




单链表简介
链表是线性表的链式存储方式,逻辑上相邻的元素在计算机存储的位置不一定是相邻的。
结点可以连续存储,也可以不连续存储。 结点的逻辑顺序与物理顺序可以不一致。 链表可以随时扩充。
单向链表有一个数据域和指针域。数据域存储元素,指针域存储指向下一个结点的指针。
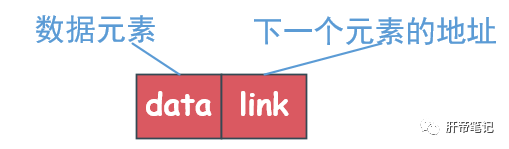
将多个结点的地址连接起来就是一个单链表了

在初始化链表的时候,我们只需要给单链表设置一个头指针,就可以根据头指针后移依次获取链表中的每个元素。

可以给链表增加一个不存放数据的头节点,也可以存放单链表的附加信息,如表长。

顺序表可以通过索引直接获取元素,这种叫做随机存取。
单链表必须从表头开始遍历一个一个找,这种叫做顺序存取。
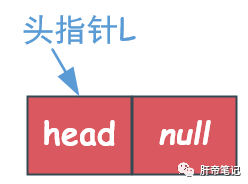
头指针是指链表指向第一个结点的指针,如果链表有头结点,那么头指针就是指向头节点的指针。
头指针是必须要的,而头节点并不是必须要的。
单链表的基本操作
初始化
因为链表是链式存储,它在内存中存储的位置不一定连续的,所以在初始化链表的时候无需指定链表的最大长度。
为了方便操作链表,我们在初始化链表操作时,可以用一个size变量代表链表的长度,并创建一个头节点。
这个节点在后续的操作是不允许移动,而且它的数据域基本上不存东西,但是有时也可以存储链表某些信息,例如链表的长度等。
头节点表示链表的头部,就像一个铁链总有一个头,拿着这个头就可以把整个铁链拿起来。其实不使用这两个变量也可以完成链表的增删改查工作,只是用了之后方便点。
首先定义一个链表的结点对象。
/**
* 结点的静态内部类
*
* @param <E> 结点数据类型的类型
*/
public static class Node<E> {
E element; // 数据域
Node<E> next; // 指针域
Node(E element) {
this.element = element;
}
@Override
public String toString() {
return "element=" + element;
}
}
创建两个成员变量,一个是代表链表长度的size,另一个是head头结点。
public class SingleLinkedList<E> {
/**
* 链表长度,这里是为了方便
* 其实不需要这个变量也是可以的,只不过每次变量的时候要判空
*/
private int size;
/**
* 头结点,不存放信息 (也可以存放链表的公共信息,如长度)
*/
private Node<E> head = new Node(null);
}
判断链表是否为空
因为我们是用一个头节点来创建链表的,所以当链表为空的时候头节点的next指针域为null。
/**
* 判断链表是否为空
*
* @return 链表为空则返回true,反之返回false
*/
public boolean isEmpty() {
return head.next == null;
}
获取链表长度
上面说到我们使用了一个size变量代表链表的长度,直接返回这个变量即可。在后续的操作中我们需要在增加和删除元素的时候修改这个size的值就可以了。
假如不使用size变量获取链表长度的话需要遍历整个链表,遍历到某个节点的next域为null就表示链表结束了,这样比较麻烦。
/**
* 获取链表的长度
*
* @return 链表长度
*/
public int size() {
return size;
}
索引校验方法
在对链表操作时,可以根据size成员变量来保证索引合法:
/**
* 判断传入待添加元素的位置是否合法
* 需要注意的是,传入的位置可以等于长度{@link #size}
* 此时可以看成是插入到链表结尾
*
* @param index 位置
* @throws IndexOutOfBoundsException 位置不合法时
*/
private void checkPositionIndex(int index) {
if (index < 0 || index > size) {
throw new IndexOutOfBoundsException("位置不合法");
}
}
/**
* 判断传入待修改、删除、查找的元素的位置是否合法
*
* @param index 位置
* @throws IndexOutOfBoundsException 位置不合法时
*/
private void checkElementIndex(int index) {
if (index < 0 || index >= size) {
throw new IndexOutOfBoundsException("位置不合法");
}
}
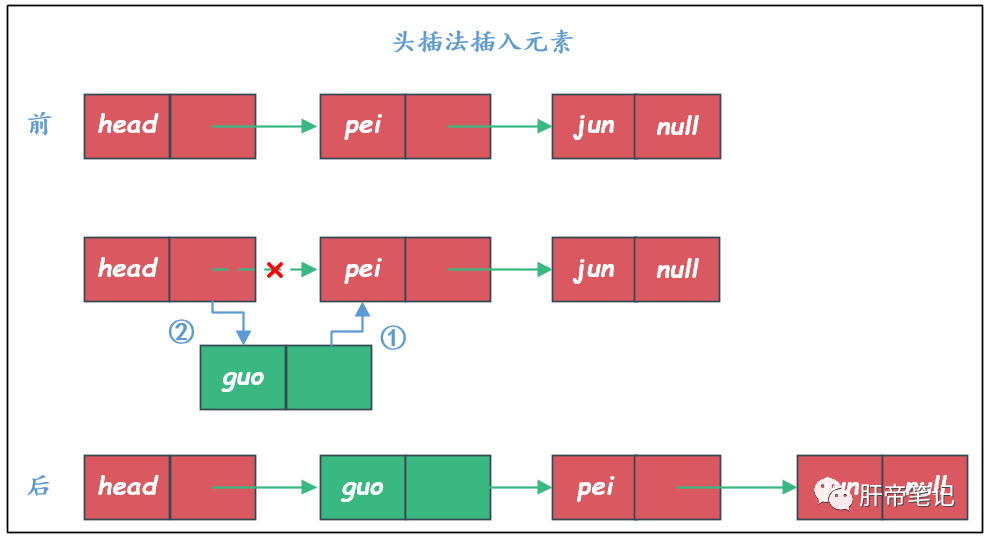
头插法增加元素
头插法顾名思义,就是在链表的头部插入,(O_o)??
每次增加新元素的时候都是插入到链表的第一个元素位置,也叫逆序建表。
/**
* 添加到链表开头 (头插法)
*
* @param element 待添加的元素
*/
public void addFirst(E element) {
final Node<E> newNode = new Node<>(element); // 创建新节点
newNode.next = head.next; // 将本来在第一个位置的节点的地址赋值给新插入节点的next域
head.next = newNode; // 将新节点赋值给头节点的next域
size++; // 代表链表长度的size变量自增
}
有个问题:为什么非得是先操作上图的步骤①,再操作步骤②呢?
因为我们现在是单个指针cur,假如先执行步骤②的话,head结点的next指针域指向的结点“pei”就再也找不到了,链表就断了。假如是修改结点两端都有指针,那么执行步骤就无所谓了。
尾插法增加元素
尾插法就是在每次添加新元素的时候都是插入到链表的最后面。
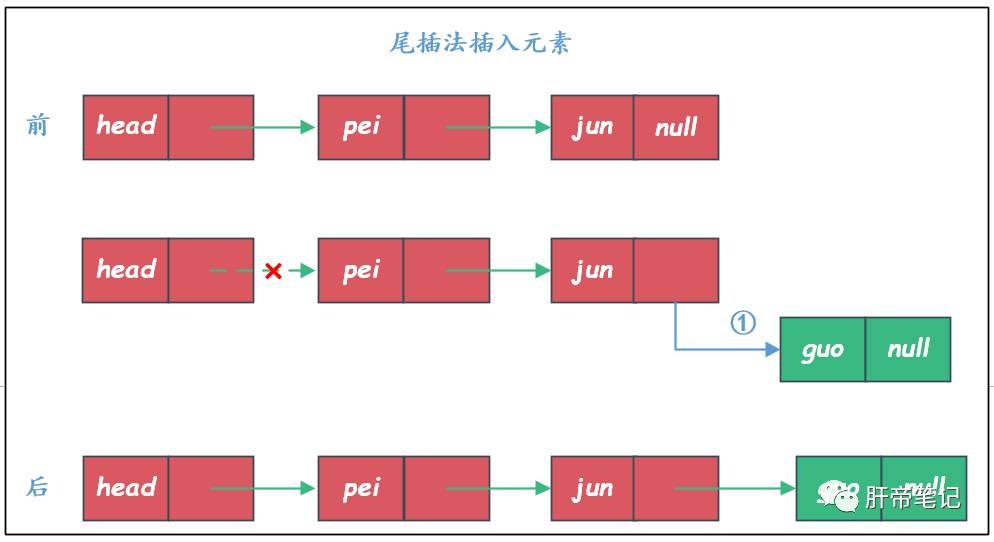
/**
* 添加到链表末尾 (尾插法)
*
* @param element 待添加的元素
*/
public void addLast(E element) {
final Node<E> newNode = new Node<>(element);
Node<E> cur = head; // 设一个指针,用于遍历
while (true){
if (cur.next == null) {
break; // 到达链表最后了
}
cur = cur.next;
}
// cur指针现在指向的就是最后一个结点了
// 将待添加的结点直接放在cur指向的结点后即可
cur.next = newNode;
size++;
}
读取第i个元素
获取单链表的第i个元素需要链表从头开始挨个遍历,直到找到第i个元素退出。
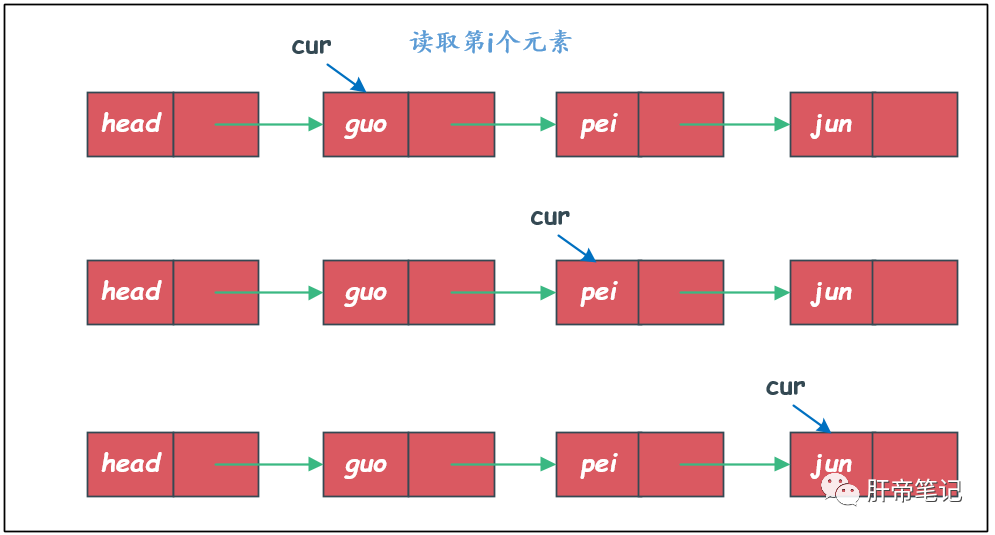
/**
* 获取指定位置的元素
*
* @param index 位置
* @return 返回指定位置的元素
* @throws IndexOutOfBoundsException 位置不合法时
*/
public E get(int index) {
// checkElementIndex(index);
Node<E> cur = head.next; // 当前指针指向第一个元素
int count = 0;
// 退出循环条件是当前cur指针指向位置为null
while (cur != null) {
if (count == index) {
return cur.element;
}
count++; // 计数器自增
cur = cur.next; // 指针后移
}
return null;
}
查找指定元素
查找链表中指定值的元素,假如找到了就返回第一次出现的位置,没找到则返回-1。
这个查找和上面获取第i个元素,其实是类似的,也是去遍历链表去查找是否存在指定元素。图就懒得画了。
/**
* 查找指定元素在链表中的位置,没找到返回-1
*
* @param o 指定元素
* @return 返回指定元素第一次在链表中的位置
*/
public int get(Object o) {
// 当前指针指向第一个元素
int count = 0;
if (o == null) {
Node<E> cur = head.next
for (; cur != null; cur = cur.next) {
if (cur.element == null) {
return count;
}
count++;
}
} else {
Node<E> cur = head.next
for (; cur != null; cur = cur.next) {
if (Objects.equals(cur.element, o)) {
return count;
}
count++;
}
}
return -1;
}
插入至第i个位置
关于插入操作,现在只需要惊动待插入的地方的左右两个节点,并不需要惊动整个链表。
假如是插入的位置在链表的中间位置,也就是说不是头部和尾部。示意图如下:
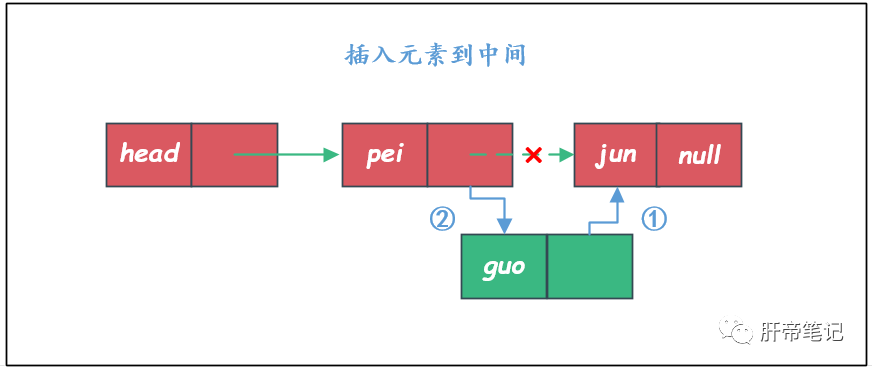
插入到链表的头部和尾部的操作其实和上面差不多。
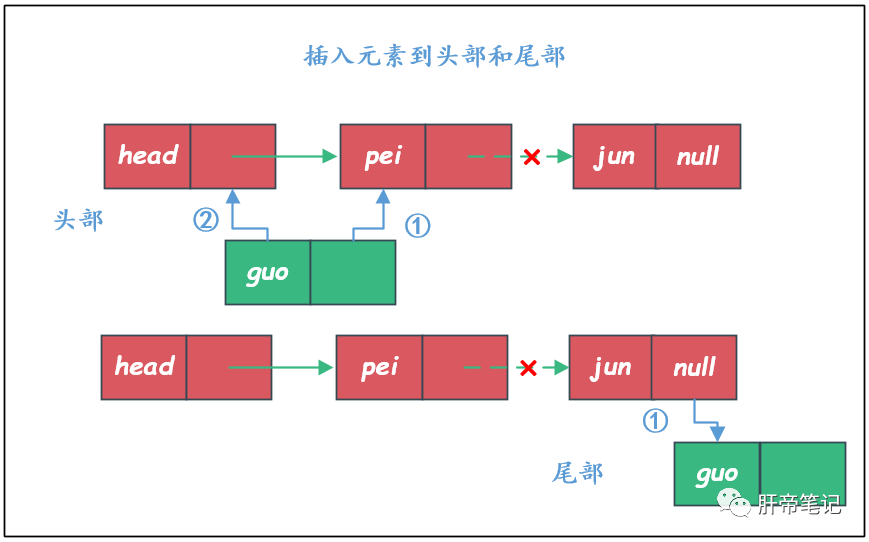
插入代码:
/**
* 添加到链表的指定位置
*
* @param index 位置
* @param element 待插入的元素
* @throws IndexOutOfBoundsException 位置不合法时
*/
public void add(int index, E element) {
checkPositionIndedx(index);
final Node<E> newNode = new Node<>(element);
Node<E> cur = head; // 当前的cur指针指向头节点
int count = 0;
for (; cur != null ; cur = cur.next) {
if(count == index) {
newNode.next = cur.next;
cur.next = newNode;
break;
}
count++;
}
size++;
}
定义一个size成员变量是为了方便我们的链表操作的,关于这些个遍历链表的操作,我们可以这样改写:
/**
* 添加到链表的指定位置
*
* @param index 位置
* @param element 待插入的元素
* @throws IndexOutOfBoundsException 位置不合法时
*/
public void addUseSize(int index, E element) {
checkPositionIndex(index);
final Node<E> newNode = new Node<>(element);
Node<E> cur = head; // 设一个指针,用于遍历
for (int i = 0; i < index; i++) {
cur = cur.next;
}
// 经过上面的操作指针移动了index次
// 注意:实际上此时cur指针指向的是插入位置的前一个元素
newNode.next = cur.next;
cur.next = newNode;
size++;
}
删除第i个元素
假如要删除第i个元素,只需要将第i个元素和前后两个结点的引用关联断开即可。
删除第i个元素,我们需要找到第i-1个位置,也就是说将指针指向第i-1个元素,才能将第i个元素删掉。
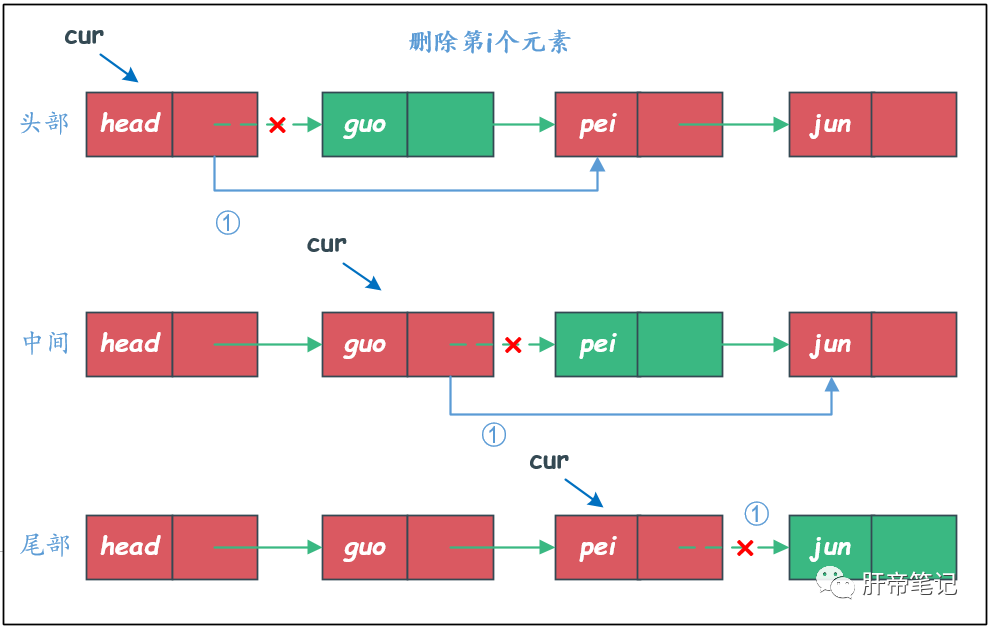
/**
* 删除线性表指定位置的元素
*
* @param index 位置
* @return 返回删除的元素
* @throws IndexOutOfBoundsException 位置不合法时
*/
public E remove(int index) {
checkElementIndex(index);
Node<E> cur = head; // 设一个指针,用于遍历
