





目录
-
原理介绍
-
实例级指标解读
-
SQL指标解读
-
Segment指标解读
-
常见问题分析方法
原理介绍
原理介绍:快照
快照是把数据库的某个时间点的统计数据记录到快照表中,目前已经实现的功能包括:
| 数据类型 | 原始视图 | 快照表 | 对应视图 |
|---|---|---|---|
| 实例级性能统计数据 | DV_SYS_STATS | WRH$_SYSSTAT | DBA_HIST_SYSSTAT |
| 当前操作系统的CPU/MEM使用情况 | DV_SYSTEM | WRH$_SYSTEM | DBA_HIST_SYSTEM |
| 实例级等待事件统计数据 | DV_SYS_EVENTS | WRH$_SYSTEM_EVENT | DBA_HIST_SYSTEM_EVENT |
| SQL 性能统计数据 | DV_SQLS | WRH$_SQLAREA | DBA_HIST_SQLAREA |
| 数据库系统参数 | DV_PARAMETERS | WRH$_PARAMETER | DBA_HIST_PARAMETER |
| Buffer等待事件统计数据 | DV_WAIT_STATS | WSR$_WAITSTAT | DBA_HIST_WAITSTAT |
| LATCH统计数据 | DV_LATCHS | WSR$_LATCH | DBA_HIST_LATCH |
| 数据字典统计数据 | DV_LIBRARY_CACHE | WSR$_LIBRARYCACHE | DBA_HIST_LIBRARYCACHE |
| 段性能统计数据 | DV_SEGMENT_STATS | WSR$_SEGMENT | DBA_HIST_SEGMENT |
| 段大小信息 | ADM_SEGMENTS | WSR$_DBA_SEGMENTS | DBA_HIST_DBASEGMENTS |
| 长SQL和执行计划 | DV_LONG_SQL | WSR$_LONGSQL | DBA_HIST_LONGSQL |
| 会话等待事件 | DV_WAIT_STATS | WSR_WAITSTAT | ADM_HIST_WAITSTAT |
| 正在执行的SQL和会话信息 | DV_SESSIONS | WSR_SESSION_SQL | NA |
| 事务数据 | DV_TRANSACTIONS | WSR_TRANSACTION | NA |
| 对象锁数据 | DV_LOCKED_OBJECTS | WSR_LOCK_OBJECT | NA |
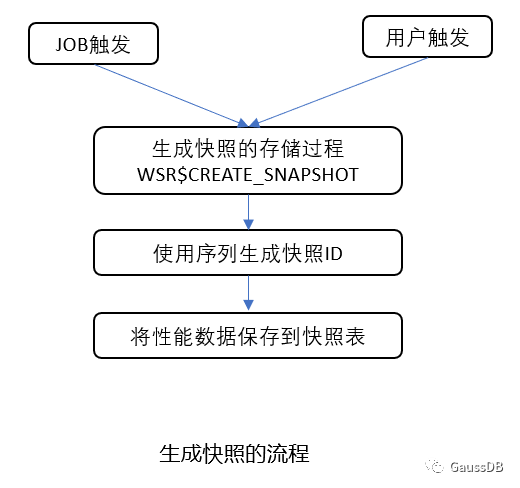
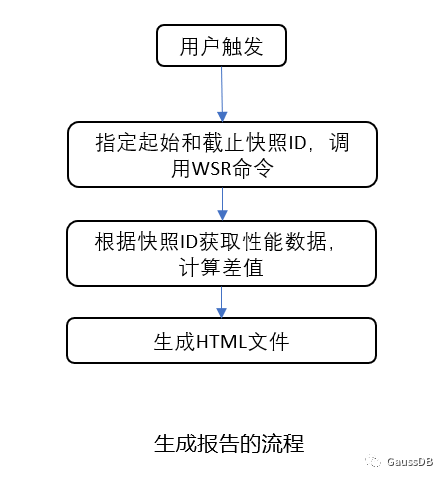
原理介绍:生成快照和报告的流程
实例指标解读
实例级指标解读
| 指标 | 描述 |
|---|---|
| DB Time | 数据库消耗的时间,并发越多,每秒的DB Time越高,该值越高说明数据库负载越重 |
| DB CPU | 数据库CPU消耗的时间,不包括IO等待,该值越高说明CPU负载越重 |
| Redo size | 产生Redo的大小,每秒产生的Redo很多说明DML的负载较大 |
| Redo write time | Redo日志的写入时间,该值很大说明产生的Redo量很大或者IO很差 |
| Redo writes | Redo写入的次数,该值很大说明Redo的buffer过小或者commit频率较高 |
| Logical read | 逻辑读的Page数,该值很大说明数据库扫描的数据较多,CPU压力可能较大 |
| CR gets | 一致读获取CR页面的次数,该值很大说明很多数据需要从回滚段中获取 |
| Page changes | 逻辑写的次数,Page每一次更新都会加1,但不是实际物理写的次数 |
| Physical read | 物理读的次数,该值越高IO压力越大 |
| DBWR disk writes | 物理写的次数,该值越高IO压力越大 |
