




LinkedList简介
LinkedList是一个双向链表,每个结点维护一个前向指针和一个后向指针。
LinkedList实现了队列的一些操作。
LinkedList继承关系
public class LinkedList<E>
extends AbstractSequentialList<E>
implements List<E>, Deque<E>, Cloneable, java.io.Serializable
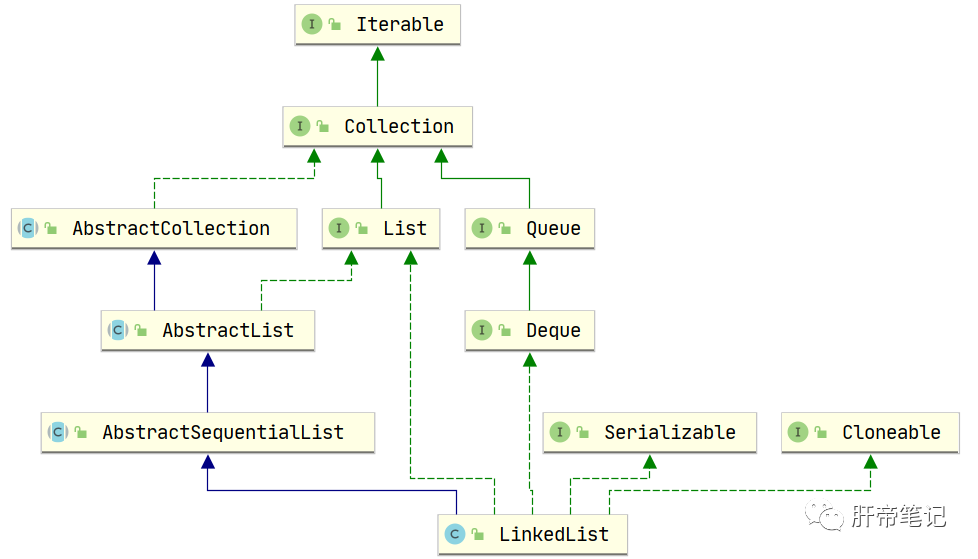
继承了抽象类AbstractSequentialList类,追根到底还是实现了Collection接口。 实现了List接口,则表明LinkedList具有数组的数据结构。 实现了Deque接口,则表明LinkedList具有队列的数据结构。 实现标记接口Cloneable,表明LinkedList可被克隆。实现这个接口后,然后在类中重写Object中的clone方法,然后通过类调用clone方法才能克隆成功,如果不实现这个接口,则会抛出CloneNotSupportedException(克隆不被支持)异常。 实现标记接口Serializable,可被序列化和反序列化。
结点对象
LinkedList是一个双向链表,我们在源码之前先要看一下它的结点对象Node,我们操作的对象都是这个Node。
private static class Node<E> {
E item;
Node<E> next;
Node<E> prev;
Node(Node<E> prev, E element, Node<E> next) {
this.item = element;
this.next = next;
this.prev = prev;
}
}
很明显,LinkedList是一个双向链表,从Node类的属性看
item就是数据域。 next指向下一个节点的指针。 prev指向上一个节点的指针。
其实从源码里面看,LinkedList还是一个循环链表。
成员变量
LinkedList的成员变量没有ArrayList那么多,就只有几个。
/**
* 链表的长度
*/
transient int size = 0;
/**
* 链表的第一个节点
*/
transient Node<E> first;
/**
* 链表的最后一个节点
*/
transient Node<E> last;
构造函数
空参构造函数。
public LinkedList() {
}
通过传入一个Collection集合,创建一个LinkedList,其实就是内部调用了一个addAll方法完成的。
public LinkedList(Collection<? extends E> c) {
this();
addAll(c);
}
成员方法
现在来说一下成员方法,我们都知道链表的数据结构是增删块,查询慢,我们在学习链表的时候也是着重看增删改方法的。
核心方法
LinkedList有很多添加元素的方法,但是很多都是套娃的,其实LinkedList核心的几个方法是linkBefore,linkFirst,linkLast,node,unlinkLast,unlinkFirst和unlink方法。可以说,只要了解这几个方法,LinkedList的源码基本上就看一半了。
/** 插入到指定元素前面 */
void linkBefore(E e, Node<E> succ);
/** 插入到链表头部 */
void linkFirst(E e);
/** 插入到链表尾部 */
void linkLast(E e);
/** 获取index位置的结点 */
Node<E> node(int index);
/** 删除链表尾部的结点 */
private E unlinkLast(Node<E> l);
/** 删除链表头部的结点 */
private E unlinkFirst(Node<E> f);
/** 删除指定结点 */
E unlink(Node<E> x)
① linkFirst方法
顾名思义,就是直接将结点插入到链表的头部,头插。
需要注意插入第一个元素时的情况。

private void linkFirst(E e) {
// 指针指向第一个结点
final Node<E> f = first;
// 根据传入的数据创建新结点
final Node<E> newNode = new Node<>(null, e, f);
// 将first直接赋值为新结点,就是插入到链表头部了
first = newNode;
if (f == null)
// 假如添加之前是空链表,也就是第一次添加元素,此时last指针也是指向新的结点
last = newNode;
else
// 假如之前不是空链表,将f指针指向的结点的前置指针域指向新的头部结点
f.prev = newNode;
size++;
modCount++;
}
② linkLast方法
将结点插入到链表的尾部,尾插。
需要注意插入第一个元素的情况
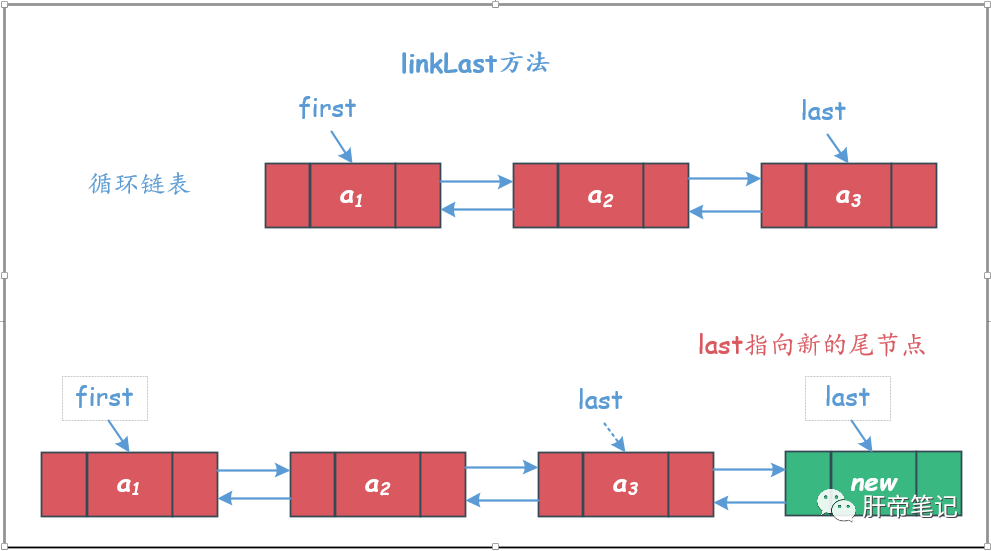
void linkLast(E e) {
// 指针指向最后一个结点
final Node<E> l = last;
// 此处将新节点的前向指针赋值为l,也就是指向了旧链表的最后一个结点
final Node<E> newNode = new Node<>(l, e, null);
// 将新节点赋值给last指针
last = newNode;
if (l == null)
// 假如添加之前是空链表,需要将first指针指向第一个结点
first = newNode;
else
// 假如之前不是空链表,将l指针指向的节点的后置指针域指向新的尾部节点
l.next = newNode;
size++;
modCount++;
}
③ linkBefore方法
就是将待插入的元素插入到指定节点的前面的位置。
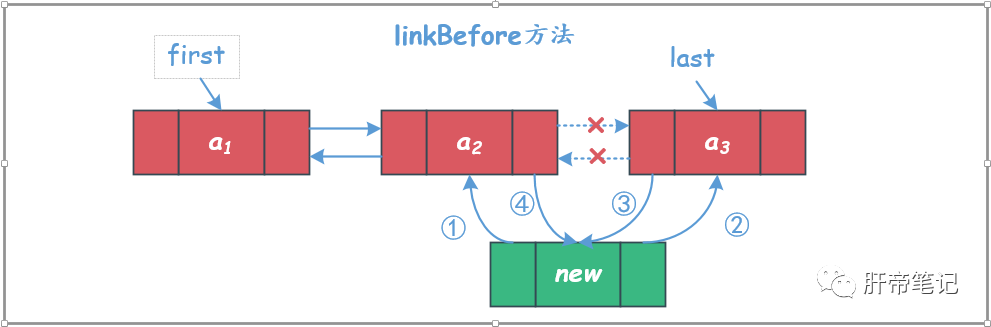
需要注意插入第一个元素的情况
/**
* @param e 待插入元素
* @param succ 待插入位置的旧结点,也就是要将新结点插入到此结点的前面
*/
void linkBefore(E e, Node<E> succ) {
// assert succ != null;
// 获得index位置节点的前驱节点,上一个节点
final Node<E> pred = succ.prev;
// 创建一个新节点
// 此时succ结点就变成了newNode的下一个节点去了
final Node<E> newNode = new Node<>(pred, e, succ);
// 新节点的地址赋值给之前在succ位置的节点的前驱指针域
succ.prev = newNode;
if (pred == null)
// 此时是要插入的位置是链表头部
first = newNode;
else
// 此时插入的位置不是链表头部,将上个节点的next域设为新节点地址
pred.next = newNode;
size++;
modCount++;
}
④ node方法
获取LinkedList链表指定位置的元素。此方法首先判断待查找的元素是在链表的前半部分还是后半部分,然后再进行遍历,这样可以节约一半的时间。
/**
* 找到index位置的节点
* 因为是双向链表,所以可以正向遍历和反向遍历
* 我们都知道链表遍历比较慢,所以可以折中遍历
* 在链表前半部分采用正向遍历,链表后半部分采用反向遍历
*/
Node<E> node(int index) {
// assert isElementIndex(index);
if (index < (size >> 1)) {
// 假如传入的索引位置在链表的后半部分,正向遍历
Node<E> x = first;
for (int i = 0; i < index; i++)
x = x.next;
return x;
} else {
// 查找的节点在链表的后半部分,反向遍历
Node<E> x = last;
for (int i = size - 1; i > index; i--)
x = x.prev;
return x;
}
}
⑤ unlinkLast方法
删除链表中最后一个元素。
需要注意删除的元素是链表中最后一个元素的情况。
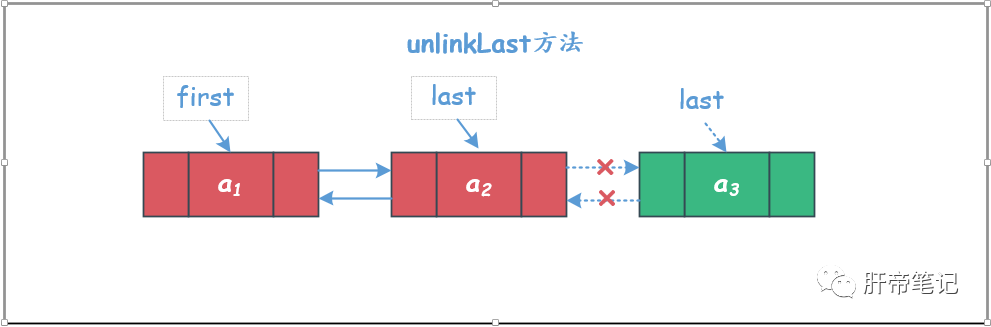
private E unlinkLast(Node<E> l) {
// assert l == last && l != null;
final E element = l.item;
final Node<E> prev = l.prev;
l.item = null;
l.prev = null; // help GC
// 将删除前的倒数第二个节点赋值给last指针
last = prev;
if (prev == null)
// 此时是删除之前链表只有一个节点,删除之后链表没节点了,当日first为null
first = null;
else
// 此时是删除之前的链表长度大于1,删除之后,得将新的尾节点的next指针置为null
prev.next = null;
size--;
modCount++;
return element; // 返回删除的节点的数据域
}
⑥ unlinkFirst方法
删除链表的第一个元素。
需要注意删除的元素是链表中最后一个元素的情况。
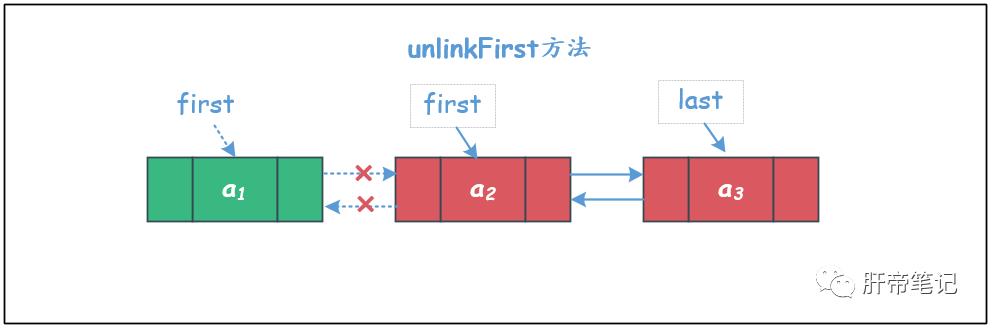
private E unlinkFirst(Node<E> f) {
// assert f == first && f != null;
final E element = f.item;
final Node<E> next = f.next;
f.item = null;
f.next = null; // help GC
// 将之前的第二个节点变为删除之后的第一个节点
first = next;
if (next == null)
// 此时是链表之前只有一个节点,这个节点被删除,当然last也为null了
last = null;
else
// 此时是链表在删除之前的节点数大于1,需要将删除前第二个节点的前置指针域置空
next.prev = null;
size--;
modCount++;
// 返回删除的节点的数据域
return element;
}
⑦ unlink方法
删除指定结点。
需要注意删除的元素是第一个元素或者是最后一个元素的情况。
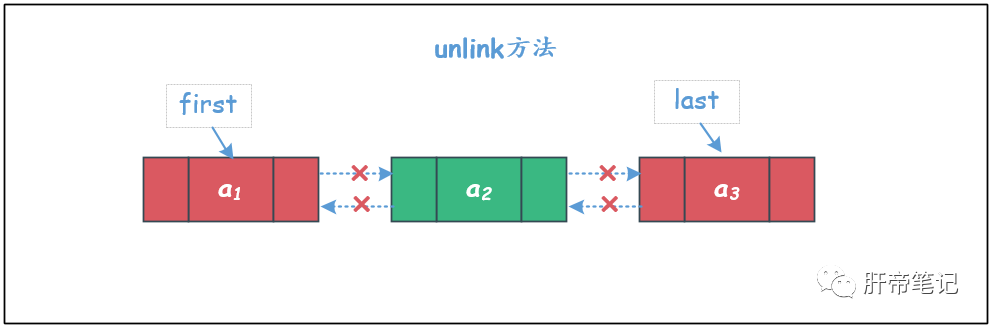
E unlink(Node<E> x) {
// assert x != null;
final E element = x.item;
final Node<E> next = x.next;
final Node<E> prev = x.prev;
if (prev == null) {
// 此时说明,待删除的元素是链表的第一个元素
first = next;
} else {
// 将待删除节点的前驱节点的next指针指向删除节点的next节点
prev.next = next;
// 断开
x.prev = null;
}
if (next == null) {
// 此时说明待删除的元素是链表的最后一个元素
last = prev;
} else {
// 将待删除节点的后继节点的prev指针指向删除节点的prev节点
next.prev = prev;
// 断开
x.next = null;
}
x.item = null; // 删除完成后,置空help GC
