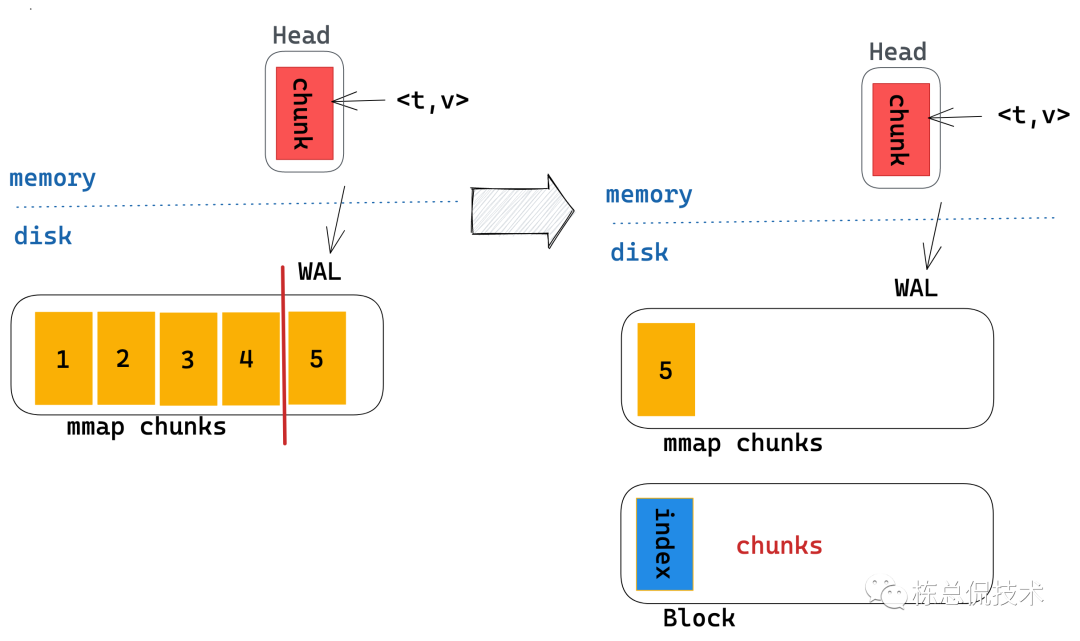
以上为Prometheus的TSDB详细过程,下届将基于此节内容基础来理解Thanos围绕着TSDB做了哪些工作。
本系列回顾:
