




分区表逻辑上是一个表,但物理存储是多个segment。
分区表的本地索引逻辑上是一个索引,但物理存储是多个segment。 本地索引的索引分区和表分区是一一对应的。
分区的好处
- 按分区删除无用数据比delete快得多
- 空分区insert效率高
- 分区裁剪、数据隔离提升查询效率
分区的分类和使用场景
| 分区类型 | 类型说明 | 适用场景 | 示例 |
|---|---|---|---|
| Range | 用户创建分区,分 区键大小从小到 大,不能往中间插 入新分区,分区键 一般是date或number类型 | 适用日志、流水类大 表,需要根据时间删 除历史数据 | CREATE TABLE WSR$_LONGSQL1 ( SNAP_ID BINARY_INTEGER NOT NULL, CTIME DATE ) PARTITION BY RANGE(SNAP_ID) (PARTITION P_0 VALUES LESS THAN (1)); |
| Interval | 用户只需要设定分 区间隔和初始分区 键值,根据插入的 数据自动生成对应 的分区,分区键一 般是date或 number类型 | 同Range分区,比 Range分区使用更方 便,用户不用提前创 建分区,并且可以有 数据时再创建分区而 不用创建空分区 | CREATE TABLE WSR$_LONGSQL2 ( SNAP_ID BINARY_INTEGER NOT NULL, CTIME DATE ) PARTITION BY RANGE(SNAP_ID) INTERVAL(1) (PARTITION P_0 VALUES LESS THAN (1)); |
| List | 分区键是离散值, 分区需要用户创建 | 适用在分区键是离散 值的场景 | CREATE TABLE WSR$_LONGSQL3 ( SNAP_ID BINARY_INTEGER NOT NULL,CTIME DATE ) PARTITION BY LIST (SNAP_ID) (PARTITION P_0 VALUES (1)); |
| Hash | 用户设定分区键和 分区数,可以自动 生成分区,插入数 据时根据hash算法 选择对应的分区 | 适用于分区键取值非 常多的场景,一般用 于把数据隔离开,而 不是为了根据分区删 除数据,使用hash分 区减少buffer busy wait的等待 | CREATE TABLE WSR$_LONGSQL4 ( SNAP_ID BINARY_INTEGER NOT NULL,CTIME DATE ) PARTITION BY HASH (SNAP_ID) PARTITIONS 16; |
分区的注意事项
| 注意项 | 说明 |
|---|---|
| 查询分区表 | 一般要带分区键查询,并且分区键的查询条件上没有表达 式,如果扫描所有分区可能性能不如不分区 |
| 分区表的开销 | 分区表过多segment和统计信息会增加,内存和磁盘开销 会增大,分区不是越多越好 |
| 创建索引 | 分区索引原则上要创建为local索引,避免删除分区时索引 失效;如果分区内分区键是同一个值,不要在分区键上创 建索引 |
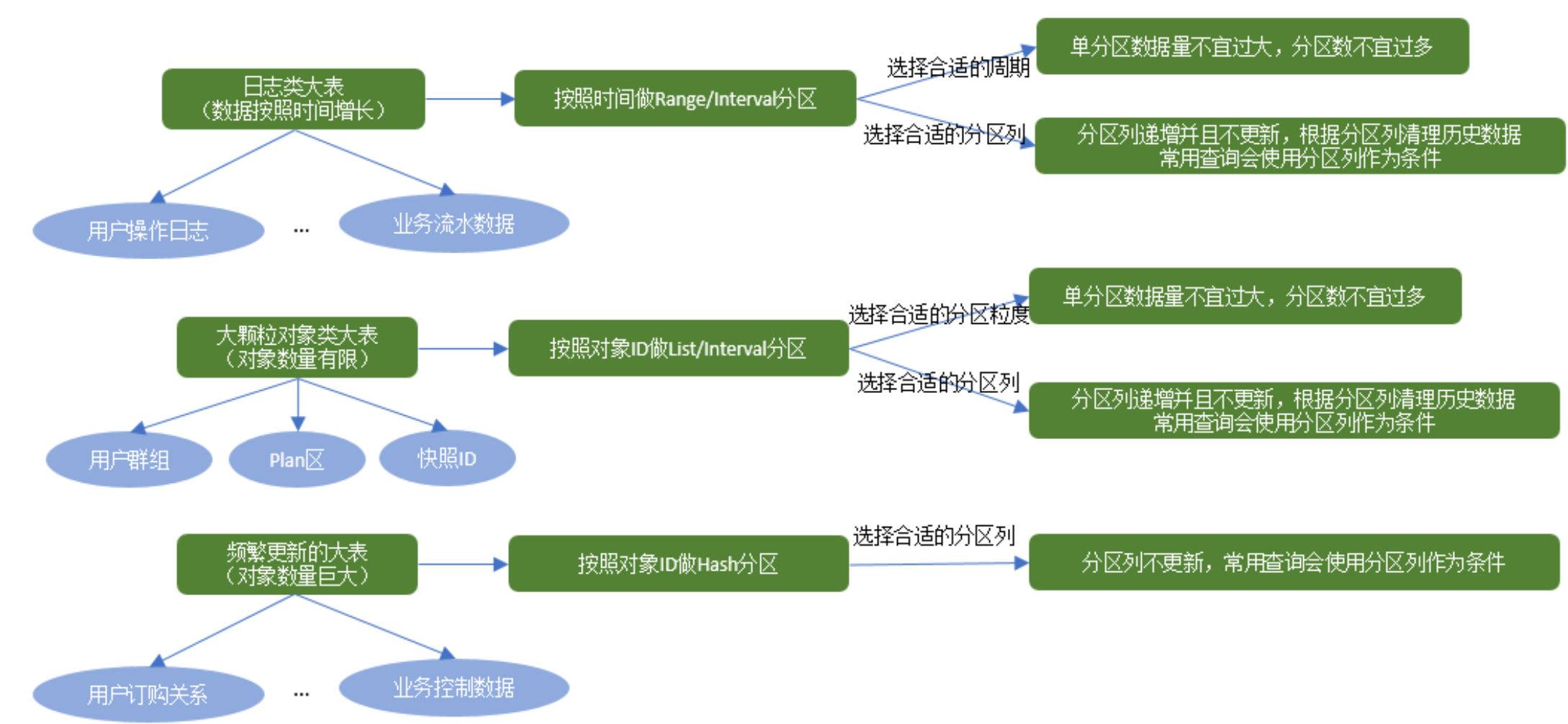
分区的设计要点
「喜欢这篇文章,您的关注和赞赏是给作者最好的鼓励」
关注作者
【版权声明】本文为墨天轮用户原创内容,转载时必须标注文章的来源(墨天轮),文章链接,文章作者等基本信息,否则作者和墨天轮有权追究责任。如果您发现墨天轮中有涉嫌抄袭或者侵权的内容,欢迎发送邮件至:contact@modb.pro进行举报,并提供相关证据,一经查实,墨天轮将立刻删除相关内容。