size--;
modCount++;
return element;
}
至于为什么搞这些个变种的添加方法,主要是为了模拟各个数据结构的,例如栈,队列,链表等。
增加方法
队列部分的添加方法
将元素插入到链表的头部,其实就是调用上面的linkFirst方法。
/**
* 插入元素到链表头部
*/
public void addFirst(E e) {
linkFirst(e);
}
将元素插入到链表的尾部,其实就是调用上面的linkLast方法。
/**
* 插入元素到链表尾部
*/
public void addLast(E e) {
linkLast(e);
}
链表部分的添加方法
/** 添加一个元素到链表尾部 */
public boolean add(E e);
/** 添加一个元素到链表的指定位置 */
public void add(int index, E element);
/** 添加Collection集合的元素到链表尾部 */
public boolean addAll(Collection<? extends E> c);
/** 添加Collection集合的元素到指定位置 */
public boolean addAll(int index, Collection<? extends E> c);
① 先看第一个add方法比较简单,直接调用linkLast方法,也就是说这个方法默认是添加到链表结尾。
public boolean add(E e) {
linkLast(e);
return true;
}
② 第二个add方法的作用是插入到链表的指定位置,第一个参数index代表的是需要插入到链表的哪一个位置。
public void add(int index, E element) {
// 判断索引的长度是否合法
checkPositionIndex(index);
if (index == size)
// 插入的位置是末尾,直接调用linkLast即可。
linkLast(element);
else
// 插入的位置不是末尾
linkBefore(element, node(index));
}
后面两个addAll方法其实调用的都是一个方法,传参不一样而已
③ 第一个addAll方法,默认是添加到链表的末尾。
public boolean addAll(Collection<? extends E> c) {
return addAll(size, c);
}
④ 第二个addAll方法是添加到链表的指定位置。
public boolean addAll(int index, Collection<? extends E> c) {
// 检查索引是否合法
checkPositionIndex(index);
Object[] a = c.toArray();
// 传入集合的长度
int numNew = a.length;
if (numNew == 0)
// 需要添加的集合的长度为0那还添加个毛
return false;
Node<E> pred, succ;
if (index == size) {
// 插入链表尾部
succ = null;
// 插入链表尾部,pred节点赋值为last节点地址
pred = last;
} else {
// 上面已经分析过node方法了,就是查找指定位置的节点
succ = node(index);
// pred节点赋值为第index节点的上一个节点的地址
pred = succ.prev;
}
for (Object o : a) {
@SuppressWarnings("unchecked") E e = (E) o;
// 创建新节点,将上面找到的前驱pred作为参数传入
Node<E> newNode = new Node<>(pred, e, null);
if (pred == null)
