




哈夫曼编码
哈夫曼编码是为了解决数据通信中数据传输的最优问题,为了让总码长度最短。
两种编码方式:
固定长度编码:每个字符用相等长度的二进制位表示。 可变长度编码:允许字符用不等长的二进制位表示,编码尽可能的短,且没有二义性,任何一个字符的编码不能是另一个字符编码的前缀。
哈夫曼编码就是可变长度编码。可变长编码的好处就是,根据字符出现的频率,将频率高的字符予以短编码,评率低的字符予以长编码,从而使总码长度变短,其到压缩的效果。
❝常用的JPEG图片就是使用哈夫曼编码压缩的。
任何一个字符的编码不能是另一个字符编码的前缀。这句话怎么理解呢?假如四个字符的编码如下:
| A | B | C | D |
|---|---|---|---|
| 0 | 1 | 10 | 11 |
假如此时一串编码是011011
,那么我们需要怎么翻译它呢,是ABCD,还是ADAD?所以可变长编码需要满足任何一个字符的编码不能是另一个字符编码的前缀。
假如ABCD的权值分别为1,2,3,4
,那么将ABCD这四个字符按照其权值构造一个哈夫曼树如下:
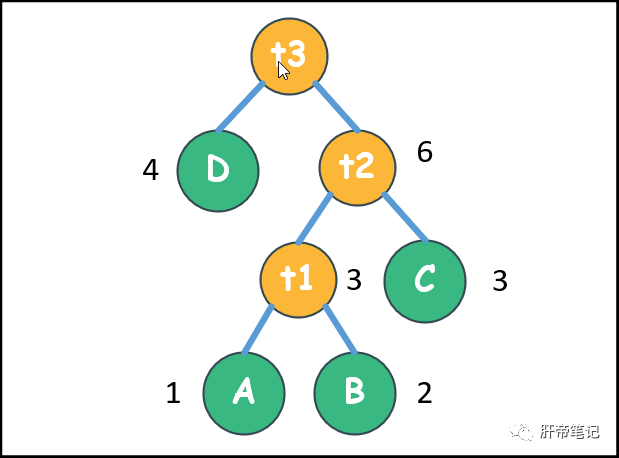
按照左子树路径为0,右子树路径为1的方式编码:
| A | B | C | D |
|---|---|---|---|
| 100 | 101 | 11 | 0 |
此时给一个字符串ABCD
,假如按照ASCII码来解析,就会有32位。若按照哈夫曼树得到的哈夫曼编码表转为二进制就是100101110
,总共才9位,而且按照编码表只能翻译成ABCD
,翻译不了其他的。
字符串压缩
❝引自韩顺平的教学视频,源代码有bug,部分修改
要求:给一串字符串,要求使用哈夫曼编码将其压缩成字节数组。
思路
首先将给定的字符串转换为byte数组。 将得到的byte数组按照出现的次数分类,转换为TreeNode节点对象存放到优先队列中。 根据优先队列构建一棵哈夫曼树,获得哈夫曼编码。 根据哈夫曼编码对字符串进行编码得到新的byte数组。
/**
* 使用哈夫曼编码对 字符串进行压缩
*/
public byte[] zip(byte[] bytes) {
// 1.初始化结点
PriorityQueue<TreeNode> queue = getNodeList(bytes);
// 2.创建哈夫曼树
buildHuffmanTree(queue);
// 3.获得哈夫曼编码
Map<Byte, String> codeTable = getCodeTable(root);
// 4.压缩
return zipToByteArray(bytes, codeTable);
}
结点对象和哈夫曼树编码对象
首先创建哈夫曼树的结点对象,实现Comparable接口是为了使用优先队列。
/**
* 二叉树的结点对象
*/
class TreeNode implements Comparable<TreeNode> {
/** 权值 */
private Integer weight;
/** 左子树指针 */
private TreeNode left;
/** 右子树指针 */
private TreeNode right;
/** 该结点存储的字节 */
private Byte data;
// 省略get set
// 省略构造方法
/** 按照权值升序 */
@Override
public int compareTo(TreeNode node) {
return this.weight - node.weight;
}
}
哈夫曼编码对象有两个成员变量,根结点和哈夫曼编码表。
public class HuffmanCode {
/**
* 根结点
*/
private TreeNode root;
/**
* 哈夫曼编码表
*/
private Map<Byte, String> codeTable = new HashMap<>();
}
初始化结点
将字符串对应的byte数组,按照字节出现的次数转换为TreeNode节点存放到优先队列中。
/**
* 获取每个字符和其权值(出现次数)的结点列表
*
* @param bytes 待转换的字节数组
*/
private PriorityQueue<TreeNode> getNodeList(byte[] bytes) {
if (bytes == null) {
return null;
}
PriorityQueue<TreeNode> queue = new PriorityQueue<>();
// 保存字符和出现次数的map
Map<Byte, Integer> map = new HashMap<>();
for (byte data : bytes) {
map.merge(data, 1, Integer::sum); // 添加到Map,JDK8的Map新方法
}
// 转换为结点
map.forEach((key, value) -> {
queue.offer(new TreeNode(value, key));
});
return queue;
}
构建哈夫曼树
根据上一步得到的优先队列构建哈夫曼树。
/**
* 构建哈夫曼树
*/
private void buildHuffmanTree(PriorityQueue<TreeNode> queue) {
if (queue == null) {
return;
}
// 优先队列中剩下一个结点,就是哈夫曼树的根结点
while (queue.size() > 1) {
// 每次拿最小的两个权重出来构建
TreeNode left = queue.poll();
TreeNode right = queue.poll();
// 构建父结点