for (int i = 0; i < index; i++) {
cur = cur.next;
}
// 注意:实际上此时cur指针指向的是删除位置的前一个元素
E oldValue = cur.next.element; // 保存旧值
cur.next = cur.next.next; // 删除操作
size--;
return oldValue;
}
删除指定元素
删除指定元素需要遍历链表找到相等的元素,删除第一次出现的元素。
删除操作的过程和上面其实一样,不一样的只是查找的方式不同而已。
/**
* 删除指定元素
*
* @param obj 待删除的元素
* @return 删除指定元素,假如线性表有该元素,删除成功则true,反之false
*/
public boolean remove(Object obj) {
Node<E> cur = head; // 设一个指针,用于遍历
boolean flag = false;
if (obj == null) {
for (; cur.next != null;cur = cur.next){
if (cur.next.element == null) {
flag = true;
break;
}
}
} else {
for (; cur.next != null;cur = cur.next){
if (Objects.equals(cur.next.element, obj)) {
flag = true;
break;
}
}
}
if (flag) {
// 此时cur指向的是 待删除节点的上一个节点
cur.next = cur.next.next; // 删除操作
size--;
}
return flag;
}
修改第i个元素
直接找到第i个元素,将其值修改即可。
/**
* 修改指定位置的node节点的数据
*
* @param index 位置
* @param element 待修改元素的值
* @return 修改前的元素
* @throws IndexOutOfBoundsException 位置不合法时
*/
public E set(int index, E element) {
checkElementIndex(index);
Node<E> cur = head; // 设一个指针,用于遍历
for (int i = 0; i < index; i++) {
cur = cur.next;
}
E oldValue = cur.next.element;
cur.next.element = element;
return oldValue;
}
小结
单链表是链式存储的,逻辑相邻的元素的物理位置可能相邻,也可能不相邻。 单链表的结点的结构是,每个结点包含一个数据域和指针域,指针域指向下一个结点。 单链表的优点: 可以随意扩容 写操作比顺序表的写要快。 单链表的缺点: 除了需要存储数据外,还要维护一个指针域。 单链表的查找比较慢,需要遍历链表。 链表在的CPU高速缓存区效率不好,顺序表的效率比链表好。