// pred为null,则说明插入的地方是链表头部
first = newNode;
else
pred.next = newNode;
pred = newNode; // pred后移
}
if (succ == null) {
// 此时是因为插入的位置是链表末尾
last = pred;
} else {
// 经过上面的一波循环,pred每循环一次都要后移一次
// 此时pred已经指向添加新集合的最后一个节点
pred.next = succ; // 将新集合的最后一个节点的next域赋为之前本来在index位置
succ.prev = pred;
}
size += numNew;
modCount++;
return true;
}
删除方法
删除链表的第一个元素,就是调用unlinkFirst方法。
/**
* 删除链表的第一个元素
*/
public E removeFirst() {
final Node<E> f = first;
if (f == null)
throw new NoSuchElementException();
return unlinkFirst(f);
}
删除链表的最后一个元素其实就是调用unlinkLast方法。
/**
* 删除链表的最后一个元素
*/
public E removeLast() {
final Node<E> l = last;
if (l == null)
throw new NoSuchElementException();
return unlinkLast(l);
}
根据对象删除元素
public boolean remove(Object o) {
if (o == null) { // 假如传入的对象为null,遍历链表
for (Node<E> x = first; x != null; x = x.next) {
if (x.item == null) {
unlink(x); // 假如找到了某个链表的元素为null,则调用方法删除元素
return true;
}
}
} else { // 假如传入的对象不为null,同样是遍历链表,使用equals方法判断是否相等
for (Node<E> x = first; x != null; x = x.next) {
if (o.equals(x.item)) {
unlink(x); // 调用删除方法
return true;
}
}
}
return false;
}
根据索引删除
首先调用node方法获取指定位置的结点,再使用unlink方法将该结点删除。
public E remove(int index) {
checkElementIndex(index); // 判断索引是否合法
// node方法 获取对应位置的node节点对象
// unlink方法上面有讲,移除节点
return unlink(node(index));
}
获取方法
这两个获取方法很简单,就是返回两个成员变量的数据域的值。
/**
* 返回链表中的第一个元素
*/
public E getFirst() {
final Node<E> f = first;
if (f == null)
throw new NoSuchElementException();
return f.item;
}
/**
* 返回链表中的最后一个元素
*/
public E getLast() {
final Node<E> l = last;
if (l == null)
throw new NoSuchElementException();
return l.item;
}
修改方法
public E set(int index, E element) {
// 判断索引是否合法
checkElementIndex(index);
// node方法获取对应位置的node节点对象
Node<E> x = node(index);