TreeNode father = new TreeNode(null, left.weight + right.weight);
father.setLeft(left);
father.setRight(right);
// 将新的父结点放到优先队列中
queue.offer(father);
}
// 赋值给根结点
this.root = queue.poll();
}
哈夫曼编码
根据哈夫曼树得到哈夫曼编码,其实就是获得叶子结点到根结点的路径。
/**
* 生成哈夫曼编码
*/
public Map<Byte, String> getCodeTable(TreeNode root) {
if (root == null) {
return null;
}
getCodes(root, "", new StringBuilder());
return codeTable;
}
/**
* 生成哈夫曼编码列表
*
* @param node
* @param code 路径 左子结点是0 右子结点是1
* @param sb 存储
*/
private void getCodes(TreeNode node, String code, StringBuilder sb) {
if (node == null) {
return;
}
// 用一个新的sbb变量,是为了保存父结点的路径
StringBuilder sbb = new StringBuilder(sb);
sbb.append(code);
// 判断是否是叶子结点,假如是叶子结点,需要将这个结点和路径放到Map里
if (node.getLeft() == null && node.getRight() == null) {
// 是叶子结点,需要将这个结点和路径放到Map里
codeTable.put(node.getData(), sbb.toString());
} else {
// 不是叶子结点,递归左子树和右子树
getCodes(node.getLeft(), "0", sbb); // 左子树,路径0
getCodes(node.getRight(), "1", sbb); // 右子树,路径1
}
}
压缩字符串
根据哈夫曼编码表,将字符串转为新的byte数组。至此压缩字符串完毕。
/**
* 将字符串生成哈夫曼编码的列表 也就是byte[]数组
*/
private byte[] zipToByteArray(byte[] bytes, Map<Byte, String> codeTable) {
if (bytes == null) {
return null;
}
// 遍历原始bytes数组去查询 编码表
StringBuilder sb = new StringBuilder();
for (byte data : bytes) {
sb.append(codeTable.get(data));
}
// 将编码后的 字节码序列 转换为byte数组
// 创建返回byte[]数组
int len;
// 下面的if else等价 (sb.length() + 7 / 8 )
if (sb.length() % 8 == 0) {
len = sb.length() / 8;
} else {
len = sb.length() / 8 + 1;
}
// 为什么加1呢? 是为了保存最后一位的字节的 二进制位数
byte[] newBytes = new byte[len + 1];
// 将字节码每8位转为byte
int index = 0;
for (int i = 0; i < sb.length(); i += 8) {
String singleByte;
if (i + 8 < sb.length()) {
singleByte = sb.substring(i, i + 8);
} else {
singleByte = sb.substring(i);
}
newBytes[index++] = (byte) Integer.parseInt(singleByte, 2);
}
newBytes[index] = (byte)(sb.length() % 8) ; // 保存最后一位的字节的 二进制位数
return newBytes;
}
字符串解压
字符串的解压需要使用压缩前对应的哈夫曼编码表,因为哈夫曼编码是前缀码,所以按照编码表一个一个的解码即可。
需要注意的是针对最后一个byte字节的解码是一个特殊情况,给个例子,假如最后一位字节是4,可能对应的二进制形式是100
,或是0100
,或是00100
,这样我们不知道到底前面有几个0,所以在进行压缩字符串的时候我们把最后一位字节有几位保存下来了,解压的时候就可以成功解压了。
思路
首先将压缩后的字节数组转换为二进制形式的字符串。 构建一个解码表,将原始哈夫曼编码表的key变为value,value变为key。 按照解码表一个个的读取,获得源字节数组。
代码
/**
* 使用哈夫曼编码字符串进行解压缩
*
* @param codeTable 编码表
* @param huffmanBytes 哈夫曼编码得到的字节数组 也就是压缩后的字节数组
* @return 返回原始的字节数组
*/
public byte[] unZip(Map<Byte, String> codeTable, byte[] huffmanBytes) {
StringBuilder sb = new StringBuilder();
// 把压缩后的byte[]数组转换为压缩后的二进制字节码 字符串
for (int i = 0; i < huffmanBytes.length - 1; i++) {
byte abyte = huffmanBytes[i];