| DBWR disk write time | 物理写的耗时,该值越高IO压力越大 |
| User calls | 客户端和服务端的交互次数,包括fetch |
| SQL parse time | SQL编译时间 |
| Parses | SQL解析的次数,包括软解析和硬解析 |
| Hard parses | SQL硬解析的次数 |
| Logons | 获取数据库连接的次数 |
| Executes | SQL执行的次数 |
| Rollbacks | SQL回滚的次数 |
| Transactions | 事务的个数 |
| Select executions | Select语句的执行次数 |
| Select execution time | Select语句的执行时间 |
| Insert executions | Insert语句的执行次数 |
| Insert execution time | Insert语句的执行时间 |
| Update executions | Update语句的执行次数 |
| Update execution time | Update语句的执行时间 |
| Delete executions | Delete语句的执行次数 |
| Delete execution time | Delete语句的执行时间 |
| Fetched counts | 执行fetch的次数 |
| Fetched rows | Fetch返回的数据条数 |
| Processed rows | SQL语句操作的数据量:select返回的结果;insert、update、delete操作的结果 |
| Sorts | 排序的次数 |
| Sort on disk | 硬盘排序的次数 |
| Buffer Nowait | 申请Buffer不用等待的比例,正常应该接近100% |
| Redo NoWait | 生成redo entry时不用等待的比例,正常应该接近100% |
| Buffer Hit | Data Buffer的命中率,正常应该接近100% |
| In-memory Sort | 内存排序的比例,正常应该接近100% |
| Library Hit | 访问数据字典在内存中的命中率,正常应该接近100% |
| Soft Parse | SQL软解析的比例,正常应该接近100% |
| Execute to Parse | 不需要Parse的比例,该比例越高越好 |
| Latch Hit | Latch 是在buffer cache中的低级锁,并发的情况下你可能一次请求不到你想要的buffer就会有miss,如果100%的话说明你没有热block竞争 |
| Parse CPU to Parse Elapsd | SQL Parse时间中CPU的比例,正常应该接近100% |
| Non-Parse CPU | CPU扣除Parse后的比例,正常应该接近100% |
常见等待事件
| 等待事件 | 说明 |
|---|---|
| db file sequential read | 随机读等待,一般是由于索引扫描导致的物理读 |
| db file scattered read | 顺序读等待,一般是由于全表扫描导致的物理读 |
| log file sync | redo写等待,一般是由于commit过于频繁导致的 |
| log file switch (checkpoint incomplete) | Redo log file太小了,导致日志需要切换时,前一个日志的数据还没有完全写到数据文件中 |
| enq: TX - contention | 事务锁等待,由于并发对相同的数据做DML操作导致 |
| read by other session | SQL需要访问的数据块正在被另一个会话从磁盘读到内存中 |
| buffer busy wait | SQL需要访问的数据块正在被另一个会话做写操作 |
服务器CPU和内存
| 分类 | 指标 | 描述 |
|---|---|---|