// 保存旧值
E oldVal = x.item;
// 赋新值
x.item = element;
// 返回旧值
return oldVal;
}
其他
双向链表的一些操作可以实现单向队列,双向队列,和栈的功能。
单向队列
/**
* 获取队首节点,但不移除元素
*/
public E peek() {
final Node<E> f = first;
return (f == null) ? null : f.item; // 链表为空则返回null
}
/**
* 获取队首节点,不移除元素,和peek区别是:链表为空则抛异常
*/
public E element() {
return getFirst();
}
public E getFirst() {
final Node<E> f = first;
if (f == null)
throw new NoSuchElementException();
return f.item;
}
/**
* 弹出队首节点
*/
public E poll() {
final Node<E> f = first;
return (f == null) ? null : unlinkFirst(f);
}
/**
* 移除队首节点,链表为空会抛异常
*/
public E remove() {
return removeFirst();
}
public E removeFirst() {
final Node<E> f = first;
if (f == null)
throw new NoSuchElementException();
return unlinkFirst(f);
}
/**
* 添加元素到队首
*/
public boolean offer(E e) {
return add(e);
}
public boolean add(E e) {
linkLast(e);
return true;
}
双向队列
/**
* 添加元素到队首
*/
public boolean offerFirst(E e) {
addFirst(e);
return true;
}
/**
* 添加元素到队尾
*/
public boolean offerLast(E e) {
addLast(e);
return true;
}
/**
* 获取队首的元素,不移除元素
*/
public E peekFirst() {
final Node<E> f = first;
return (f == null) ? null : f.item;
}
/**
* 获取队尾的元素,不移除元素
*/
public E peekLast() {
final Node<E> l = last;
return (l == null) ? null : l.item;
}
/**
* 获得队首的元素并移除元素
*/
public E pollFirst() {
final Node<E> f = first;
return (f == null) ? null : unlinkFirst(f);
}
/**
* 获得队尾的元素并移除元素
*/
public E pollLast() {
final Node<E> l = last;
return (l == null) ? null : unlinkLast(l);
}
栈
/**
* 压栈
*/
public void push(E e) {
addFirst(e);
}
/**
* 弹栈
*/
public E pop() {
return removeFirst();
}
总结
LinkedList是一个双向链表。 LinkedList可以实现单向队列、双向队列和栈的功能。 LinkedList无需指定初始容量,容量随着节点的增加而增加。因为LinkedList是基于链表操作的,不像ArrayList是基于数组的。 LinkedList是线程不安全的。