//对于byte中的元素,只要不是倒数第2个和倒数第一个就正常处理
if(i != huffmanBytes.length -2){
//正常处理
sb.append(byteToBitStr(abyte, 8));
}else{
sb.append(byteToBitStr(abyte, (int)huffmanBytes[huffmanBytes.length -1]));
}
}
// 将压缩后的二进制字节码 按照 编码表反向 获取其对应的key
// 首先将编码表的key-value转换, 也就是key->value, value->key
Map<String, Byte> newCodeTable = new HashMap<>();
codeTable.forEach((k, v) -> newCodeTable.put(v, k));
// 查表 将压缩后的字节码转换为对应的字符
List<Byte> list = new ArrayList<>();
for (int i = 0; i < sb.length(); ) {
int count = 1; // 指针,指向新的字符编码的第一个字节位置
Byte aByte = null;
while (true) {
String key = sb.substring(i, i + count);
aByte = newCodeTable.get(key);
if (aByte != null) {
break;
}
count ++;
}
list.add(aByte);
i += count; // 直接指向新的位置
}
byte[] bytes = new byte[list.size()];
for (int i = 0; i < bytes.length; i++) {
bytes[i] = list.get(i);
}
return bytes;
}
/**
* 将输入的byte转化为二进制,不一定是8位,位数取决于count
* @param b 待转换为二进制的字节
* @param count 待截取的位数
*/
private String byteToBitStr(byte b, int count) {
int temp = b;
temp |= 256;//与256按位或,在前面补齐0
String str = Integer.toBinaryString(temp);
return str.substring(str.length() - count);
}
压缩文件
我们前面压缩字符串是将字符串转换为字节进行压缩,我们只需要将文件转换为字节即可按照上面的步骤压缩即可。
/**
* 压缩文件
*
* @param srcFile 源文件路径
* @param dstFile 压缩文件存放路径
*/
public void zipFile(String srcFile, String dstFile) {
try (
InputStream is = new FileInputStream(srcFile);
FileOutputStream os = new FileOutputStream(dstFile); // 创建字节输出流
ObjectOutputStream oos = new ObjectOutputStream(os)
) {
// 创建一个byte数组,存放待压缩文件的字节
byte[] bytes = new byte[is.available()];
System.out.println("原始字节数组长度:" + bytes.length);
// 读取源文件数据
is.read(bytes);
// 对源文件进行哈夫曼编码的压缩
byte[] zipBytes = zip(bytes);
System.out.println("压缩字节数组长度:" + bytes.length);
// 使用对象输出流,将压缩后的字节数组和对应的哈夫曼编码表保存起来
// 哈夫曼编码表是为了后续解压缩使用的
oos.writeObject(zipBytes);
oos.writeObject(codeTable);
} catch (IOException e) {
System.out.println(e.getMessage());
}
}
解压文件
/**
* 解压文件
*
* @param srcFile 压缩源文件路径
* @param dstFile 解压存放路径
*/
public void unZipFile(String srcFile, String dstFile) {
try (
InputStream is = new FileInputStream(srcFile);
ObjectInputStream ois = new ObjectInputStream(is);
FileOutputStream os = new FileOutputStream(dstFile) // 创建字节输出流
) {
// 读取压缩源文件
byte[] bytes = (byte[]) ois.readObject();
// 读取压缩文件的哈夫曼编码
Map<Byte, String> codeTable = (Map<Byte, String>) ois.readObject();
// 解压缩文件
byte[] dstBytes = unZip(codeTable, bytes);
// 将解压的字节码存放到新的路径
os.write(dstBytes);
} catch (IOException | ClassNotFoundException e) {
System.out.println(e.getMessage());
}
}