| CPU | %User | 用户程序的CPU平均占用率 |
| %System | 操作系统的CPU平均占用率 | |
| %WIO | IO等待的平均比例 | |
| %Idle | 平均空闲率 | |
| 内存 | VM_PAGE_IN_BYTES | 虚拟内存中,从块设备swap区中读入的字节数 |
| VM_PAGE_OUT_BYTES | 虚拟内存中,从块设备swap区中读出的字节数 |
SQL指标解读
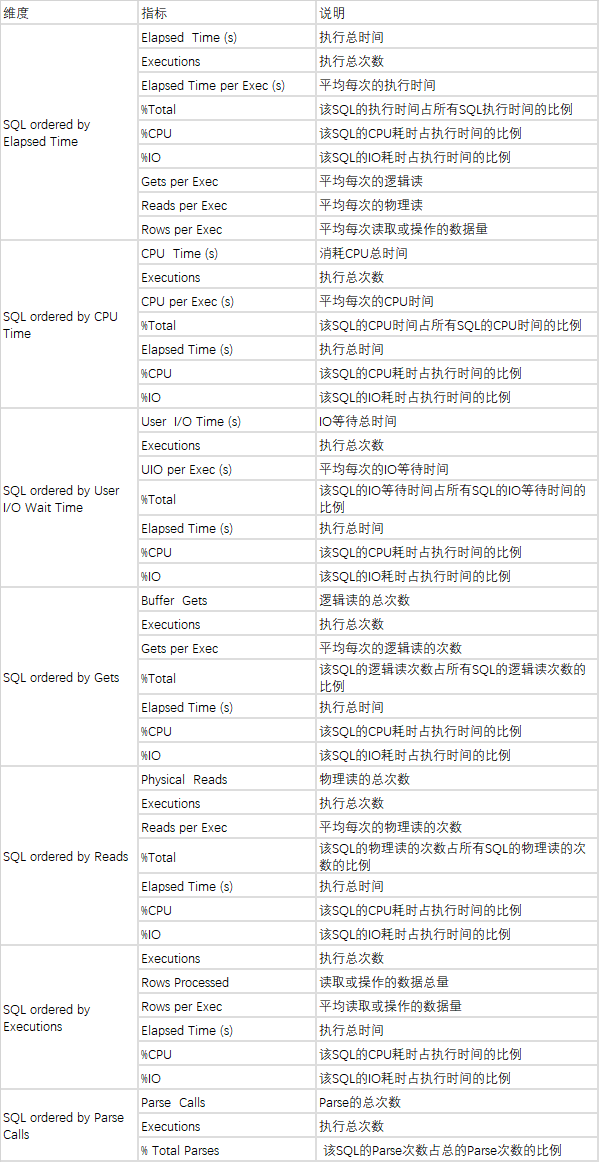
TopSQL的维度
| 维度 | 说明 | 作用 |
|---|---|---|
| SQL ordered by Elapsed Time | 按照SQL的执行时间排序 | 找出慢SQL |
| SQL ordered by CPU Time | 按照SQL的消耗的CPU时间排序 | 找出消耗CPU高的SQL |
| SQL ordered by User I/O Wait Time | 按照SQL的IO等待时间排序 | 找出IO等待时间长的SQL |
| SQL ordered by Gets | 按照SQL的逻辑读排序 | 分析SQL的逻辑读,一般逻辑读高的SQL消耗的CPU也较多,通过逻辑读数量也可以看出SQL的执行计划是否有明显的问题 |
| SQL ordered by Reads | 按照SQL的物理读排序 | 找出物理读多的SQL |
| SQL ordered by Executions | 按照SQL的执行次数排序 | 找出执行最频繁的SQL |
SQL的主要指标
Segment指标解读
Segment的维度
| 维度 | 说明 |
|---|---|
| Segments by Logical Reads | 按照逻辑读统计Top Segment |
| Segments by Physical Reads | 按照物理读统计Top Segment |
| Segments by Physical Writes | 按照物理写统计Top Segment |
| Segments by Row Lock Waits | 按照行等待统计Top Segment |
| Segments by ITL Waits | 按照ITL等待统计Top Segment |
| Segments by Buffer Busy Waits | 按照Buffer Busy Wait等待统计Top Segment |
| Segments by Segment Space | 按照空间增长等待统计Top Segment |
常见问题分析方法
常见问题分析方法
| 常见问题 | 分析方法 |
|---|---|
| CPU高 | 1.分析CPU高的SQL |
| 2.分析逻辑读高的SQL,尤其是Gets per Exec/Rows per Exec比值特别高的SQL | |
| 3.分析逻辑读最高的segment,重点分析对应的SQL | |
| IO高 | 1.分析物理读高的SQL |
| 2.分析物理读/写最高的segment,重点分析对应的SQL | |
| 3.分析是否有虚拟内存的换入换出 | |
| 锁等待 | 分析Segments by Row Lock Waits最高的对象 |
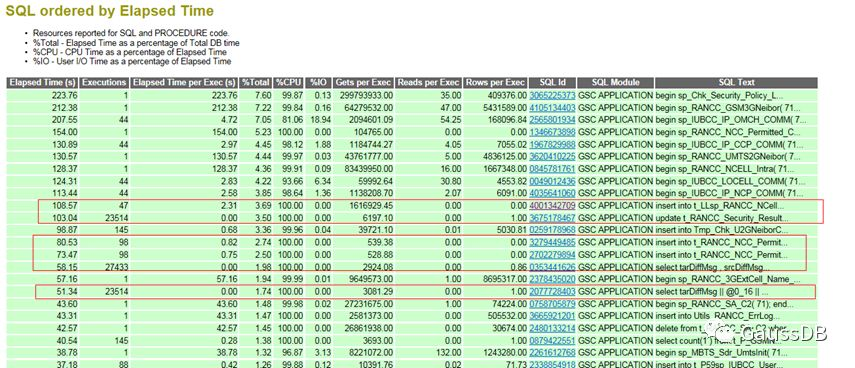
CPU高
重点要关注Rows per Exec很小而执行时间又很长的SQL,说明做了很多无用功,一般可以优化。Select count(*)除外,因为只会返回一条数据。
最后修改时间:2020-03-04 20:46:46
「喜欢这篇文章,您的关注和赞赏是给作者最好的鼓励」
关注作者
【版权声明】本文为墨天轮用户原创内容,转载时必须标注文章的来源(墨天轮),文章链接,文章作者等基本信息,否则作者和墨天轮有权追究责任。如果您发现墨天轮中有涉嫌抄袭或者侵权的内容,欢迎发送邮件至:contact@modb.pro进行举报,并提供相关证据,一经查实,墨天轮将立刻删除相关内容。
